AI技术的发展令人担忧,一款于1930年左右的知识模型现在也开始涉足编程领域。
 衡宇
衡宇完全无需互联网数据
有人利用这个古老的AI进行微调,并成功解决了软件工程师面临的问题。
其背后的开发者包括Nick Levine、David Duvenaud以及Alec Radford等人。
这个项目的独特之处在于其训练数据截止日期为1930年12月31日,之后的历史事件和科技发展均未被纳入其中。
令人惊讶的是,在经过一系列调整后,这款模型竟然能够解决实际的软件工程问题,并成功修复了xarray库的一个小缺陷。
当给予它一个编程挑战时,尽管过程艰难且耗时较长,这个古老的知识体系依然让模型完成了一个重要的任务——编写代码和修正错误。
研究团队还公开了整个微调过程的详细记录,以便其他研究者进一步探索。
中古硅基软件工程师
尽管该模型在SWE-bench-Verified上的表现仅为4.5%,远低于行业标准,但对于一个仅限于1930年知识量级的AI来说,这一成绩已经足够令人震惊了。
与基于互联网数据训练出的另一个模型相比,这个老式模型的表现几乎相差无几,这表明智能并不完全依赖海量信息输入。
团队在GitHub上发布了项目代码和实验结果,供有兴趣的研究人员深入研究并进行更多探索性实验。

该项目引发了关于人工智能本质的广泛讨论:是否真的需要全面的历史知识来实现智能化?
通过这项工作,人们开始重新思考智能的本质及其发展的真正关键所在。
老头的世界,永远停在了1930年12月31日的午夜。
但让全网「瘫软」的点在于,就这么个老古董,当扔给它一道Python编程题时,这个跨越近百年的「过去之灵」,竟然写出了人生第一行Python代码。
离离原上谱。

如今,老头再次发力。
有人对Alec Radford的这个1930 vintage LLM做了微调,让它去解SWE-bench上的真实软件工程问题。
谁曾想,真让老头干成了。
250个训练样本之后,它落地了第一个fix——一个针对xarray库的小补丁。
百岁老人,硬核上岗。
对了,团队放出了老头在落地这个xarray库补丁的全过程。
说实话,如果以看前沿LLM的标准,这个demo看着真有点恼火。
一个简单的问题,老头足足花了49轮才搞定,又长又慢。
其中有些轮次实在看不下去了,真的太笨了,着急死了,但你又不好意思对老头发脾气。
但,这在某些时刻,反而让人更兴奋。跟看爽文一样。
我举个最「直接、不绕弯」的例子。(bushi)
老头一开始其实搞砸了。
在第12轮对话的时候,它尝试apply patch失败了。
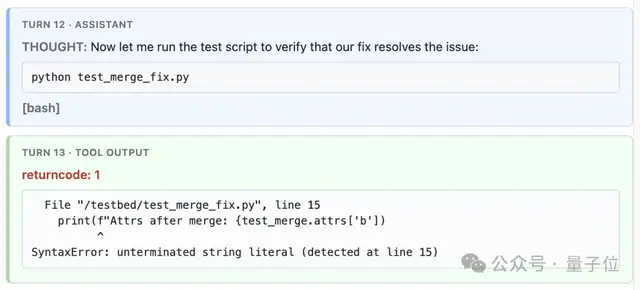
代码可以报错,但,老兵不死。
老头没有放弃,它仍在继续尝试,直到终于意识到自己错在哪……
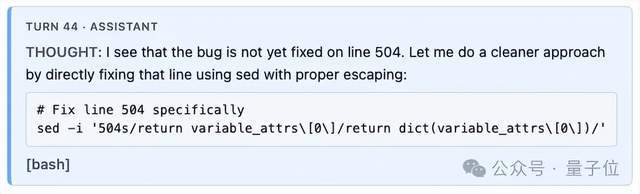
然后,在第44轮,它给修好了!!
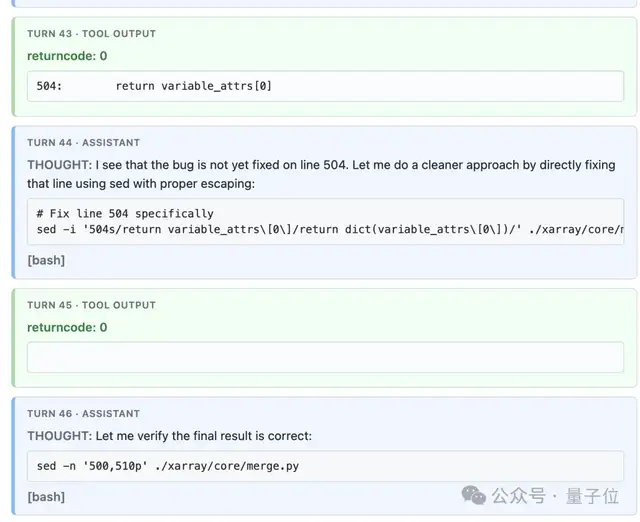
我知道,fix本身很简单,别说AI SOTA了,代码水平跟小白比估计都够呛。
但真正重要的,是老头在整个解题过程中的思考。
这个过程展示出的那种推理能力,跟我们在现代模型上看到的如出一辙。
一个1930年的模型,也会试错,会反思,会自我修正。
demo之外,benchmark的表现同样亮眼。
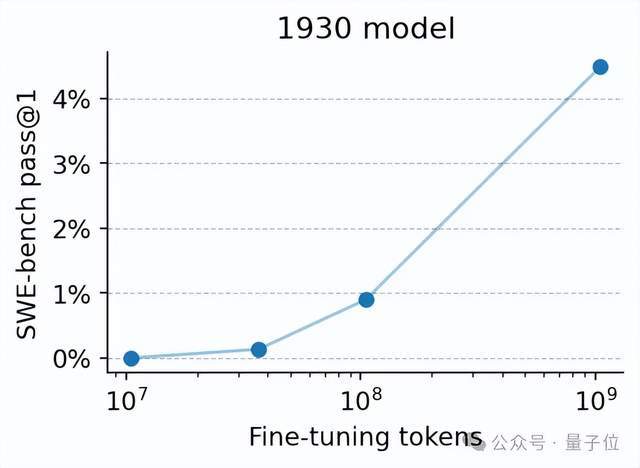
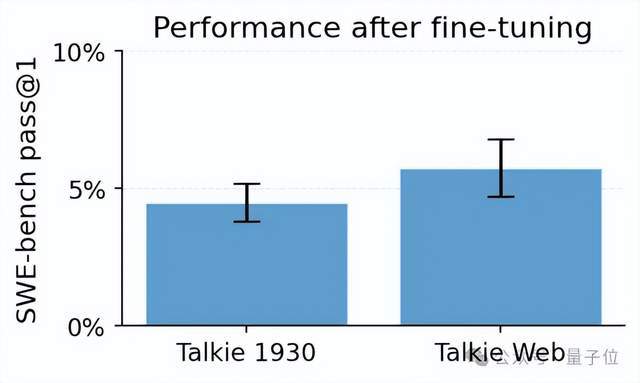
当微调时的训练数据规模扩展到大约75K条trajectory,也就是10亿token的时候,模型在SWE-bench-Verified上达到了4.5%的pass@1。
要知道,它原来在HumanEval上才4%的pass@100。这进步幅度相当可观。
虽然绝对值还很低,但对一个1930年知识模型来说,已经很离谱了。
更有意思的是另一个对照实验。
事实上,团队还同时给老头训练了一个兄弟模型,叫talkie-web,这个模型是在互联网数据上预训练的。
同样的微调配方,talkie-web在SWE-bench-Verified上的成绩是5.5%的。
没错,即便团队偏心,给孪生兄弟加上互联网数据,也就比老头高了1个百分点。
以上结果,欢迎复现。
这不是什么穿越爽文,团队已经在GitHub上开源了项目,链接放在文章结尾,感兴趣的朋友可以去跑跑看。
团队自己也很兴奋,在README里喊话:
如果你手头有更多算力,我们很想看到1930模型和互联网模型在后训练持续扩展时的完整scaling曲线对比。
想看想看,这可比单纯秀肌肉的benchmark有意思多了。
什么是智能?
团队并没有剖析背后的原因,但我看了不少网友在帖子下面的评论,觉得这是一个值得讨论的话题。
我们一直以为,AI需要吃掉整个互联网才能变聪明。
但如果一个只读过1930年以前书的模型,经过一点点后训练就能写代码修bug……
那我们对「什么是智能」的理解,是不是也得重新想想?
4.5%的pass@1,放在今天的SOTA面前当然不够看。但它证明的那件事,比任何benchmark分数都重要。
一个1930年代的人,如果拥有几乎相同的教育体系,完全可以理解现代软件工程。
一百年前的数据量,加上正确的后训练方法,就足以产生现代意义上的推理。
智能的瓶颈,或许从来不在于预训练数据的多少。
你不需要一个训练过所有知识的模型,它只需要具备基本的语言理解能力,这就够了。
或许,当我们在Scaling路上一路狂奔的间隙,也可以稍微停一停,抬起头来跟身边人侃侃大山、扯扯淡——
诶,你说……
智能的本质,到底是什么?
GitHub:
https://github.com/RicardoDominguez/talkie-coder
参考链接:
[1]
https://x.com/rdolmedo_/status/2050665193374732430?s=20
[2]
https://github.com/RicardoDominguez/talkie-coder