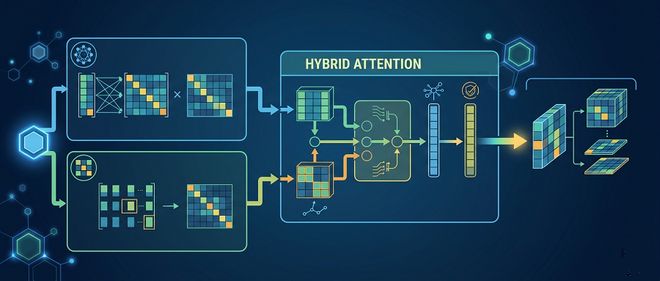
阿里、Kimi与蚂蚁联手加码,混合注意力成行业标配?
昨日,小米发布了Mimo-V2 Pro大模型,引起了行业对混合注意力架构的关注。该大模型拥有万亿级别的参数,采用了1:7的混合注意力比例,其性能接近Claude Opus 4.6,但API定价仅为后者五分之一。近期,国内多家领先的大模型企业均在混合注意力架构的研究上取得了进展,小米的这项技术也延续了国内顶尖厂商在效率优化上的共识。在今年2月,蚂蚁集团发布了全球首个混合线性注意力架构的思考模型;而阿
科技4 阅读
共找到 3 篇相关文章
昨日,小米发布了Mimo-V2 Pro大模型,引起了行业对混合注意力架构的关注。该大模型拥有万亿级别的参数,采用了1:7的混合注意力比例,其性能接近Claude Opus 4.6,但API定价仅为后者五分之一。近期,国内多家领先的大模型企业均在混合注意力架构的研究上取得了进展,小米的这项技术也延续了国内顶尖厂商在效率优化上的共识。在今年2月,蚂蚁集团发布了全球首个混合线性注意力架构的思考模型;而阿

3月19日,小米在SU7发布会上公布了其在AI大模型领域的最新研发成果和关键数据。小米公司创始人雷军表示,公司正在加大硬核科技领域的投入,计划在未来三年内至少投入600亿元人民币用于AI研发,而今年的支出已超过160亿元。在大模型基座方面,小米推出了面向智能体时代的旗舰大模型。这款模型采用了总参数量达1万亿的MoE架构,激活参数为420亿,并运用了小米自主研发的混合注意力机制,支持百万级的上下文长

科技日报记者 崔爽2月25日,在春节期间开源了Qwen3.5-397B-A17B之后,阿里巴巴继续发布了千问3.5系列模型的源代码。此次发布的三款新模型分别是Qwen3.5-35B-A3B、Qwen3.5-122B-A10B和Qwen3.5-27B,它们都采用了创新架构并经过了优化训练,在性能上超越了前一代的大规模旗舰模型。千问3.5系列模型运用了一种混合注意力机制,并结合高稀疏的MoE架构进行设