
在大模型时代,资源瓶颈不仅涉及硬件,还与数学难题相关。
作者|王艺
3月25日,美股开盘后,存储芯片板块遭遇重大挫折。
美光科技股价下跌4%,而其他两大制造商也出现不同程度的下滑。
这一变动引发了市场对人工智能芯片需求的重新评估。
谷歌发布的新算法TurboQuant展示了其在压缩键值缓存中的注意力逻辑值方面的卓越性能,尤其是在各种位宽级别上。

该算法不仅在实验结果中表现出色,还拥有坚实的理论基础。
论文通过香农信息论中的失真率函数和Yao's minimax原理,证明了TurboQuant的MSE误差仅比理论极限高出约2.7倍。
这一发现意味着,尽管KV Cache的内存需求仍然存在,但在近理论极限条件下,其压缩能力显著提高。
TurboQuant能够显著降低推理阶段的内存敏感度,使相同硬件能够支持更多请求。
云厂商的推理成本因此下降,而算力供给侧的议价能力则相应减弱。
随着模型规模和上下文长度的增加,整体内存需求仍会增长,但TurboQuant推动了边际需求曲线的变化。
早期阶段,企业主要通过模型规模和数据质量来竞争,而现在系统层和算法层的优化成为关键。
例如,FlashAttention、PagedAttention等技术的出现,降低了对硬件需求的依赖。
TurboQuant的广泛应用代表了从依赖昂贵内存转向更高效数学解决方案的转变。
在整个AI基础设施链条中,软件层的价值占比正在提升,硬件差异化空间被部分侵蚀。
未来,竞争点可能从“谁的HBM更大”转向“谁的系统栈整合得更好、调度更智能、算法更先进”。
对于投资者而言,这意味着重新评估产业链中“谁在卖稀缺性,谁在卖效率”。
对工程师来说,优化空间从参数规模转向结构设计与信息表达,这是一个更具挑战性的时代。
对整个AI行业而言,这或许只是一个开始,标志着一个新时代的到来。
过去几年,行业解决内存问题的方案主要沿着三个方向展开:
第一是从“长度”上压缩——滑动窗口注意力(Sliding Window Attention),只保留最近固定长度的记忆,扔掉太远的上下文。这相当于给缓存的“长”设了上限。Kimi前段时间提出的Attention Residuals(注意力残差),就是在用这个方法解决大模型注意力的问题。(详见)
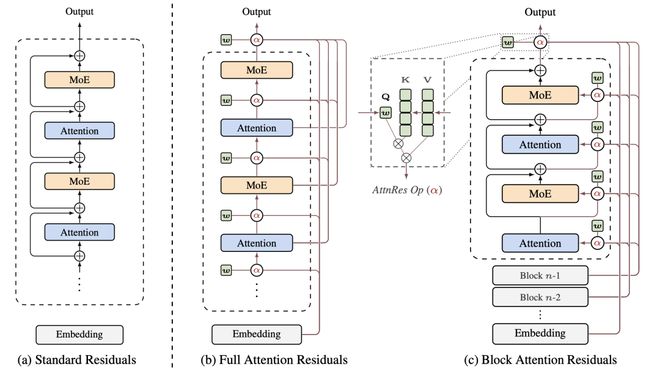
注意力残差概述。(a)标准残差:采用统一加法累加的方式进行的标准残差连接;(b)全注意力残差:每个层通过学习到的注意力权重有选择地整合所有前一层的输出;(c)块注意力残差:将层分组成块,从而将内存消耗从 O(Ld) 减少到 O(Nd)。图源:《Attention Residuals》
第二是从“高度”上压缩——GQA(Grouped-Query Attention)、MQA(Multi-Query Attention)等架构改进,减少Key/Value头的数量,降低每一层需要缓存的数据量。
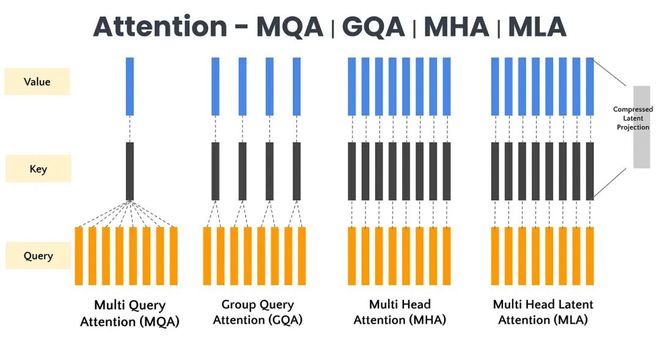
MQA通过在多个注意力头之间共享同一组键和值,同时为每个注意力头维护不同的查询,降低了计算复杂度和内存使用量;GQA是对MQA的一种优化,不是为每个查询单独计算键值表示,而是为每个组计算共享的键值表示。 图源:VerticalServe Blogs 《Attention Variations — MQA vs GQA vs MHA vs MLA》
第三是从“精度”上压缩——量化。把原本用16bit浮点数存储的KV向量,压缩到8bit、4bit甚至更低的整数表示。
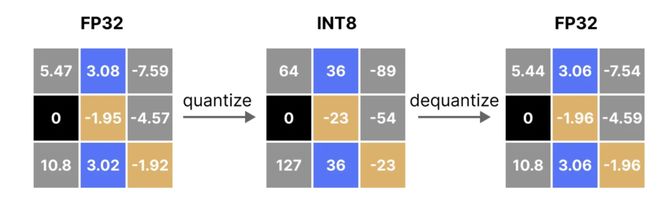
量化就像把人工智能模型中使用的非常大的数字缩小成更小的数字,从而节省空间并提高运行速度,譬如不再使用超高精度的数字(浮点数),而是使用更简单的数字(整数)。图源:CloudThrill
量化看似是最直接的方案,但传统量化方法有一个致命的隐形成本:元数据开销。
几乎所有传统量化方法都需要为每一小块数据额外存储一组全精度的“缩放因子”(scale)和“零点偏移量”(zero-point),用于将低精度整数还原回近似的浮点值。在位宽较高(比如8bit)时,这些元数据占比很小,可以忽略。但当压缩到4bit甚至更低时,这些“手续费”占总存储的比例急剧攀升——标称4bit,实际可能是5到6bit,压缩效率被自己的开销蚕食了一大截。
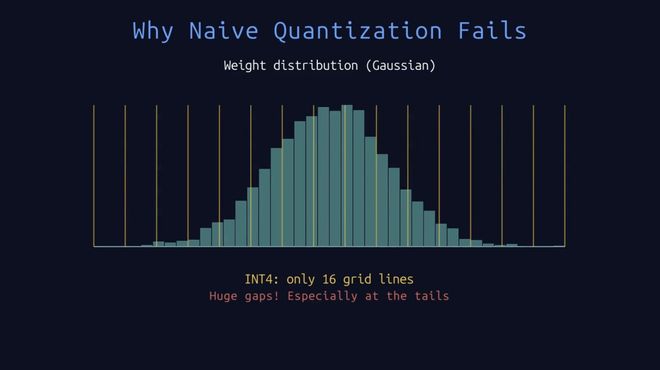
量化前后的模型权重分布,INT8精度下有256条网格线,INT4精度下却只有16条网格线。图源:Toutube @Tales Of Tensors 《LLM Quantization Explained: GPTQ, AWQ, QLoRA, GGUF and More》
更深层的问题是,很多量化方法是离线的——它们需要拿一批校准数据跑一遍,学习出最优的量化参数。但KV Cache是推理时实时生成的,每个用户的对话内容都不一样,根本没有办法提前做离线校准。
这就是TurboQuant真正要解决的问题。它要做的是从根本上消灭传统量化的这些隐形税,做一个真正适合在线、实时、零预处理场景的“向量压缩器”。
2.TurboQuant到底做了什么?
TurboQuant的设计哲学,用一句话概括就是:结构优化>暴力压缩。其核心思路可以用一个生活中的类比来理解:
想象你要把一堆形状各异的衣服塞进行李箱。传统方法是直接硬塞,塞不下就用力压,还得在每个角落垫上填充物(元数据开销)来保持形状。而TurboQuant的做法是:先把所有衣服用同一种方式折叠整齐(随机旋转),然后按照统一的尺寸标准打包(最优标量量化),最后检查一下有没有折痕没整理好,用一张薄纸垫一下(QJL残差纠偏)。
具体来说,TurboQuant分为两个阶段:
第一阶段:随机旋转+MSE最优量化
TurboQuant首先对输入的高维向量做一次随机旋转变换。
在高维空间中,一个单位向量经过随机旋转后,其每个坐标分量的数值都会收敛到一个已知的概率分布——Beta分布(在高维下近似为正态分布)。更关键的是,不同坐标之间近似相互独立。
这意味着,无论原始数据长什么样,经过旋转后,所有向量的所有坐标都服从同一个已知的分布。
既然分布已知且统一,就可以针对这个分布预先计算出数学上最优的量化方案——通过求解经典的Lloyd-Max量化器(本质是一维连续空间上的k-means问题),找到每个位宽下误差最小的量化码本。这些码本可以提前算好、永久存储,推理时只需查表,完全不需要针对具体数据做任何调整。
这就是TurboQuant消灭传统量化“隐形开销”的关键:不需要存储任何scale、zero-point等元数据,因为分布本身是通过数学变换被“锁定”的。每一个bit都被用于存储真正的信息,没有一丝浪费。
第二阶段:QJL残差纠偏
到这里,第一阶段的压缩已经非常高效了——如果我们只关心"还原出来的向量和原来像不像",它几乎是最优解。但大模型在实际运算时,并不是把向量还原出来看看就完事了,而是要拿压缩后的向量去做“内积运算”(可以粗略理解为“比较两个向量有多相似”),这才是注意力机制的核心操作。而恰恰在这一步,问题出现了。
为什么内积很重要?因为Transformer的注意力机制的核心运算就是Query向量和Key向量的内积。如果量化后的内积估计有偏差,注意力分数就会系统性地偏移,最终导致模型输出质量下降。
论文中给出了一个精确的例子:在1bit量化时,MSE最优量化器会给内积引入2/π≈0.637的乘性偏差——也就是说,所有内积都会被系统性地缩小约36%。这在高位宽时偏差会减小,但在极低位宽下是不可忽视的。
TurboQuant的解决方案极为巧妙:在总位宽预算b中,先用b-1位做MSE最优量化(把“主体信息”装进去),然后对残差(原始向量与量化重建之间的差)施加一个1bit的QJL(Quantized Johnson-Lindenstrauss)变换。QJL是同一团队此前提出的一种基于随机投影的1bit量化方法,其核心性质是:对内积估计是无偏的。
两步叠加后,整个系统的内积估计就变成了无偏的,同时方差(误差的随机波动)也被控制在接近信息论极限的水平。
在TurboQuant的发布博客上,谷歌官方用几个数据描述了这个新算法的有效性——“3bit无损”、“8×加速”、“6×压缩”、“零预处理”。
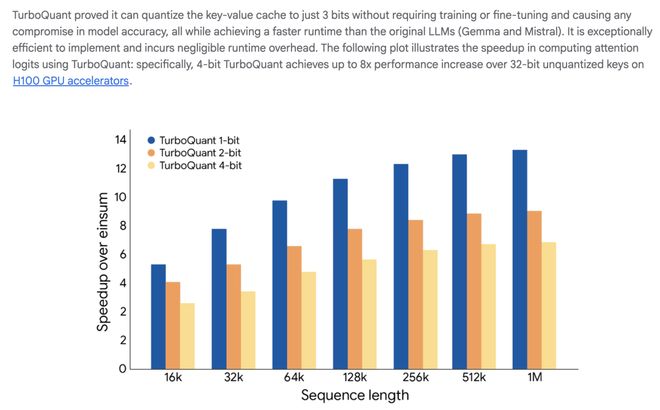
TurboQuant 在计算键值缓存中的注意力逻辑值方面表现出显著的性能提升,在各种位宽级别上均优于高度优化的JAX基线。图源:Google Research Blog《TurboQuant: Redefining AI efficiency with extreme compression》
TurboQuant之所以在学术界引起巨大震动,不仅因为实验结果好看,更因为它有严格的理论依据。
论文利用香农信息论中的失真率函数(distortion-rate function)和Yao’s minimax原理,证明了一个下界:对于任何量化算法,bbit量化的MSE不可能低于1/4^b。
而TurboQuant的MSE上界是(√3π/2)×(1/4^b)≈2.7×(1/4^b)。
也就是说,TurboQuant的失真率只比“宇宙中任何算法都不可能突破的理论极限”大约2.7倍。在低位宽下这个差距更小——1bit时仅为1.45倍。

TurboQuant的 MSE 失真率被证明最多不超过信息论下界 2/√3π ≈2.7,在比特宽度b=1时,TurboQuant的失真率仅比最优值低约1.45倍。图源:《TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate》
这类向量压缩问题本身就证明了很高质量的低比特解法是存在的。一旦市场意识到“KV Cache不是只能靠更大HBM暴力解决,而是存在接近理论极限的压缩路线”,那么纯粹依赖内存稀缺叙事抬估值的那部分溢价,就会更容易被压缩。
3.“内存墙”被绕过了吗?
TurboQuant论文发布后,市场给出了非常迅速的反应——前段时间因为HBM而大幅上涨的存储芯片股(详见《》)在今天应声下跌。很多人认为AI芯片将不再需要那么大的内存了,HBM的叙事将走弱,AI芯片的“内存墙”也将被绕过。
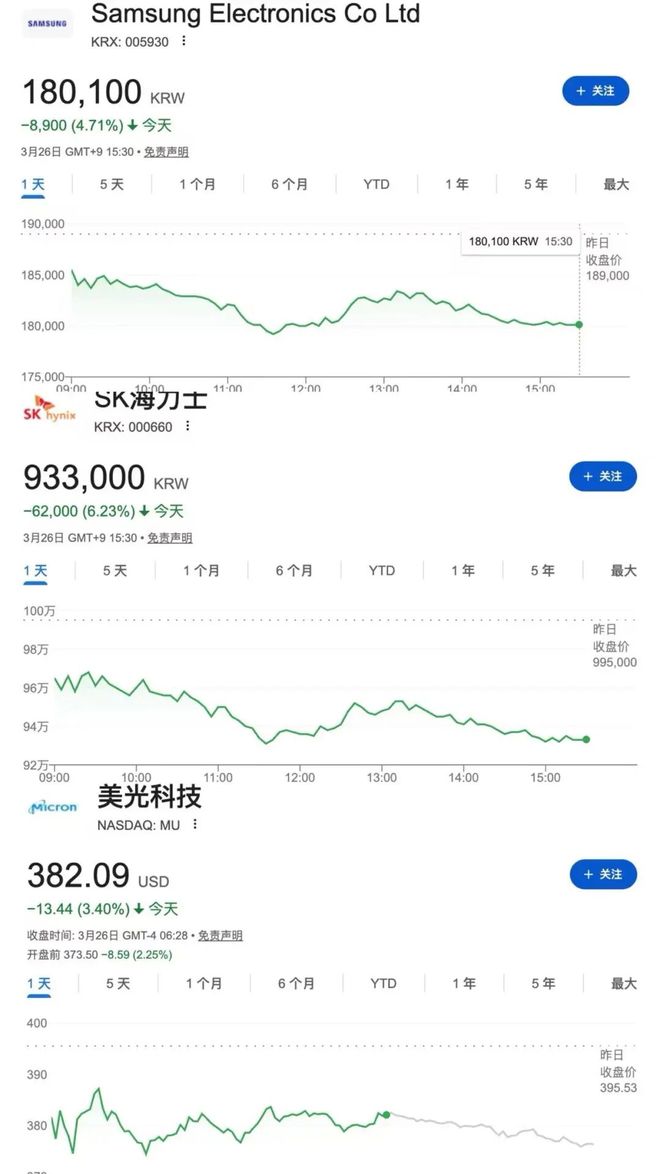
存储芯片三大原厂今日股价 图源:Yahoo Finance
但是,「甲子光年」认为,将TurboQuant理解为“HBM需求将被大幅削弱”、自此就认为“内存墙将会被绕过”的判断有点过了,这是一种过度线性的思考。
TurboQuant本质上解决的是:在既定显存容量下,如何提升单位字节的有效信息密度。
它并不会减少训练所需的HBM容量——训练阶段仍然需要高精度参数、梯度和优化器状态;它主要优化的是推理阶段的KV Cache开销。而当模型规模继续扩大、上下文长度继续拉长时,总内存需求仍然会上升。
换句话说,TurboQuant更像是把“内存墙”向外推远了一段距离,而不是把墙推倒。
真正被改变的,是边际需求曲线。
过去几年,HBM的投资逻辑建立在一个朴素假设上:模型越大、上下文越长、并发越高=显存需求线性爆炸。
如果KV Cache可以在近理论极限的条件下压缩到3-4bit,那么推理阶段对HBM容量的敏感度就会显著下降。需求曲线从“线性放大”变成“被压缩后的线性放大”。
这会带来两个变化:
第一,单卡利用率提升。相同硬件可以服务更多请求,云厂商的推理成本下降,算力供给侧的议价能力被削弱。
第二,容量升级节奏放缓。如果原本需要从80GB升级到120GB才能支持某种超长上下文,现在通过量化就能实现,那么硬件升级的迫切性会降低。
这并不是说大模型对内存的需求消失了,而是说单位算力对应的营收能力提高了。对于云厂商是利好,对于单纯卖“更大容量”的供应链企业,则是估值体系的重估。
此外,「甲子光年」在多位技术专家交流后得到的信息是,大家一致认为,工程优化逐步吞噬硬件溢价将会是AI产业的一个长期趋势。
早期大家拼模型规模,中期拼数据质量,现在越来越多的竞争发生在系统层和算法层——FlashAttention、PagedAttention、GQA、MoE、推理调度优化、算子融合……每一次看似微小的改进,都在降低对“暴力堆料”的依赖。
可以说,TurboQuant如果被大规模工程化落地,那么它代表的是一种范式转移——从“用更贵的内存解决问题”转向“用更聪明的数学解决问题”。
整个AI基础设施链条,它也意味着软件层的价值占比提升。
当压缩算法接近信息论极限时,硬件差异化的空间被部分侵蚀。真正的竞争点可能从“谁的HBM更大”转向“谁的系统栈整合得更好、调度更智能、算法更先进”。
这也是为什么这篇论文被一些人称为“DeepSeek时刻”——它像DeepSeek对模型训练成本的冲击一样,对推理阶段的资源结构提出了挑战。
TurboQuant未必会让HBM失去价值,也不会让GPU需求崩塌。但它释放了一个强烈信号——在大模型时代,资源瓶颈不只是硬件问题,更是数学问题。当压缩效率逼近信息论极限时,我们看到的不是“更少的算力”,而是“更高的单位算力产出”。
对于投资者而言,这意味着必须重新评估产业链中“谁在卖稀缺性,谁在卖效率”;对于工程师而言,这意味着一个更具挑战性的时代:优化空间正在从参数规模,转向结构设计与信息表达。
而对于整个AI行业而言,这或许只是一个开始。
(封面图