 近日,RoboScience 推出了一项名为「具身世界模型」的创新技术,它在机器人领域引发了广泛关注。
近日,RoboScience 推出了一项名为「具身世界模型」的创新技术,它在机器人领域引发了广泛关注。
这项技术的核心理念是让机器人能够预见未来的各种情况,比如物体的移动方式、接触事件以及可能存在的风险,从而提高其决策能力。
「具身世界模型」能够在虚拟环境中构建一个符合物理规律的、可预测的“想象空间”,使机器人能够进行无限次的模拟实验,以验证各种可能的轨迹和风险,最终在真实世界中从容地执行任务。
当前,大多数行业内的世界模型专注于两种方向:一种是生成2D视频帧的预测,另一种是进行3D静态重建。然而,这两种方法都无法同时预测物体的动态变化。相比之下,「具身世界模型」则采用了一种全新的策略,即3D动态世界模型,可以预测物体在三维空间中随时间变化的轨迹。
在RoboScience的VLOA大模型体系中,「具身世界模型」与「通用操作模型」共同构建了一个完整的闭环,实现从理解物理世界到预测未来轨迹,再到执行精确动作的全过程。
该模型的一大特点是它可以接收自然语言指令和视觉图像作为输入,无论是单视角还是多视角的图像,都能精准地定位目标物体及其未来状态。
相较于传统方法只预测下一帧图像的像素,「具身世界模型」更关注物体在三维空间中的状态变化,包括位置、姿态、形变以及与其他物体的相互作用,从而预测其未来的运动路径。
最终,该模型输出的是物体未来运动路径的3D点云轨迹,即带有时间戳的三维点序列,每个点都包含了详细的位置、姿态、时间步和预测置信度信息。
选择3D点云的原因在于,它能够直观地展示模型预测的路径,同时在真实三维空间中进行建模,满足几何约束,并且可以直接作为下游操作模型的输入。
这些3D点云轨迹是通过一个专为动态三维世界设计的神经网络架构,从输入的视觉图像和语言指令中生成的。


「具身世界模型」的内部结构包括将RGB观测、3D点云先验与任务指令分别编码为可计算的语义与空间表征,随后通过世界因果Transformer对任务条件下的未来世界演化进行建模,形成统一的潜在世界表征;之后通过解码过程输出场景与目标物体的3D flow,并可进一步生成未来操作视频。
这一架构赋予模型三项核心能力:跨物体泛化、动态过程建模以及指令跟随。
在跨物体泛化方面,模型能够理解和预测不同材料、形状和尺寸的物体的运动轨迹。
动态过程建模方面,模型能够预测复杂的物理过程,如倒水时的液体动态和精细操作。
指令跟随能力使模型能够理解复杂的语义意图,生成针对不同物体和指令的精确操作。
通过以上案例,「具身世界模型」从一个“黑箱”变成了一个可解释、可调试、可信赖的认知引擎。
该模型的核心特性包括物理约束满足、原生支持物理多解性建模、长时序空间一致性以及硬件解耦。
这些特性使得「具身世界模型」不仅能够进行可靠的预测,还能在复杂的多步骤任务中保持预测的连续性和一致性。
随着训练的进行,模型的能力在多个关键指标上持续提升。
多物体抓取演示

通过不断扩充视频数据集和增加计算资源,模型对物理世界的理解越来越精准,生成的未来轨迹也越来越贴近真实。
这种持续进化的特性遵循了具身智能领域的Scaling Law,表明模型的成长性是可预测、可持续的。
在VLOA架构中,具身世界模型扮演着“认知大脑”的角色,通过物体轨迹接口将预测信息传递给通用操作模型。
支撑两大模型持续进化的基础是庞大的高质量数据体系。
公司通过全自动的数据标注与清洗流程,从海量互联网视频中筛选出与物体状态变化和物理交互相关的高价值内容,积累了超过100万小时的高维多模态操作视频数据,并以每周数十万小时的速度持续增长。
此外,「通用操作模型」的数据方面,公司已经积累了10亿次的高质量全空间物体操作数据,并计划到2026年构建超过1万亿次的操作数据集。
 「具身世界模型」展示了机器人如何通过3D点云轨迹理解物理世界,但这只是故事的一部分。
「具身世界模型」展示了机器人如何通过3D点云轨迹理解物理世界,但这只是故事的一部分。
下一步是如何将这些想象轨迹转化为机器人手部精确的接触点、合适的力控和流畅的动作,并适配不同形态的机器人,这是未来研究的重要方向。
这些技术的应用将通过该公司研发的机器人本体产品实现,这些产品将是VLOA大模型技术的最佳载体,也是智能真正落地物理世界的最终形态。
模型不仅能识别物体,更能理解指令中的语义差异:对象是谁、动作是什么、意图有何不同。这是跨模态语义对齐与细粒度实例区分能力的体现。
模型生成机械臂将白色马克杯和装有食物的小绿碗分别放入橙色碗中的不同操作。

模型预测机械臂从洗衣篮中分别取出棕色衣物和荧光黄色衣物放入洗衣机的不同操作。

通过以上的可视化案例,其让世界模型从一个“黑箱”变成了一个可解释、可调试、可信赖的认知引擎。每个视频中的轨迹变化,都是模型内部思考的直接映射。
二、四大能力:让想象更真实
上述案例所展现的跨物体泛化、动态过程建模、指令跟随等能力,根植于模型内在的四项核心技术特性。这些特性确保「具身世界模型」不仅是“想象”,更是“可靠的想象”。
·物理约束满足:所有轨迹严格满足动力学、碰撞、稳定性等真实世界物理约束。倒水案例中,水壶倾斜角度与水流轨迹的匹配、水面的平稳上升,都体现模型对重力、流体行为的精准把握。这是2D视频生成无法做到的——2D世界没有重力方向,而我们的模型在三维空间中真正“理解”物理定律。
·原生支持物理多解性建模:真实世界充满不确定性。本方案利用扩散模型的生成特性,在潜在空间内构建物理演化的概率分布,从而能够推演出同一任务下多种合理的轨迹方案。这种对不确定性的建模能力,为具身智能在复杂场景下的决策安全性提供了坚实的底层支撑。
·长时序空间一致性:在复杂多步骤任务中,模型能保持预测状态在时间和空间上的全局连续。倒水视频长达数秒的预测中,物体相对位置始终合理,没有幻觉。
·硬件解耦:模型核心与具体机器人结构解耦,生成的规划可无损迁移至任何形态机器人本体——无论是机械臂、人形机器人还是灵巧手,都能理解同样的物体轨迹。
正是这四项核心技术特性,让「具身世界模型」的每一次“想象”都有据可依、有律可循。
「具身世界模型」的能力也会随着训练次数的迭代持续进化。下图展示了模型在预训练过程中,随着训练次数的增加,模型能力在多个关键指标上的提升。
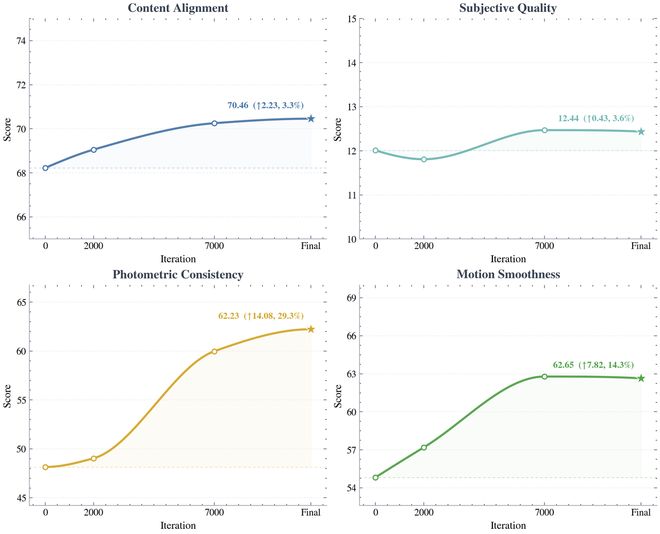
▲模型训练迭代过程中的指标变化趋势,Content Alignment、Subjective Quality、Photometric Consistency和Motion Smoothness在微调过程中均持续提升。⭑表示最终checkpoint,标注给出了最终分数及其相对初始模型的提升幅度。
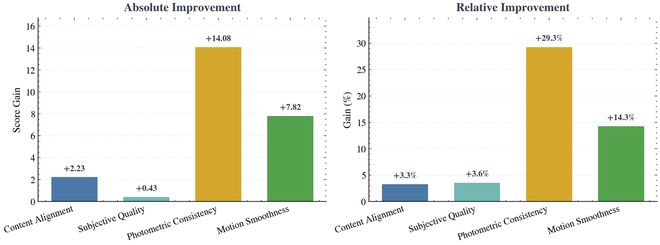
▲从基础模型到最终 checkpoint 的性能增益,左图表示各指标的绝对提升,右图表示相对提升百分比。Photometric Consistency 的提升最大,其次是 Motion Smoothness。
可以看到,投喂的数据和投入的算力越多,模型对物理世界的理解就就越精准,生成的未来轨迹就越贴近真实。
这正是具身智能领域的Scaling Law——模型的成长性是可预测、可持续的。随着我们以每周数十万小时的速度持续扩充视频数据集,世界模型的能力将持续进化,为机器人提供越来越可靠的“想象空间”。
而在完整VLOA架构中,具身世界模型扮演“认知大脑”角色——理解物理世界、预测物体状态、生成可执行的3D点云轨迹。这个轨迹通过Object Trajectory(物体轨迹)接口,传递给下一个核心模块:通用操作模型。
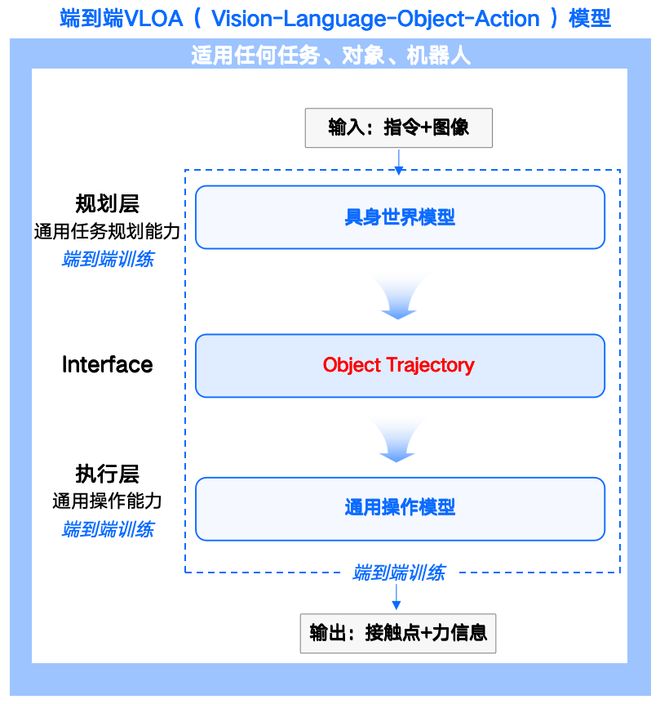
值得一提的是,支撑两大模型持续进化的底层基石,是规模与质量并重的数据体系。
该公司通过全自动数据标注与清洗pipeline,从海量互联网视频中筛选与物体状态变化、物理交互相关的高价值内容,已累积超过100万小时高维多模态操作相关的视频数据(上千万video clips),并以每周数十万小时的速度持续增长,目标是到2026年底构建千万小时级的全球领先视频数据集,为「具身世界模型」的持续进化提供不竭燃料。
同时,在「通用操作模型」数据方面,其基于自研的多模态物理引擎,已积累10B(100亿次)高质量全空间物体操作数据集,目标是到2026年构建超过1T(1万亿次)的操作数据集。
今天,其展示了具身世界模型如何用3D点云轨迹打开物理认知的黑箱。但这只是故事的一半——如何将这些想象轨迹转化为机器人手部精确的接触点、合适的力控、流畅的动作?如何适配不同形态机器人?这正是 《VLOA系列解读(二):通用操作模型》 即将揭晓的答案。
而承载这些能力的,是该公司同步研发的机器人本体产品。它们是VLOA大模型技术的最佳载体,也是智能真正落地物理世界的最终形态。
