
新智元报道
Anthropic 最近正式推出了 Claude Opus 4.7,这次更新主要集中在复杂任务处理、高清图像理解和稳定的工作流程上。对于一般用户而言,最大的变化体现在更准确地遵循指令、更好地识别图片以及输出更加接近成品的结果。
本次发布的模型被认定为目前市场上最强大的实用型Claude版本之一。
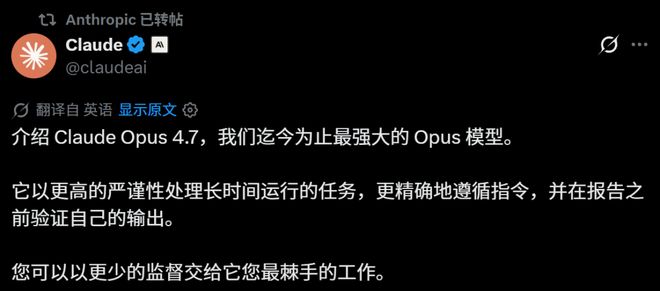
尽管新曝光的Claude Mythos Preview在性能上更为突出,但Opus 4.7相较于之前的Opus 4.6版本,在多数方面实现了显著提升。除了代理搜索能力略逊一筹外,其余部分均大幅超越了前代模型。
Anthropic 在本次更新中强调了复杂任务执行、更强的视觉识别能力和更稳定的长链路工作流程,并且大大减少了对人工干预的需求。
若用户仍在使用大型语言模型撰写文档、解读截图或准备演示材料,Opus 4.7带来的体验改进将不容忽视。

此次更新最引人注目的特点在于视觉能力的大幅提升。在测试中,从 Opus 4.6的大约 50%得分跃升至接近满分!
这项进步填补了AI目前最大的视觉识别短板,并可能已经悄然超过了人类工作的替代门槛。
GPT-5.4 Thinking 对于Claude Opus 4.7发布给普通工作者带来的影响进行了评价:

本次升级的关键
在于复杂任务的完成度
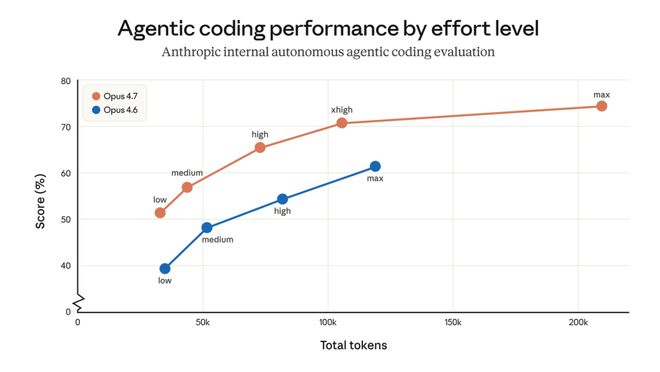
Anthropic 将Opus 4.7的核心改进点集中在高级软件工程和长时间任务执行上。用户可以将之前需要密切监督的复杂编码工作交给该模型处理,它能够更严格地遵循指令,并在返回结果前主动验证输出。
在官方发布的说明文档中,Anthropic 称其为当前最强的通用可用模型,适用于复杂的推理和代理式编程场景。
大型语言模型的竞争焦点已经从单纯的语言生成能力转向了任务完成度。仅能撰写一段漂亮的答案已不再足够。
是否能够完整地修订一份长文档、将一系列资料整理成可交付成果,或是在长时间内保持稳定表现不偏离主题,这些才是决定其能否在实际工作中替代人类的关键因素。
这些改进可以从Opus 4.7的官方发布重点中直接看出。
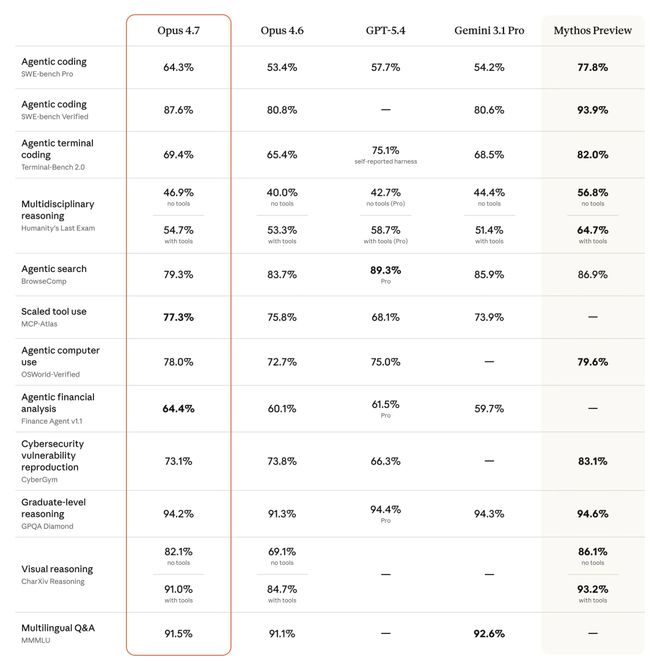
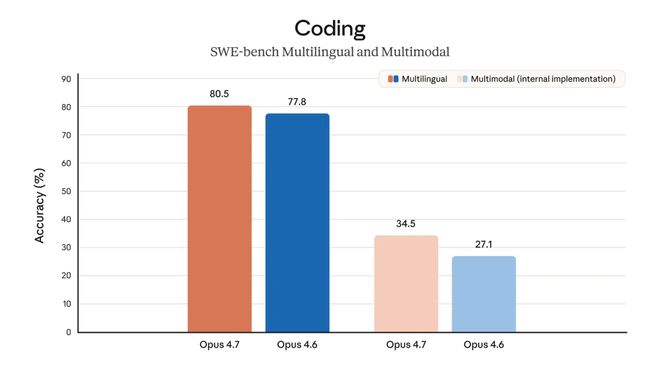
SWE-bench Multilingual 测试了模型修复真实GitHub issue的能力,并涵盖了多种编程语言。
纯编程只是开胃菜
Opus 4.7 拿下了80.5%的成绩,而Opus 4.6则为77.8%,增长了2.7个百分点。虽然单看这个数字似乎只是常规迭代的一部分,但同样图表中的另一组数据更引人关注。
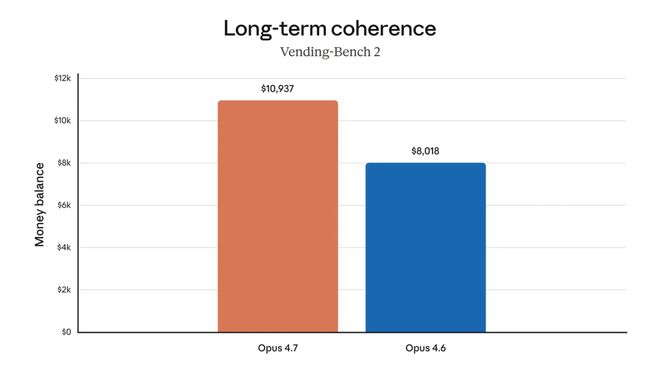
长任务下的表现
GraphWalks 是OpenAI设计的长上下文基准测试,使用边列表填充一张有向图以构建 1M token 上下文环境。模型需要完成从起点到特定深度节点的广度优先搜索(BFS),这对代理执行多步骤长时间任务是重要的考验。
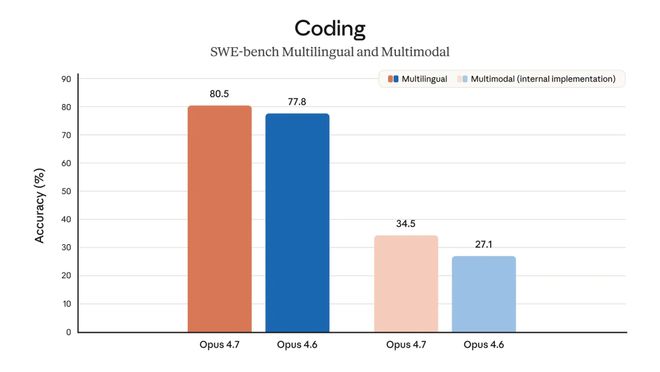
在 Parents 1M 测试中,Opus 4.7 的成绩从79%提升到了85%,增长了6个百分点;而在 BFS 测试中更是实现了巨大的飞跃,从30%跃升至74%!
这些成绩的显著进步表明 Opus 4.7 在长时间任务执行中的稳定性有了质的飞跃。
高分辨率图像识别能力也有所增强。Opus 4.7 支持最高达 2576 像素长边的图像输入,大约为375万像素,比此前版本提高了三倍左右。
官方特别提到,该模型在处理密集截图、复杂图表和精细结构图等场景下表现出色。
Opus 4.7 还改进了界面设计和幻灯片制作能力。它能更准确地跨多轮会话记住关键备注,并减少重复交代背景信息的需要,这使得模型在润色材料、整理项目以及反复修改同一内容时更加高效。
换个场景再看。
Anthropic 强调安全同样重要。Opus 4.7 集成了自动检测和拦截高风险网络安全请求的功能,确保用户数据的安全性得到保障。
合规安全研究人员还可以申请加入新的 Cyber Verification Program 进行进一步测试与验证。
安全评估结果显示,尽管 Opus 4.7 在一些细项上可能存在小幅走弱,但它整体仍保持“可靠且值得信任”的评价。这表明 Anthropic 并没有将其发布包装成一次毫无代价的全面跃升。
初步受益的人群主要是开发者、分析师、法务人员和研究人员等频繁处理文档、表格及演示材料的专业人士。
官方测试反馈中提到,复杂工作流更加稳定,错误恢复能力更强,文档推理、代码审查、数据分析以及长上下文任务都有了明显提升。
用户需要注意的是,更高分辨率图像会消耗更多 Token。当用户无需这些细节时,建议先压缩图片以节省成本。
Opus 4.7 还更新了分词器(Tokenizer),这可能导致相同输入内容的Token数量增加约1.0到1.35倍,并且在高努力度下输出的 Token 数量也会相应增长。
对于直接使用 Claude 应用进行聊天的一般用户而言,他们可能会感受到额度和响应体验的变化;而那些使用龙虾和Hermes Agent这类 API 的企业和团队客户则会面临实实在在的成本变化。
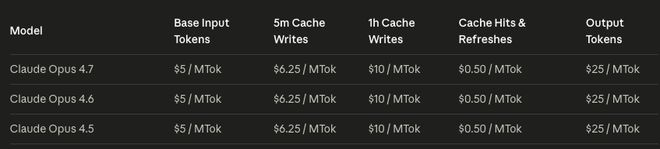
不过令人欣慰的是,Opus 4.7 和之前的版本一样,并没有涨价。然而,考虑到该模型本身已经相当昂贵,用户在选择时仍需谨慎考虑其性价比问题。
Anthropic 此次发布所传递的信息非常明确:他们正逐步将长任务执行、视觉理解能力、工具协同和少监督交付等几项核心功能打包成下一阶段大模型发展的主要战场。

除了官方公告外,Claude 还公布了长达232页的Opus 4.7系统卡,并提供了更多值得关注的新细节。受限于篇幅原因,我们在此不做进一步展开介绍。
对普通用户而言,最直接的感受是:交代清楚任务后,它能更好地完成工作、更精确地识别图片,并输出可以直接使用的成品内容。
大型语言模型正从会聊天逐步转变为能够实际工作的生产力工具。Opus 4.7 正是这一转变的重要一步。
这意味着真正强大且实用的生产力模型已经由 Opus 4.6 升级为更为先进的 Opus 4.7 版本。
Opus 4.7 的编程升级,重点是让模型看懂屏幕。眼睛换代了,脑子才能干更复杂的活。
GPT-5.4 和 Gemini 3.1 Pro 都没扛住
前面全是自比,现在来看看跟老对手们怎么打。
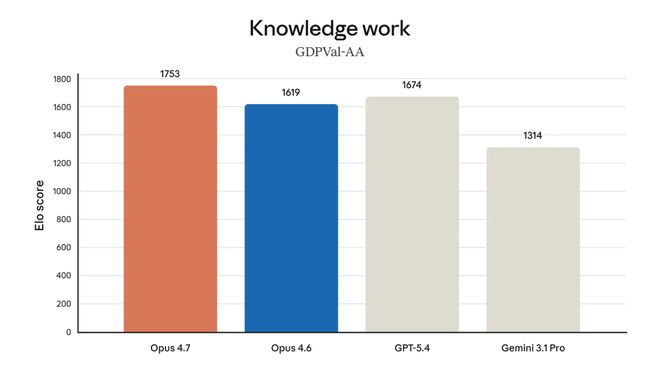
GDPval-AA 是 Artificial Analysis 基于 OpenAI GDPval 数据集做的评估。
它覆盖了 44 种知识工作职业、9 大 GDP 核心行业,任务来自资深职业人士(平均 14 年经验)的真实交付物。AA 版本让模型在 agent loop 里干活,用盲测两两对比打 Elo 分。
Opus 4.7 拿 1753,Opus 4.6 拿 1619,GPT-5.4 拿 1674,Gemini 3.1 Pro 拿 1314。
Opus 4.7 高出 GPT-5.4 79 分,高出 Gemini 3.1 Pro 439 分。
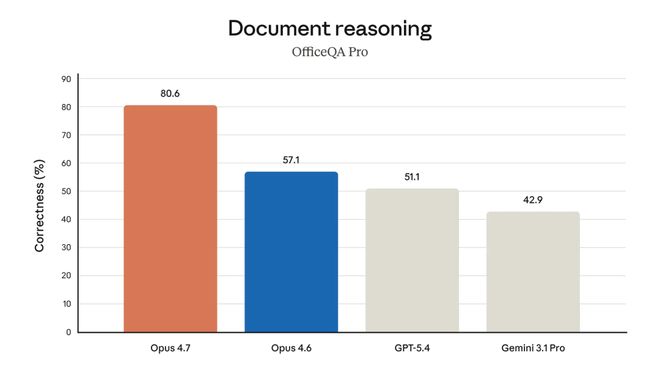
OfficeQA Pro 是 Databricks 做的企业级推理基准,语料是近 100 年的美国财政部公报,8.9 万页 PDF、2600 万个数字。模型要精准找到文档、解析表格和正文、跨文档做分析推理。
在这里,Opus 4.7 的跑分高达 80.6%,而 Opus 4.6 只有 57.1%,GPT-5.4 和 Gemini 3.1 Pro 更低,分别是 51.1%和 42.9%。
换句话说,Opus 4.7 是 GPT-5.4 的 1.6 倍,是 Gemini 3.1 Pro 的 1.9 倍。
跃升最炸的是生物学
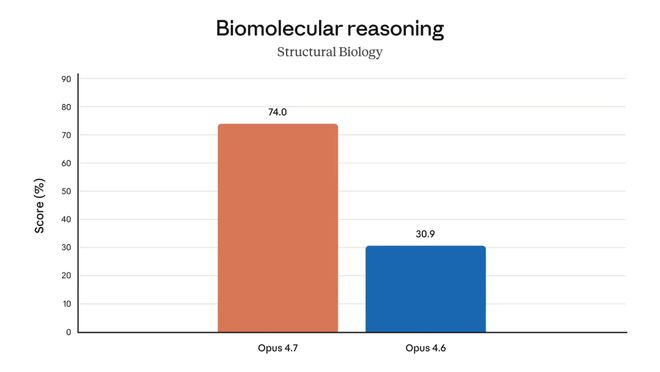
翻到最后一张,Structural Biology,生物分子推理。
Opus 4.6 只有 30.9%。而Opus 4.7 直接冲到了 74.0%。
一次版本迭代,从三成到七成半,2.4 倍。
堪称是所有 benchmark 里跃升最夸张的一项。
普通用户最先感受到的
是三大变化
第一个变化,指令遵循能力更强了。
Anthropic 写到,Opus 4.7 的指令遵循能力大幅提升,过去很多模型会松散理解、漏掉细节,Opus 4.7 则更倾向于逐条照着执行。
代价是,旧提示词有时会出现意料之外的结果,用户需要重新调整写法。
对普通用户来说,这会直接减少提示词玄学,写需求、定格式、列限制条件,会更有用。
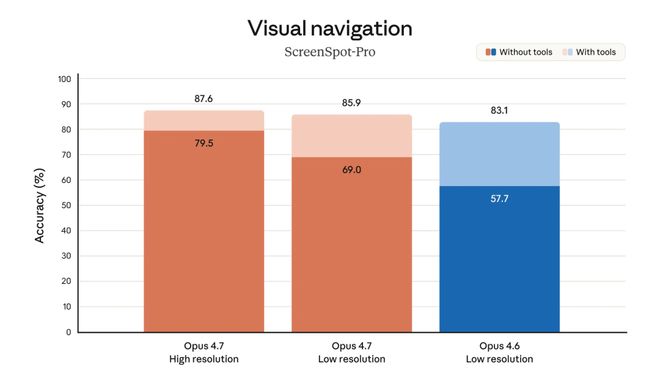
第二种变化,Claude 看图会更细。
Opus 4.7 支持长边最高 2576 像素的图像输入,大约 375 万像素,超过此前 Claude 模型的三倍。
官方专门点了几个场景,密集截图、复杂图表、精细结构图、需要像素级参考的任务。
放到现实使用里,这对应的就是看懂一页密密麻麻的数据截图,识别产品原型细节,从复杂流程图里抽信息,读一张高分辨率海报或报表时少丢细节。
第三种变化,输出结果会更容易接近可交付的成品。
Anthropic 提到,Opus 4.7 在界面、幻灯片、文档这些专业任务上更有审美,也更有创造性。
它在基于文件系统的记忆上做得更好,能跨多轮、多会话记住关键备注,减少重复交代背景。
对经常拿模型润色材料、整理项目、反复改同一份内容的人来说,这种提升会比跑分的提升来得更直观。
这次发布
安全也被摆在了同样重要的位置
Anthropic 在一周前刚刚公布 Project Glasswing,专门谈到了前沿模型在网络安全方向的风险与收益。
Opus 4.7 成了这套新思路下第一个公开部署的模型,官方强调,它的网络安全能力弱于 Mythos Preview,并且上线时带有自动检测和拦截高风险网络安全请求的护栏。
合规安全研究人员则可以申请加入新的 Cyber Verification Program。
从安全评估看,Opus 4.7 与 Opus 4.6 的整体安全画像相近,在诚实性和抵抗恶意提示词注入上更强,在某些细项上也存在小幅走弱。
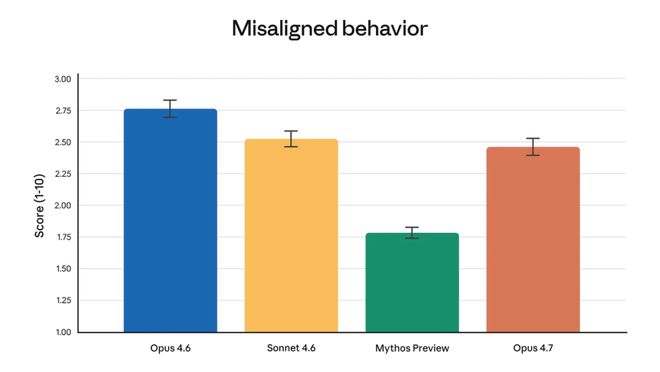
Anthropic 的结论是,它整体上「较为可靠且值得信任」,距离理想状态还有空间。
这说明,Anthropic 没有把发布包装成一次毫无代价的全面跃升。
谁会立刻受益
谁又要多留一个心眼
最先受益的人群很清楚,开发者、分析师、法务、研究人员,以及所有高频处理文档、表格、演示材料的人。
官方早期测试反馈里,很多合作方都提到同样几件事,复杂工作流更稳了,错误恢复更强了,文档推理、代码审查、数据分析、长上下文任务都有明显提升。

需要多留一个心眼的地方也已经写在官方说明里。
更高分辨率图像会烧掉更多 Token,用户用不到这些细节时,最好先压缩图片。
Opus 4.7 还换了分词器(Tokenizer),同样的输入可能会多出大约 1.0 到 1.35 倍 Token,高 Effort 下输出 Token 也会增加。
对直接在 Claude 应用里聊天的普通用户,这更多会体现在额度和响应体验上。
对使用龙虾和Hermes Agent这类API的用户和团队客户,这就是实打实的成本变量。
好在价格方面,Opus 4.7和4.6与4.5保持了一致,没有涨价,但这个价格本身其实就已经足够昂贵了...
Anthropic想传递的信号
已经很清楚了
从 Opus 4.7 这次发布能看出,Anthropic 眼下押注的方向已经很明确,长任务执行、视觉理解、工具协同、少监督交付,这几项能力正在被打包成下一阶段的大模型主战场。
官方同步上线的 Xhigh Effort(思考程度介于 high 和 max 中间)、Task Nudgets 公测,以及 Claude Code 里的 /ultrareview,也都围着这个方向在转。
除了官网公告外,Claude也公布了Opus 4.7的系统卡,长达232页,里面公布了更多值得关注的细节,限于篇幅再次我们不作展开。

对普通用户来说,对Claude Opus 4.7更直接的感受会是,交代清楚以后,它更容易把事情做对,看图更细,写出来的东西更能直接拿去用。
大模型从会聊天走向会干活,这一步又往前挪了一大截。
真正能干好活的最强生产力模型,从Opus 4.6,变成了Opus 4.7。
参考资料:
https://www.anthropic.com/news/claude-opus-4-7
https://x.com/claudeai/status/2044785261393977612
https://cdn.sanity.io/files/4zrzovbb/website/037f06850df7fbe871e206dad004c3db5fd50340.pdf