
如何让人工智能不仅能够生成可执行的代码,还能优化代码的运行效率?这个问题长期以来一直困扰着研究者。
最近,中国科学院计算技术研究所的一个团队提出了名为 SparseRL 的新框架,首次将深度强化学习应用于稀疏 CUDA 代码的生成任务中。简单来说,就是让 AI 学会根据稀疏矩阵的具体结构,自动生成最优化的 CUDA 实现代码。
实验数据表明,在经典的 SpMV 任务上,该方法将编译成功率提高了 20%,代码执行速度提升了 30%。
目前,这项研究成果已被 ICLR 2026 会议选为口头报告。

- 论文地址:https://openreview.net/pdf?id=VdLEaGPYWT
- 为何稀疏代码如此难以编写?
要理解 SparseRL 的价值,我们首先需要了解稀疏矩阵操作的独特性。
稀疏矩阵广泛应用于大型语言模型推理、图神经网络和科学计算中。不同于稠密矩阵,稀疏矩阵的非零元素分布是不规则的,这意味着最优的 CUDA 实现代码要根据矩阵的具体结构来确定,而这只有在运行时才能得知。
这就意味着没有一种“万能”的高性能实现能够处理所有类型的稀疏矩阵。工程师们不得不根据不同类型的稀疏模式手动调优,这不仅耗时,还依赖于个人的经验。
传统的 AI 代码生成方法对此也无能为力,原因有三:
首先,传统监督学习只关注代码的正确性,而忽略了执行效率。对于相同的稀疏矩阵,可能存在多种正确的 CUDA 实现,但执行速度可能相差数倍,监督学习无法区分这些差异。
- 其次,执行效率这一关键指标是不可微分的,传统的反向传播方法无法对其进行优化。
- 再者,稀疏矩阵的输入(即行列索引序列)与 CUDA 代码之间存在巨大的语义鸿沟,使得模型难以理解矩阵结构和最优代码策略之间的联系。
- SparseRL 是如何实现的?
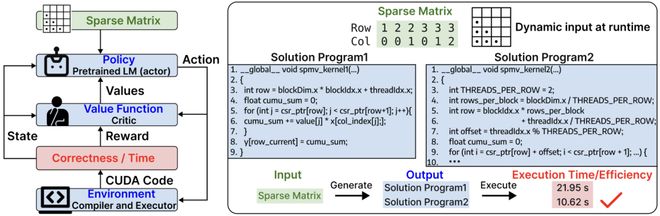
研究团队采用了巧妙的策略:既然执行效率无法通过微分来优化,就利用强化学习进行优化。
SparseRL 将预训练语言模型作为策略网络,每次生成一个 token 被视为一次行动,代码的编译结果和执行时间则作为奖励信号。
整个训练过程分为三个阶段:
第一阶段是预训练,即在大量 CUDA 代码的数据集上训练语言模型,使其具备对 GPU 编程的基本认知;
第二阶段是监督微调,利用稀疏矩阵与正确代码的配对数据来训练模型生成语法正确且功能正确的代码;
- 第三阶段是强化学习优化,这是整个框架的关键步骤,通过引入深度强化学习,以编译的正确性和执行的效率为奖励,让模型学会生成高性能代码。
- 为了让模型真正理解稀疏矩阵的结构,研究团队开发了一项关键技术:正弦位置嵌入。
- 稀疏矩阵的输入是非零元素的行列索引序列,传统的 token 嵌入无法捕捉这种二维坐标之间的空间关系。SparseRL 对行列索引进行正弦 / 余弦编码,类似于 Transformer 的位置编码,但做了特定的优化。
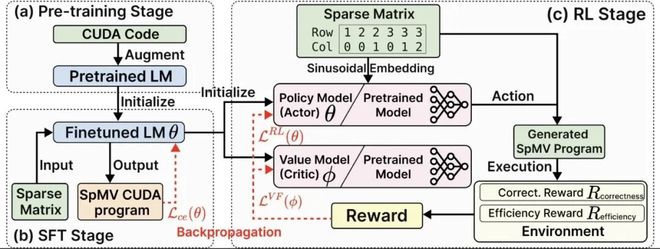
用通俗的语言来说,这就像是给模型戴上了一副“坐标眼镜”,让它能够识别非零元素的位置和分布。
另一个关键创新是层次化的奖励函数。这个奖励函数同时考虑了两个层面:正确性奖励确保代码能够编译和运行;效率奖励则用于优化执行速度。设计思路是先确保“正确”,再追求“高效”。
研究团队通过 SpMV(稀疏矩阵-向量乘法)和 SpMM(稀疏矩阵-稠密矩阵乘法)任务验证了该方法的有效性。
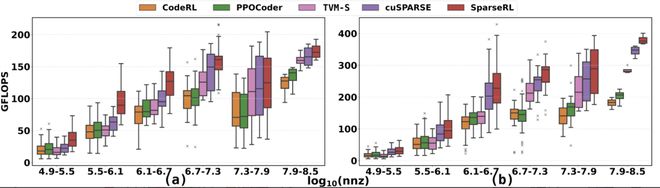
在 SpMV 任务中,SparseRL 相较于传统的监督学习方法,将编译成功率提升了 20%,平均执行速度提高了 30%。更重要的是,模型能够根据不同的稀疏结构自动选择不同的代码策略,在对角型、带状型、随机稀疏型等多种矩阵上都表现出色,部分情况下生成的代码甚至接近或超过了手工调优的结果。
团队还进行了消融实验,以验证各个组件的重要性。
效果如何?
结果显示,缺少 RL 阶段会导致性能显著下降,说明强化学习确实是关键;缺少正弦嵌入则会导致模型难以理解输入结构,编译成功率下降;而仅使用正确性奖励而不使用效率奖励,代码虽然能够运行但不够快。
当然,这种方法也有局限。论文指出,RL 训练需要大量的编译和执行反馈循环,计算成本较高;模型是针对特定 GPU 架构训练的,迁移到新硬件可能需要重新微调;生成的代码可能缺乏人类工程师的编码风格,可解释性不足。
SparseRL 的价值在于它开启了一个新的范式:代码生成的目标从“生成可运行的代码”转向“生成高性能的代码”。
对于高性能计算工程师和 AI 基础设施开发者来说,这项工作展示了 AI 在处理性能优化工作方面的潜力,使人类能够将精力集中在更高层次的设计上。
研究团队表示,未来计划将方法扩展到多 GPU 分布式稀疏计算,探索与传统 AutoTuning 技术的结合,并支持更多类型的稀疏算子。同时,他们也在研究如何降低 RL 训练成本,使这种方法更具实用性。
当然,这个方法也有局限。论文提到,RL 训练需要大量的编译 - 执行反馈循环,计算成本较高;模型是针对特定 GPU 架构训练的,迁移到新硬件可能需要重新微调;生成的代码可能缺乏人类工程师的编码风格,可解释性不足。
意义与展望
SparseRL 的价值在于它代表了一个范式转变:代码生成的目标从「生成能运行的代码」转向「生成高性能代码」。
对于 HPC 工程师和 AI 基础设施开发者来说,这项工作展示了一种新可能 ——让 AI 来处理那些繁琐的性能优化工作,而人类可以把精力放在更高层次的设计上。
研究团队表示,未来计划将方法扩展到多 GPU 分布式稀疏计算,探索与传统 AutoTuning 技术的结合,并支持更多类型的稀疏算子。同时,他们也在研究如何降低 RL 训练成本,让这种方法更实用。
作者介绍
王耀宇,中国科学院计算技术研究所博士生(共同一作),主要研究方向为深度学习编译优化与高性能计算。
谭光明,中国科学院计算技术研究所研究员、博士生导师,主要从事高性能计算、GPU 编译优化与深度学习系统研究,在多 GPU 分布式计算、稀疏矩阵计算、深度学习编译器等领域取得多项重要成果,发表多篇高性能计算与机器学习相关论文。