
xAI管理层巨变 马斯克迅速调整架构 分设四大部门 绘制宏伟蓝图
出品 | 网易智能作者 | 小小最近的全员会议中,马斯克分享了他对公司未来发展的看法和计划。会议正值一些关键团队成员离开之际,他强调公司在过去不到三年的时间里取得了显著成就,并展望了一个更为宏大的愿景。马斯克表示,xAI已经从一个想法迅速成长为拥有巨大算力、与航天巨头合并的庞大企业。然而,在这个过程中也出现了人员流动的情况。他对团队成员在公司初期阶段所作的努力和贡献表达了感谢,并祝他们未来一切顺利
科技13 阅读
出品 | 网易智能作者 | 小小最近的全员会议中,马斯克分享了他对公司未来发展的看法和计划。会议正值一些关键团队成员离开之际,他强调公司在过去不到三年的时间里取得了显著成就,并展望了一个更为宏大的愿景。马斯克表示,xAI已经从一个想法迅速成长为拥有巨大算力、与航天巨头合并的庞大企业。然而,在这个过程中也出现了人员流动的情况。他对团队成员在公司初期阶段所作的努力和贡献表达了感谢,并祝他们未来一切顺利

出品 | 网易智能作者 | 辰辰年薪超过五百万人民币,硅谷给那些擅长讲故事的人开出了高额薪酬。2026年初,硅谷上演了一场充满讽刺意味的情节反转:曾经的编程精英们正经历着自2009年以来最艰难的一段时期。仅在1月份,就有逾十万个技术职位被裁撤,原因很简单:AI可以更快更便宜地编写代码。就在这时,当程序代码逐渐变得廉价之际,过去被认为属于“软技能”甚至处于理工科鄙视链末端的写作和叙事技巧,却突然成了

出品 | 网易智能作者 | 小小近期,华裔技术精英相继离职,马斯克的AI帝国遭遇核心团队流失危机。2月10日,xAI联合创始人吴宇怀在社交平台X上宣布结束与马斯克的合作关系,并表示“将开始新的篇章”。紧随其后,仅隔一天,另一位关键人物吉米·巴也确认离职。尽管不久前马斯克刚刚宣布了xAI与SpaceX合并的消息,外界普遍预计这次合并会提振公司士气。然而,这一消息并未阻止核心技术领导层的集体出走。在不
出品 | 网易智能作者 | 辰辰免费的好事终于走到了尽头。随着ChatGPT广告业务的正式启动,这家全球领先的AI公司已经开始向免费用户的屏幕投放广告了。毕竟,再美好的梦想也需要资金支持。但这还不是最热闹的。为了争夺人工智能领域的霸主地位,OpenAI与其死敌Anthropic已经彻底摊牌——从超级碗赛场上的直接嘲讽到推特上的公开对骂,双方的火药味浓烈至极。在这场激烈的竞争中,CEO奥特曼向全体员

2月10日,谷歌母公司Alphabet宣布发行了总额为200亿美元的债券。当前人工智能公司的债务融资呈现出爆发式增长趋势,分析师预测这将导致今年公司债券发行量创下历史新高。据《国际融资评论》报道,这笔总额为200亿美元的高级无抵押债券由Alphabet分七个部分完成发行。《金融时报》周一报道称,该公司计划首次发行英镑债券,其中包括可能推出的百年期债券。该消息得到了知情人士的确认。对于置评请求,Al

出品 | 网易智能作者 | 小小一场视频制作领域的革命突然爆发,带来了兴奋与担忧。 最近的一周内,字节跳动悄然发布了新版AI视频模型Seedance 2.0,迅速在全球人工智能社区引发热议。 在国内,“影视飓风”等知名博主测试后表示“震撼不已”,X平台上外国网友则疯狂转发中国网友生成的视频,并惊叹:“仅凭一句话输入,它就能制作出一部大片!”“这光影、运镜和音效……与Sora相比简直是上个时代的产物

在最近的财报电话会议中,英伟达CEO黄仁勋和CFO科莱特·克雷斯讨论了公司的战略重点、市场前景及未来产品规划。黄仁勋强调了人工智能领域的发展趋势及其对公司业绩的影响,特别是生成式AI模型对计算需求的巨大推动作用。他表示,从长远来看,数据中心的资本支出规模将大幅增长至3到4万亿美元,因为各行各业都需要构建自己的“AI工厂”来生产token(数据单元)以支持业务发展。对于英伟达未来的产品路线图,黄仁勋
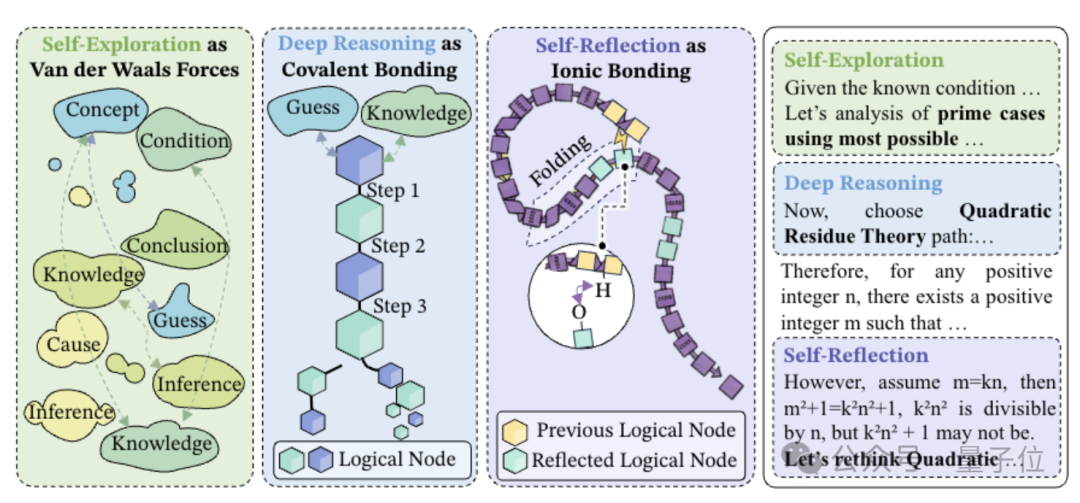
字节Seed开始运用化学原理来研究大型模型。 深度推理像是共价键,自我反思类似氢键,而自我探索则像范德华力? 传统的长思维链推理通常将AI的思考过程视为线性结构。 实际上,在很多情况下,后续的重要结论需要返回去验证早期提出的假设。 CoT忽略了这种非线性的依赖关系。 在论文《思想的分子结构》中,字节Seed首次为大模型定义了长链思维的分子式结构。 这种分子拓扑结构里,三种键是如何相互作用的?

Anthropic再次引起市场关注。 昨日,IBM股价大幅下跌13.15%,创下自2000年以来的最大单日跌幅,市值从约2408亿美元降至2087亿美元,缩水了超过310亿美元。这表明人工智能技术的迅速发展已经让该公司成为了新的受害者。 导致这一现象的原因是Anthropic发布了一篇博客文章,介绍了其Claude Code工具可以对使用COBOL语言的老系统进行现代化改造。而COBOL业务正是

全球首个深度思考的扩散模型诞生! 它摒弃了传统的自回归模式,成为世界上生成速度最快的模型。 对比之下,传统自回归的“打字机式”输出方式(逐个token按顺序生成)就像乌龟一样慢: 实际测试结果显示,在英伟达GPU上运行的Mercury 2扩散推理大语言模型可实现每秒1009个tokens的速度。 这一速度比GPT-5(mini版)和Claude-4.5(haiku版本)等传统模型快了五倍之多

英伟达又一次超越了自己—— 2026财年,英伟达发布了最后一个季度的财报。不出预料,依旧刷新多项纪录: 单季营收达到681亿美元(约4678亿元),同比增长73%,环比增长20%。 数据中心单季收入为623亿美元(约4280亿元),同比增长75%,环比增长22%。 全年总营收达2159亿美元(约14831亿元),同比增长65%。 这份财报无疑给资本市场带来了巨大的信心,“AI鬼故事”的阴影也一

在2025年12月之前,AI编程与之后的编程相比截然不同。 这一观点是由Vibe Coding的提出者Karpathy提出的。 要准确描述过去两个月里AI对编程的影响并不容易。这种变化不是渐进式的,而是在去年12月份发生的突然转变。 作为最积极采用AI编程技术的程序员之一,Karpathy承认,在去年12月之前,尽管Coding Agent有不错的表现,但实际上并没有多大用处。 然而从12月

Perplexity也加入了这场激烈的龙虾大战。 该公司在推特上宣布,推出了一款名为Perplexity Computer的新产品,这是一款基于浏览器的全能型通用数字助手。 据官方介绍,这款工具能够进行推理、任务分配、搜索、构建、记忆管理、编码以及项目部署和管理工作流程等操作。 它几乎涵盖了日常所需的所有场景功能。 Perplexity的首席执行官Aravind Srinivas表示,Per

“华为车载”冲刺港股IPO:5G技术领先,上汽、奇瑞、吉利和东风均是其客户。 华为车载解决方案供应商——云动智能,总部位于浙江,与国内前十的汽车制造商中的六家建立了合作关系,一年可交付上百万套方案,包括上汽、奇瑞、吉利、东风等多家车企。 随着招股书的提交,

2月24日讯,大疆创新于美国东部时间2026年2月20日向美国第九巡回上诉法院递交了诉状,针对联邦通信委员会(FCC)在2025年12月23日将该公司及其产品列入“受管制清单”的不当决定提出挑战。此举旨在捍卫公司的合法权益,并保护那些因禁令而受影响的美国消费者和农业行业的利益。在诉状中,大疆指出联邦通信委员会缺乏实质性的证据来支持其认为公司产品对国家安全构成威胁的说法,这不仅违反了正当程序原则,还
11月11日(星期二)的最新消息如下:国外知名科学网站报道,科研证实:掌握多种语言可延缓大脑衰老。最新研究显示,会讲多门语言的人确实可以减缓大脑的老化速度。这项发表在《自然·老化》杂志上的论文表明,双语或多语使用者出现“加速衰老”的几率比单语者要低一半。过去的研究常因样本量小、方法粗糙而受批评,但这次的研究数据来自欧洲27国的数万名51至90岁的健康志愿者,结论更具有说服力。研究结果表明,“掌握多

过去两年间,大型语言模型在推理领域的进步显著。从数学与编程生成到解决复杂的逻辑和科学问题,这些模型不断刷新基准测试的记录。随着“推理模型”概念的兴起,越来越多的研究开始将推理能力视为通向通用人工智能的关键标志。在能力迅速提升的同时,一个更为基础的问题逐渐显现:当模型在执行推理任务时出现错误,这些失误是随机波动还是表明了深层次的设计缺陷?近期发表于 TMLR 的论文《大型语言模型推理失败》对该问题进

目前对 VLA 模型的研究和测试大多集中在家用场景(如摆放餐具、折叠衣物),而对于专业科学环境,特别是生物实验室的应用则较少探索。生物实验室因其流程结构化、操作精度高以及多模态交互复杂等特点,是评估 VLA 模型在精确操作、视觉推理及指令执行能力方面的理想场地。最近,香港大学MMLAB 罗平教授团队和上海交通大学穆尧教授团队合作的项目“AutoBio”已被 ICLR 2026 接受,并且获得了同行

在许多大型模型及代理的训练过程中,常见的方式是仅依据结果来判断:如果最终答案正确,则给予奖励;反之则得零分。对于简单的问答任务,这种方法尚可适用;但当涉及到需要多轮对话、搜索和编写代码等复杂过程的任务时,这种评价方式就显得过于简化了。因此,在差之毫厘的情况下与一开始就走错方向的情况之间,仅凭结果评判无法区分其优劣;训练过程中也无法识别出哪些失败更为关键,人工细粒度的评分又难以应对开放环境和多模态任

想象一下,如果你让一个AI助手利用搜索工具来解决复杂问题时,它可能第一次探索就走错了方向,并且在后续尝试中重复相同的错误路径。虽然你可以从多次探索的结果中选出一个还算满意的答案,但这种方法不仅低效,还需要人工干预。这种现象是大多数深度搜索智能体面临的挑战之一——它们无法「记住」之前的探索经历,在每次新的任务开始时都得重新开始,导致大量的冗余搜索和资源浪费。当前的许多深度搜索模型多采用ReAct框架