- 克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
长期困扰着使用OpenClaw用户们的那些烦人的网页抓取问题,现在有了新的解决方案。
这款名为Scrapling的工具,在很短的时间内就赢得了众多开发者的青睐,并成为OpenClaw的一个重要补充。
它不仅能够突破各种防爬机制,还能从复杂的网页中提炼出结构化的数据。
自发布以来一年多的时间里,这款项目突然间人气飙升,仅一天之内就在GitHub的流行趋势榜上拔得头筹,获得了超过2.3万的星标。
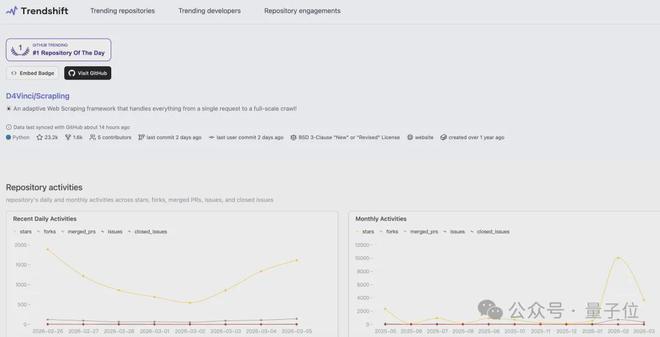
原作者已经表示将会把Scrapling集成到OpenClaw中,并期待它能进一步提升工具的功能性。
数据爬虫成了AI挂机神器
当智能代理在执行网络数据抓取时遇到需要人工干预的人机验证问题,往往会导致任务中断。
Scrapling内置的StealthyFetcher功能专门用于克服这类障碍。
它能够模拟现代浏览器的行为和标识符特征,使OpenClaw得以顺利绕过这些挑战。
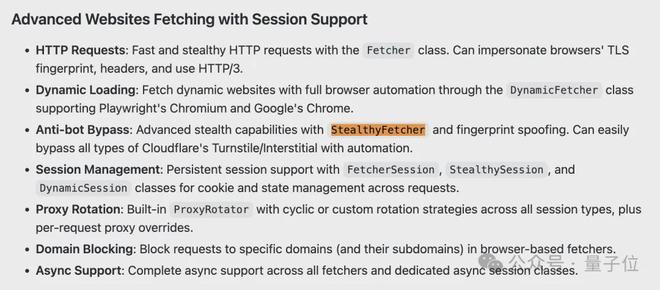
除了应对拦截措施,还需要处理网站频繁更新所带来的问题。
过去使用的爬虫工具往往过于僵化,一旦网页结构发生变化,它们就无法继续正常工作。
网页布局的变动会直接导致自动化流程崩溃,并且可能需要手动调整代码才能恢复任务运行。
Scrapling最突出的特点就是其智能自适应算法。
即使网站进行了大规模更新或改变了HTML结构,它的解析器仍能通过对比找到关键信息的位置并继续工作。
这种无需人工介入的追踪能力使得数据抓取任务可以全天候稳定运行,即使在深夜遇到网页更新也不再担心中断。
轻松上手,还能省钱
既然AI已经能像回自己家拿东西一样,顺溜地绕过拦截并搞定网页改版,那接下来的重点就是怎么更聪明地处理这些信息。
要更高效地处理收集到的数据,则只需启动Scrapling中的MCP模式即可。
这个功能会在向AI模型提供数据前,先行过滤掉无用的信息和广告内容。
因此减少了不必要的API调用费用,使得整个流程更为经济实惠。
此外,这款工具对硬件的要求非常低。
即便是在老旧的计算机或低成本服务器上也能流畅运行,占用内存极小。

并且它还具备断点恢复的功能,在网络中断或电源故障的情况下能够保存当前进度,并在条件恢复后继续执行任务,无需重新启动。
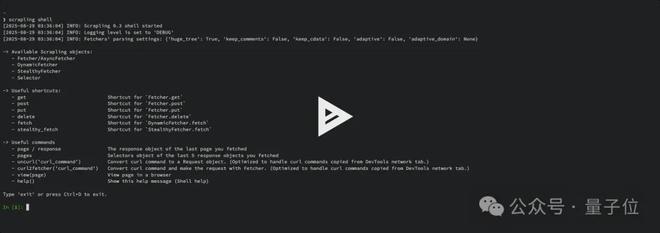
该工具不仅兼容各种设备,还为非编程人员提供了命令行界面,只需简单的指令就能激活其全部功能。
而且这个插件不仅不挑机器,也不挑人,不必会用Python写代码,它直接提供了一套开箱即用的命令行工具。
原作者计划将Scrapling整合进OpenClaw的Skill系统中,这意味着所有用户都能方便地为其智能代理添加强大的数据抓取能力。
再加上作者本人表示正在把插件做成龙虾的Skill,每个普通用户都有希望能轻松给自己的OpenClaw武装上一双看透全网、精准抓取数据的眼睛了。
项目地址:
https://github.com/D4Vinci/Scrapling