
新智元报道
最新研究发现,当机器人从一个动作转换到另一个动作时,它们的视觉系统可能会被本体感觉所压制而失效。中国人民大学和北京航空航天大学的研究团队提出了GAP算法,该算法能够动态调整本体信号的学习权重,在视觉方面创造更多的学习机会,从而提高机器人的精确操作能力。
机器人在执行任务过程中获得的状态反馈信息通常来自于本体觉,这种感觉与视觉的协调作用被认为能增强其处理复杂控制任务的能力。
不过,最近的研究显示,当尝试将视觉和本体觉结合起来时,并非总能得到预期的效果。有些情况下,这样的策略会比仅依赖于视觉的表现更差——这引发了关于何时以及为何这些策略会失效的疑问。
最近,中国人民大学高瓴GeWu-Lab与北京航空航天大学的研究团队对这一问题进行了深入研究,发现机器人在进行动作转换时,视觉-本体策略中的视觉部分经常“失灵”。
为了解决这个问题,该团队开发了一种基于阶段引导的梯度调整算法(GAP),这项研究成果已经得到了ICLR 2026会议的认可,并且提出了关于机器人操作中如何有效结合视觉和本体觉的新见解。

近年来,随着深度学习技术的进步,研究人员开始尝试将有关关节位置、速度等本体信息集成到基于视觉的机器人操纵策略当中。然而,在实践中却发现加入这些额外的信息并不总是有利的。
当机器人的任务从一种模式过渡到另一种时,特别是当动作发生变化的时候,这种结合可能会遇到困难。这表明在某些阶段,视觉和触觉之间的配合可能无法达到预期的效果。
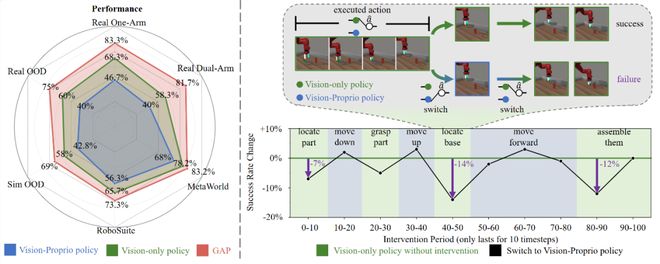
研究人员通过一系列精心设计的实验来探索这个问题。他们设置了一个场景,在这个场景中一个纯视觉策略执行装配任务,并且在特定的时间点插入了由视觉-本体策略产生的动作预测结果。
研究背景
实验显示,当机器人的运动保持平稳时,这种替换对整体性能几乎没有影响;但是一旦涉及到复杂的动作转换阶段,例如移动底座或装配零件,任务的成功率就会显著下降。
这一现象表明,在需要视觉信息做出决策的关键时刻,传统的视觉-本体策略可能会失效。研究者们进一步分析了可能的原因,发现视觉线索在这些复杂场景中往往不够明显,而本体感觉信号则更为直接有效。
为了解决这个问题,研究人员开发了一种新的算法——GAP(基于阶段引导的梯度调整),该算法能够在机器人动作转换的关键时刻降低对本体觉信息的学习权重,从而让视觉模态能够更好地发挥作用。
在实验中,研究团队首先定义了机器人的运动模式,并使用变化点检测方法来识别不同的操作阶段。通过这种方法,他们可以精确地定位到那些需要视觉和触觉协同工作的特殊时间段。
问题探究
为了更准确地捕捉动作转变的细节,研究人员还引入了一种基于时间序列的方法,利用本体感觉信息的时间特征预测每个时刻是否属于复杂的转换期。
在训练过程中,GAP算法会根据当前阶段的概率动态调整优化过程中的梯度强度,这有助于改善视觉部分的学习效果,在需要时给予它更多的关注和学习机会。
实验结果表明,使用了GAP的机器人在各种任务设置下都取得了比传统策略更好的表现。无论是单臂操作还是双臂协调作业,或是涉及更复杂多模态信息的任务,如视觉-语言-动作模型(VLA),都能看到显著的进步。
- GAP算法不仅成功地提升了机器人的性能,在解释性和兼容性方面也表现出色,它为实现真正的多模式机器人系统提供了新的视角和方法。
但在「定位底座」、「装配零件」这类运动转变阶段,替换策略后任务成功率明显下降。
这说明在需要视觉发挥作用的运动转变阶段,视觉–本体策略中的视觉模态「失效」了。为什么视觉会被边缘化?研究者进一步从训练优化的角度寻找答案。
他们发现,在运动转变阶段,视觉线索往往非常细小,有时甚至只是像素级的差异,而本体信号则简洁、直接。
在训练过程中,策略会本能地依赖那些能让损失更快下降的本体信号,使得本体模态在优化中占据主导地位。这种主导地位反过来抑制了视觉模态的学习,导致视觉信息在运动转变阶段被严重忽视。
核心技术
针对视觉模态在运动转变阶段被抑制的问题,研究团队提出了如图2所示的基于阶段引导的梯度调整算法(Gradient Adjustment with Phase-guidance, GAP)。核心思路是:先识别出任务中的运动转变阶段,然后在这些关键时刻动态调整本体觉信号的优化强度,为视觉模态「让出学习空间」。
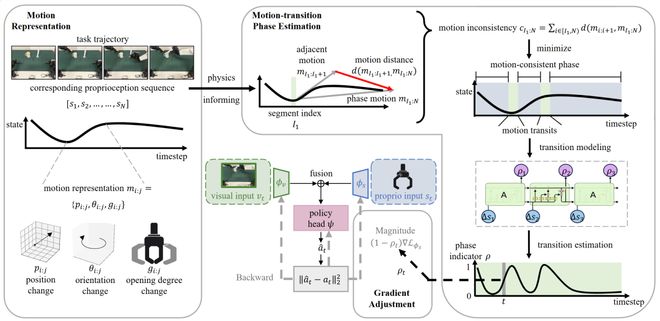
图2:GAP方法架构
为了识别运动转变阶段,研究团队首先利用机械臂末端执行器的位置、朝向和开合程度来定义机器人的运动。
随后采用变化点检测算法,通过计算不同时段运动方向的一致性,将轨迹分割为一系列「运动一致阶段」,如「持续向前移动」、「稳定抓取」等。在这些阶段之间,就是机器人的「运动转变阶段」。
然而,运动的转变是连续且渐变的,简单的离散切分难以刻画该过程的平滑特性。
为此,研究进一步引入时序网络,利用本体觉信号的时序差异,预测每个时刻属于运动转变阶段的概率。
在反向传播时,GAP会根据当前时刻的转变概率,动态降低本体觉特征提取模块的梯度更新幅度。转变概率越高,本体觉的梯度被抑制得越明显,让视觉模态有机会被充分学习。
性能亮点
GAP算法的有效性在大量实验中得到了充分验证。无论是在仿真环境还是真实机器人上,无论是单臂还是双臂任务,GAP加持下的视觉–本体策略都交出了亮眼的成绩单。



可以看到,在操纵任务「移交」中,纯视觉策略难以完成精细的放置操作,而视觉-本体策略在抓取失败后忽视视觉反馈,仍按照本体的经验继续执行动作。应用GAP的视觉-本体策略则得益于两者的协同,顺利地完成了任务。



如表1所示,在多样的任务设置中,GAP不仅帮助了视觉-本体策略超越纯视觉策略,真正利用模态协同的优势,同时还超越了多种现有的基线方法。
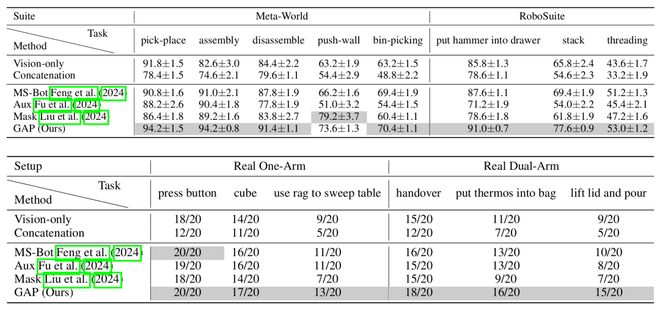
表1:对比实验结果
研究团队同时也验证了GAP是否适用于视觉-语言-动作模型(VLA)。如表2所示,在多个任务上,加入本体觉的Octo-VP反而比纯视觉的Octo-V表现更差,而GAP的介入则彻底扭转了这一局面。

表2:VLA实验结果
研究团队同时也验证了GAP对多种常见的模态融合方式的兼容性(表3),并观察了GAP预测的运动转变概率与任务RGB图像和视觉不确定性的关系(图3),以提升方法的可解释性。

表3:模态融合方式实验
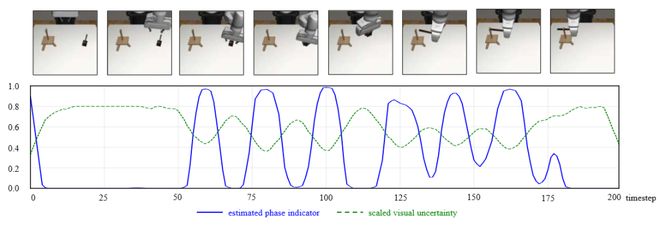
图3:运动转变概率可视化
结语
从多篇研究的反直觉现象一步步深入,该研究揭示了运动转变阶段中被抑制的视觉模态学习。
研究团队据此提出了GAP算法,使得两种模态在机器人操纵任务中更好地协同。真正的多模态具身智能,必须建立在对模态之间动态关系的深刻理解之上。
而GAP通过运动转变阶段提供了一种分析框架,为具身智能中的高质量多模态融合与交互提供了全新的视角。
参考资料:
https://arxiv.org/pdf/2602.12032