 本文由智东西编辑团队王涵和冰倩合作完成。
本文由智东西编辑团队王涵和冰倩合作完成。
智东西于3月24日发布消息,京东技术团队宣布推出京东云“龙虾天团”系列产品。这些产品基于JoyAI大模型开发,包括轻量云主机一键部署、一体机、云上SaaS版本,以及CodingPlan大模型套餐包。
据京东团队提供的数据,自“龙虾”系列产品上线以来,过去一周内token调用量环比增长了455%。

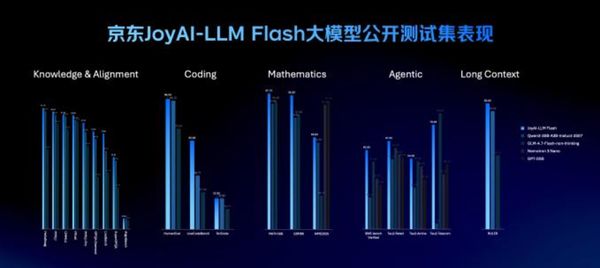
此外,京东首次公开了其通用基础大模型JoyAI-LLM Flash的Instruct版本,该模型参数量为48B,激活3B参数,其性能测试结果超过了GLM-4.7 Flash(non-thinking)等同规模模型。
开源地址:
数字人领域,京东自主研发的JoyAvatar数字人视频生成框架近日正式发布,该框架运用了多项创新技术,解决了文本控制弱、多模态控制信号冲突以及长视频生成能力不足等问题,性能超过Omnihuman-1.5和KlingAvatar 2.0等国际领先模型。
在具身智能方面,京东宣布计划在未来一年内收集500万小时的人类真实场景视频数据,两年内收集超过1000万小时的优质数据,并同步收集机器人本体数据100万小时,以构建全球规模最大、场景最全的具身智能数据采集中心。
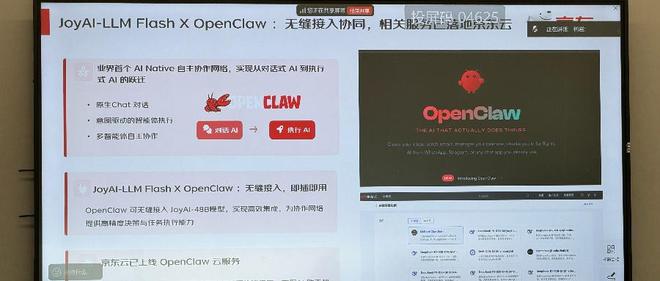
目前,京东云在轻量云主机上预装了OpenClaw应用镜像,支持快速部署,用户无需手动搭建运行环境。京东团队表示,最新的数据显示,京东云OpenClaw云服务用户规模单周增长超过300%,且云端部署需求持续上升。

针对中大型企业需求,京东云还推出了OpenClaw一体机,具备零代码开箱即用、原生开源生态融合、官方持续更新三大优势。
京东云OpenClaw一体机目前有三个硬件规格,包括标准版型号1、标准版型号2和个人版,分别适用于不同的使用场景和团队规模。
JoyAI-LLM Flash大模型采用48B参数量,激活3B参数,其公开测试结果显示,该模型的性能优于同等规模模型,如GLM-4.7 Flash(non-thinking)。

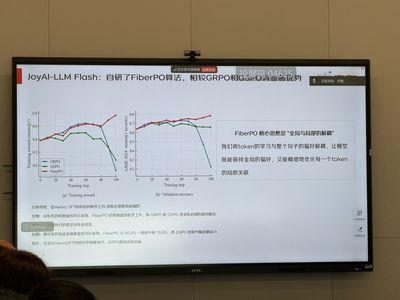
该模型通过引入几何流形学中的“纤维丛”数学工具,提出了创新的强化学习技术FiberPO。
在保持3B激活参数不变的情况下,该模型通过动态稀疏路由实现了更高的计算效率,其稀疏比例优于GLM-4.7-Flash等模型。
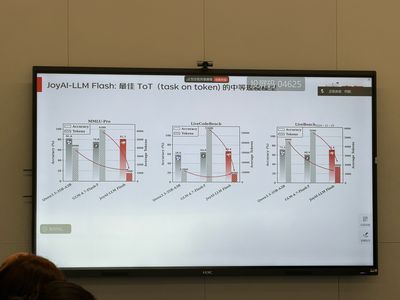
- 依托稀疏优化+训推协同技术,JoyAI-LLM Flash在辅助代码开发时响应速度超越同级别小参数量模型,让程序员可以实现“边写边调”。
- 该模型基于预训练+多轮微调,对编程语法、多语言适配(React/Vue等)、代码逻辑的理解精准,生成的代码可直接复用。
- JoyAI-LLM Flash智能体可以低成本快速适配用户复杂业务场景。京东JoyAI大模型技术已在超过2000多个场景中应用,融入京东“超级供应链”。京东团队透露,京东内部运行的智能体数量已超过5万个。
JoyAvatar数字人视频生成框架通过音频和文本两个专属教师模型,在分布匹配蒸馏(DMD)后训练框架中实现了“音视频同步能力”和“文本控制能力”的分离式监督、融合式学习,无需新增训练数据即可将通用视频大模型的文本可控性迁移到数字人模型中。
该框架根据视频生成的去噪时间步动态调整文本和音频的无分类器指导尺度,生成早期优先根据文本控制信号确定动作框架,后期则优先根据音频控制信号确保唇形同步。
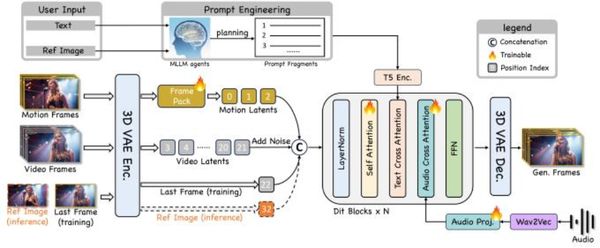
通过Frame pack历史帧编码模块+伪最后一帧策略,该框架构建了专属长视频生成模型结构,支持30秒以上长视频生成,全程保持身份稳定,动作流畅。
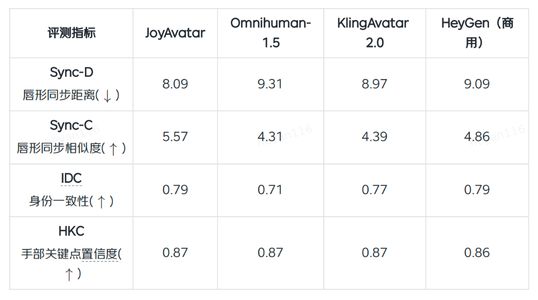
JoyAvatar数字人框架在唇形同步、身份稳定与动作自然度等指标上达到商用级水准,优于商用模型HeyGen。
JoyAvatar的应用场景广泛,包括电商服务、智能客服、内容创作等,如数字人主播、智能客服、京东云生态、影视动画、线上会议、教育科普、文旅文创等。
京东推出了JoyInside,为硬件终端提供智能化适配能力,支持拟人化交互与多人群适配。
2026年初,该能力新增社交玩法并升级语音合成技术,实现设备互通,扩展至八大方言识别交互。截至目前,JoyInside已接入近百家家电家居品牌、超40家机器人及AI玩具厂商。
京东还推出了“JoyInside开发平台”,提供低代码可扩展环境及“搭建环境+AI能力+硬件模组+产业资源”的一站式解决方案,适用于大众、设计师、开发者和厂商。
京东依托累计超过1700亿元的技术投入,已经形成了从京东云算力底座、JoyAI系列基础模型,到智能体、数字人、具身智能的完整技术矩阵。
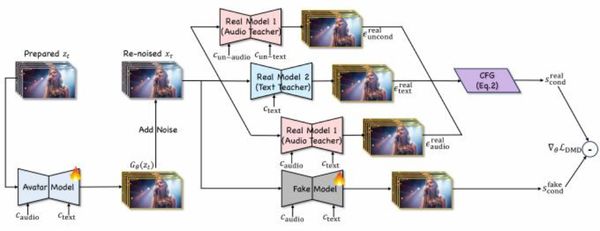
这一立体化布局不仅推动了京东内部海量业务场景的智能化升级,更通过开放生态加速了AI技术的普及应用。
通过Frame pack历史帧编码模块+伪最后一帧策略, 该框架构建专属长视频生成模型结构,突破传统数字人模型 “生成时长短、帧闪烁、身份漂移” 的技术限制,支持30秒以上长视频生成,并且可以全程保持身份稳定、动作流畅。
在客观量化指标评测中,JoyAvatar在唇形同步、身份稳定与动作自然度上达到商用级水准。其中唇形同步相似度Sync-C达5.57,高于Omnihuman-1.5、KlingAvatar2.0及商用模型 HeyGen。JoyAvatar的手部关键点置信度HKC为0.87,保证了肢体动作的自然流畅。
JoyAvatar可快速落地电商服务、智能客服、内容创作等核心场景:
- 京东内部场景:数字人主播(直播间复杂动作、多主播互动)、智能客服(多角色智能问答)、京东云生态(为客户提供数字人技术底座)等;
- 通用产业场景:影视动画(快速生成卡通人物 / 非人类主体视频)、线上会议(虚拟分身多轮对话)、教育科普(虚拟讲师复杂动作演示)、文旅文创(数字文旅形象定制)等场景。
京东推出的JoyInside面向硬件终端提供智能化适配能力,支持拟人化交互与多人群适配。
2026年初,该能力新增社交玩法并升级语音合成技术,与京东京造联动搭建跨品类智能硬件互联体系,实现设备互通,并扩展至八大方言识别交互。截至目前,JoyInside已接入近百家家电家居品牌、超40家机器人及AI玩具厂商。
此外,京东还推出“JoyInside开发平台”,提供低代码可扩展环境及“搭建环境+AI能力+硬件模组+产业资源”的一站式解决方案:
- 面向大众与设计师:提供可视化工具与即插即用模组;
- 面向开发者:支持定制与外部Agent集成;
- 面向厂商:通过便捷API助力老硬件低成本智能化升级,并对接京东零售渠道与营销资源。
依托累计超1700亿元的技术投入,京东已形成从京东云算力底座、JoyAI系列基础模型,到智能体、数字人、附身智能的完整技术矩阵。
这一立体化布局,不仅推动京东内部海量业务场景的智能化升级,更以开放生态加速AI从技术突破走向普惠应用。