
新智元报道
机器人控制中的「数据困境」是业界长期关注的难题:要使机器人掌握精细操作,传统方法依赖大量人工标注的数据,这不仅耗资巨大,且耗时漫长。如何突破这一瓶颈?
大规模视频生成模型通过学习海量视频数据,已经隐含地理解了物理世界的运作规则:物体如何移动、力如何传递、空间关系如何演变。
这些知识与机器人操控所需的物理直觉高度契合。
关键在于:能否将视频模型中的物理先验知识应用到机器人控制中?
中山大学王广润教授提出了一种创新方法:不依赖海量动作数据,而是从视频生成模型中提取物理直觉。PAR(物理自回归模型)及其升级版PhysGen(从预训练视频模型中学习物理),两者共享同一「物理自回归」核心框架,并与英伟达今年2月发布的DreamDojo在核心理念上高度一致——当两条独立探索路径汇聚到同一方向,这可能表明某种基本规律正在被揭示。

PAR论文的发布日期是2025年8月13日。
PhysGen于2026年2月18日发布。
传统方法将「感知环境」和「执行动作」视为两个独立的任务。

PAR则采用相反的方式:将视频帧与机器人动作编码为同一「物理token」,使模型在同一自回归过程中,既预测「未来环境状态」,也同步输出「机器人动作」,这与人类「眼手协调」的直觉高度契合。
这样的设计使得动作不再被视为孤立的指令序列,而是与环境演化紧密相连的联合预测。
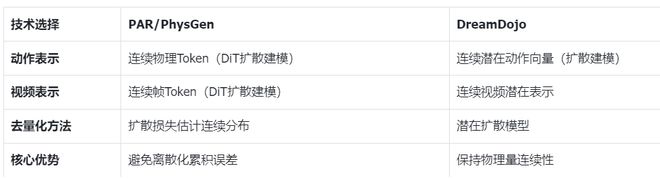
帧与动作都采用连续向量表达,避免离散化带来的精度损失。
帧与动作都采用连续向量表达,避免离散化带来的精度损失。
特殊的因果掩码设计让模型在「看到未来画面」后再决定当前动作。
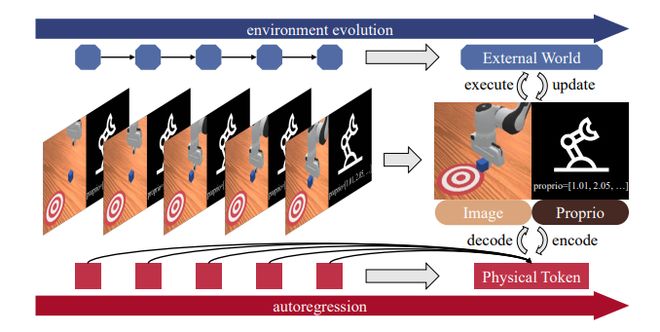
特殊的因果掩码设计让模型在「看到未来画面」后再决定当前动作。
三个技术要点
- 采用LLM的KV-Cache技术,实现实时控制。
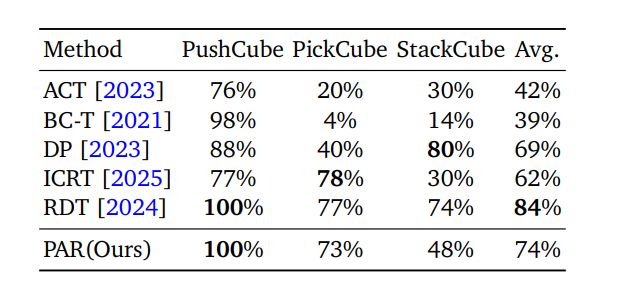
- 在ManiSkill基准测试中:
- PushCube任务达到了100%成功率。
效果如何?
在PickCube与StackCube任务上,表现同样优秀,接近或超越需要大规模动作预训练的方法。
- 图2展示了ManiSkill基准测试的成功率对比(零动作预训练,媲美SOTA)。
- PhysGen于2026年2月发布,是PAR路线的延续。它保留了PAR的核心架构(物理token、连续表示、因果掩码),并在此基础上进行了三项重要改进。
- ② 高效训练(LoRA微调)采用参数高效的方法微调大模型,训练成本显著降低——单张A100显卡,60小时内完成训练。
额外引入参数仅30M
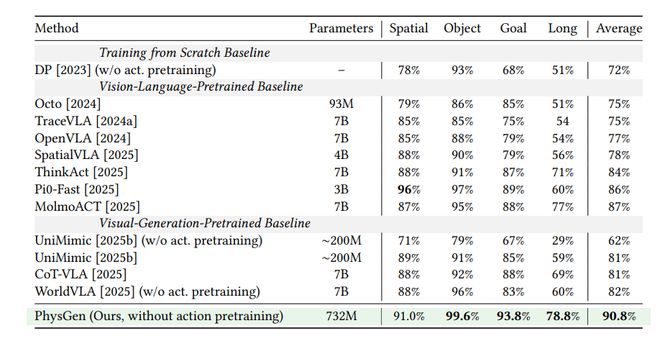
在LIBERO仿真基准测试中:
PhysGen
图3展示了732M参数、在零大规模动作预训练前提下,Physgen取得平均90.8%成功率。
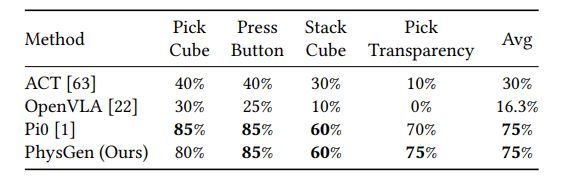
图4展示了真实机器人实验性能对比。
三项升级
在最考验物理感知的透明物体抓取任务中,PhysGen超越了需要大规模预训练的π0模型——这说明从视频中学到的物理直觉,在处理「视觉欺骗性强」的场景时更具优势。
与英伟达DreamDojo的深度同源
今年2月,英伟达发布了DreamDojo——一个基于大规模视频训练的通用机器人世界模型。对比PAR/PhysGen与DreamDojo,会发现两条路线在核心技术理念上惊人一致。
效果有多强?
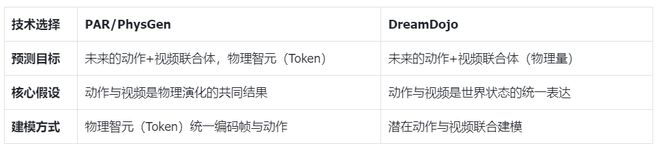
两个系统的本质目标完全一致:预测未来的「物理量」——也就是未来的动作和视频的联合体。
这个设计背后的哲学是:机器人操控不是「先看画面,再决定动作」的串行过程,而是「世界如何演化」与「机器人如何行动」的联合预测问题。动作和视频不是两个独立变量,而是物理世界演化的共同结果。
真实世界任务:
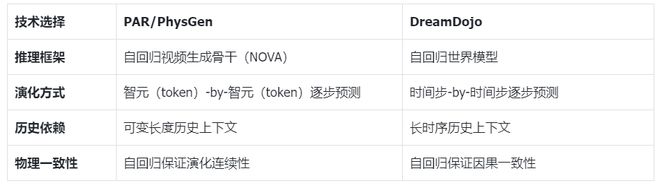
在如何预测这个「未来物理量」的问题上,两个系统不约而同地选择了自回归架构。
为什么是自回归?因为物理世界的演化是序列性、因果性的——当前时刻的状态决定下一时刻的状态,下一时刻又影响再下一时刻。自回归模型天然契合这种「逐步展开」的物理过程。
表达方法:连续空间建模
在如何表达「物理量」的问题上,两个系统都选择了连续表示,而非离散化。
这是一个关键决策:物理世界本质上是连续的(位置、速度、力都是连续量),离散化会引入量化误差,这些误差在长时序预测中会累积放大。连续表示则能保持物理量的原生精度。
训练方法:零动作预训练
架构共识:自回归建模
两个系统都验证了同一个重要结论:不需要大规模机器人动作数据预训练,就能实现强大的操控能力。
这背后的逻辑是:视频数据本身已经包含了丰富的物理先验(物体运动规律、力学关系、空间推理),这些先验可以直接迁移到机器人控制任务上。
中大团队的PAR在2025年8月公开,PhysGen在2026年3月公开,DreamDojo在2026年2月发布。
三者独立推进,却在四个核心决策上同步收敛:
① 预测目标:未来动作+视频联合体(物理量)② 架构选择:自回归逐步展开(契合物理因果)③ 表示方法:连续空间建模(避免离散化误差)④ 训练范式:零动作预训练
更重要的是,明确了世界模型的根本目的:不是生成视觉上美观的未来视频,而是生成对下一步物理动作有实质指导作用的物理预测。这个理念体现在物理token联合建模、因果掩码逆运动学、前瞻多步规划、真实世界物理挑战验证等一系列设计中,并通过732M参数超越7B级模型的效率,以及透明物体抓取超越π0的效果,得到了实践检验。
而英伟达DreamDojo在预测目标、架构选择、表示方法、训练范式四个核心决策上的同步跟进,则从另一个侧面印证了这一方向的潜力。
王广润是国家海外高层次青年人才基金及华为战略人才基金获得者,中山大学计算机学院青年研究员、博士生导师,拓元智慧首席科学家。华为「天才少年计划」最高级别入选者;曾赴英国牛津大学担任Research Fellow,师从英国皇家科学院院士、皇家工程院院士 Philip H.S. Torr 教授。

时间线印证
他主要从事新一代AI架构、大物理模型与世界模型、多模态生成式AI方向研究。获吴文俊人工智能优秀博士论文奖(全国仅9人)、《Pattern Recognition》全球当年唯一最佳论文、全球AI华人新星榜(当年机器学习领域全球仅25人);担任多个CCF A类会议领域主席;在多项国际竞赛中获得金牌;研究成果被图灵奖得主Yann LeCun引用。
三者独立推进,却在四个核心决策上同步收敛:
① 预测目标:未来动作+视频联合体(物理量)② 架构选择:自回归逐步展开(契合物理因果)③ 表示方法:连续空间建模(避免量化误差)④ 训练范式:零动作预训练(视频物理先验迁移)
这不是偶然的相似,而是对同一底层规律的共同发现。
其中最核心的洞察是:
世界模型不是为了「看起来好」,而是为了「指导动作」
这是PAR/PhysGen与传统视频生成模型的根本区别。
传统视频生成模型(如Sora、Runway)追求的是视觉保真度——生成的视频要「看起来真实」、「美观流畅」。
但对于机器人操控而言,世界模型的根本目的不是生成一段视觉上美观的未来视频,而是希望生成的未来视频能对下一步的物理动作起到实质性的前瞻与指导作用。
核心哲学总结
对世界模型的理解,可以归结为一句话:
世界模型的价值不在于生成「好看的视频」,而在于生成「对动作有指导意义的物理预测」。视频只是物理演化的可视化载体,真正重要的是其中蕴含的物理因果关系——这些因果关系决定了「做什么动作会导致什么结果」,而这正是机器人决策的核心依据。
这也是为什么PhysGen能用732M参数超越7B级模型——它没有把算力浪费在「让视频更美」上,而是专注于「让物理预测更准」。
从PAR到PhysGen,正在验证一条清晰的技术路线:把机器人操控问题重新定义为「预测未来物理量」——未来的动作和视频联合体,并用自回归模型在连续空间中逐步展开这个预测过程。
更重要的是,明确了世界模型的根本目的:不是生成视觉上美观的未来视频,而是生成对下一步物理动作有实质指导作用的物理预测。这个理念体现在物理token联合建模、因果掩码逆运动学、前瞻多步规划、真实世界物理挑战验证等一系列设计中,并通过732M参数超越7B级模型的效率,以及透明物体抓取超越π0的效果,得到了实践检验。
而英伟达DreamDojo在预测目标、架构选择、表示方法、训练范式四个核心决策上的同步跟进,则从另一个侧面印证了这一方向的潜力。
作者介绍
王广润系国家海外高层次青年人才基金及华为战略人才基金获得者,中山大学计算机学院青年研究员、博士生导师,拓元智慧首席科学家。华为「天才少年计划」最高级别入选者;曾赴英国牛津大学担任Research Fellow,师从英国皇家科学院院士、皇家工程院院士 Philip H.S. Torr 教授。
主要从事新一代AI架构、大物理模型与世界模型、多模态生成式AI方向研究。获吴文俊人工智能优秀博士论文奖(全国仅9人)、《Pattern Recognition》全球当年唯一最佳论文、全球AI华人新星榜(当年机器学习领域全球仅25人);担任多个CCF A类会议领域主席;在多项国际竞赛中获得金牌;研究成果被图灵奖得主Yann LeCun引用。
参考资料:
https://arxiv.org/abs/2603.00110