
在当前大家都在追求算力提升的大环境下,理想汽车开始关注起“数学定律”。
作者|周永亮
到了2026年,关于智能辅助驾驶领域的一个普遍误区可能会被揭示——即更大的计算能力并不一定意味着更聪明的车辆。
近年来,车企之间的竞争主要集中在硬件性能上:谁拥有更强的芯片算力或更多的模型参数,似乎就能占据优势地位。

然而,理想汽车近期发布的一篇论文提出了一种截然不同的视角:与其一味追求计算能力的大规模提升,不如更加重视如何高效利用现有的计算资源,以实现更智能、更高效的运行效果。
这份与国创决策智能技术研究所联合发布的研究报告中提出了一个名为“软硬件协同设计定律”的数学框架。尽管听起来颇具学术气息,但它所解决的问题却非常实际:在受限于功耗、散热和成本的汽车芯片上,如何最大限度地发挥大模型的功能。
这一理论不仅是一种工程优化策略,也是理想自研芯片“马赫100”背后的理论依据之一。
01
从技术角度探讨这一课题
要理解当前行业面临的挑战,首先需要认清现有的问题所在。
目前,辅助驾驶系统的技术路径已经从规则驱动转向了以大语言模型为核心的视觉-语言-行动(VLA)体系。简单来说,这意味着车辆需在本地运行类似“小型GPT”的软件,以便理解和响应周围环境的变化。
然而,在云端环境中可以轻松部署大量GPU支持的大规模模型,在汽车上则受到功耗、散热和成本的限制,因此无法无限扩展计算能力。
更具挑战的是,芯片设计团队与算法开发者的步伐并不一致。前者遵循摩尔定律追求算力的增长;后者则在参数量扩张方面寻求突破性进展。
这种脱节导致了一个现实困境:即便芯片的理论峰值性能强大,实际运行中的系统效能却往往不尽如人意。为了适应硬件限制而作出妥协设计,反而可能削弱模型的实际表现。
而理想汽车的独特之处在于,在真刀实枪地部署VLA大模型于Orin和Thor芯片的过程中,深刻体会到了这一挑战的严峻性。
只有切身体会到痛点的存在,才有可能从根本上找到解决方案。
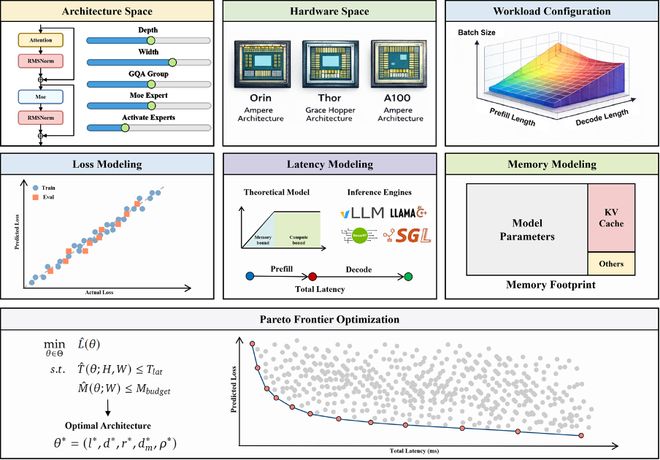
对此,理想与国创决策智能技术研究所提出了一套三步走的战略。
首先,他们进行了基础性的准备工作:训练了多达170种不同架构的模型,并评估了近2000个候选配置方案。
这意味着什么?以往解决这类问题通常依赖于反复试验的方法。而现在,通过输入特定参数值,可以无需实际运行即可预测模型精度。这标志着从“黑箱试错”向“白盒分析”的转变。
紧接着,在处理车载大模型所产生的大量临时数据方面,他们进一步优化了经典Roofline性能模型的适用性。
原始Roofline模型仅考虑计算和内存带宽之间的平衡关系。但为了适应车载SoC的特点,研究团队首次系统地将KV缓存、MoE路由等复杂因素纳入考量,并通过实验证明了其有效性。
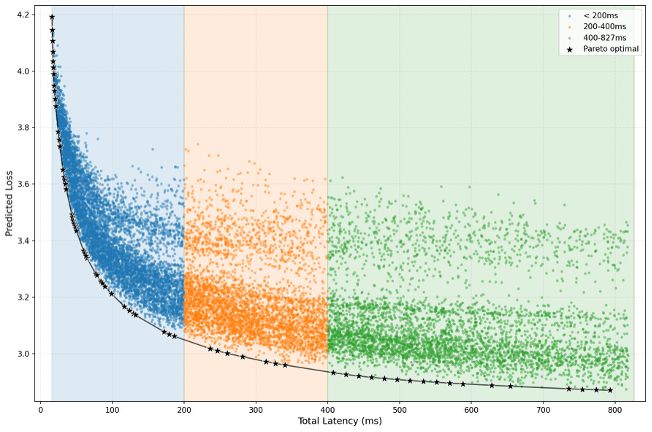
在上述工作的基础上,理想开发出了一套名为PLAS(帕累托最优LLM架构搜索)的框架。它可以看作是一个自动化的模型设计工具,在输入硬件参数和工程约束条件后,能够自动生成最优化的设计方案。
这意味着,更换芯片型号时只需花费一周时间即可完成相应的算法调整工作,大大缩短了研发周期。
实际效果如何呢?改进后的模型在延迟与Qwen 2.5-0.5B保持一致的前提下,精度提升了近五分之一。这充分展示了新方法的有效性。
02
六个反直觉的发现
更为重要的是,这项研究还揭示了一些颠覆传统观念的关键发现。
其中最令人惊讶的一点是:决定车载AI实际性能水平的,并不是芯片的最大算力,而是内存带宽和缓存效率这两个因素。
比喻来说,计算能力就像厨师的手艺,而传输速度则像送餐服务;即使手艺再高超,如果食物无法及时送达餐桌,厨房仍然会陷入混乱。这也意味着,在发布会上大肆宣扬的那些“TOPS”数值可能并没有实际意义。
同样值得注意的是另一个重大发现:稀疏计算将成为车载AI的标准配置之一。理想的研究表明,在处理单个请求的情况下,混合专家(MoE)架构能够以100%的概率超越所有密集型架构的表现。
通俗地说,这就像一家医院采用了一种全新的分诊机制,每次只派遣最合适的几位医生来诊治病人,从而大幅度提高了效率和资源利用率。

此外,在工程实现层面还存在三个重要的“坑”需要避免:AI推理过程分为两阶段(Prefill与Decode),对硬件资源的需求各不相同。未来的芯片设计必须能够根据具体任务动态调整工作模式以应对不同需求。
同时,传统的Transformer模型中的FFN模块长期以来一直沿用4倍扩展比例,但理想的实验证明这个惯例在车载应用中并不适用,需要重新审视和优化内部的计算单元配置。
还有,在理论上将计算精度从高降至低可以提升速度两倍的情况下,实际情况却只提升了1.3到1.6倍。这表明单纯依赖量化并不能带来显著性能改进,只有芯片底层支持混合精度才可能实现预期效果。
前面提到的这些发现看似各自独立,但它们共同指向了一个结论:没有通用的最佳芯片设计方案,而是需要根据特定场景定制化开发最合适的芯片。
这也是理想坚持自研芯片的核心逻辑所在。
03
为马赫 100 铺路
回顾这篇论文的战略意义,它为理想未来的研发方向奠定了基础——即其自主研发的“马赫100”智能驾驶芯片。
据披露的信息,“马赫100”是一颗采用5纳米工艺制造的车规级处理器,计划于2026年量产,并将首次搭载在新一代理想L9车型上。该芯片的有效算力将达到惊人的2560TOPS,是英伟达Thor U的三倍之多。
但“三倍”的数值本身并不是重点。“马赫100”最独特之处在于其软硬件协同设计理念:从一开始就根据算法需求定制每一个细节,而非盲目堆砌计算能力。
这就好比传统芯片是先建好房子再让住户适应;而“马赫100”则是事先了解住户的所有需求,并据此设计出最适合居住的空间布局。
从辅助驾驶体验的角度来看,“马赫100”的应用意味着在相同的功耗和散热条件下,能够运行更大、更智能的模型。这将使车辆面对复杂交通环境时更加从容不迫,识别异形障碍物的速度更快,从而显著提升智能辅助驾驶的整体性能。
如果仅仅把这篇论文看作是理想的一次“技术秀”,那就低估了它的实际价值。
深入分析其背后的逻辑,“马赫100”所倡导的理念正在重新定义车载AI芯片的评估标准:算法与硬件之间的匹配效率比单纯的计算能力更为重要。
从更宏观的角度来看,过去十年间汽车智能化的发展经历了三个阶段——先是购买现成的芯片并运行第三方算法;接着是自研算法同时采购通用芯片;现在则进入了自研软硬一体化解决方案的新时代。
这条路线已经被苹果在手机领域、谷歌在云计算平台以及特斯拉在其FSD芯片上成功验证:只有实现软硬件的高度融合,才能达到极致的用户体验。
因此,理想这篇论文的价值不仅在于它提出了何种数学公式,更重要的是通过一套可验证的方法论证明了算法与硬件必须紧密结合才能最大限度地释放智能技术潜力。这也成为了新一轮竞争中区分优劣的关键门槛。
论文标题为《Hardware Co-Design Scaling Laws via Roofline Modelling for On-Device LLMs》
*头图
本文为极客公园原创文章,转载请联系极客君微信 geekparkGO
极客一问
对此,你如何看待理想汽车的这篇论文?