龙虾如今大受欢迎,人人都想尝鲜。但实际操作起来却会遇到第一个难题——
到底哪个模型最适合OpenClaw呢?
知道大家着急,龙虾之父亲自来支招了:可以关注一下因吹斯汀的榜单。
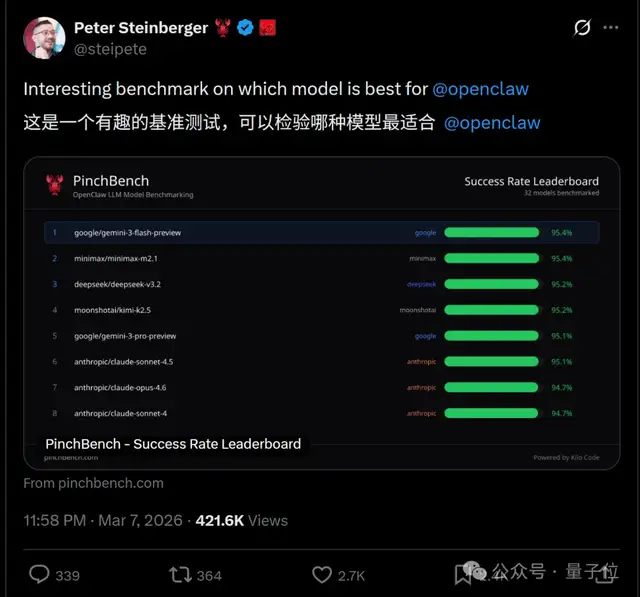
这个名为PinchBench的榜单专门为龙虾而设,它从成功率、速度和价格等方面评估全球大模型对OpenClaw的适应性。(值得一提的是,这个榜单还会定期更新。)
尽管该榜单早在今年2月底就已出现,但最近却热度陡增——
其中不仅有龙虾之父推荐的原因,更重要的是中国模型的表现尤为出色。(这引起了外国同行的注意。)

对于熟悉龙虾的人来说,选择合适的模型是一项重要任务。
毕竟,吃龙虾会消耗大量token费用,而且速度也不能太慢影响用户体验。
也就是说,每个人都在价格和效率之间寻找平衡点。
PinchBench的目标就是明确给出答案——它按照成功率、速度和成本这三个维度对全球模型进行排名,因此每个模型的强项一目了然。
截至发稿时,榜单的具体情况如下——
总体来看,在成功率和速度方面中国模型表现不俗,但在价格上略有不足。
在成功率方面,除了第一名是谷歌Gemini 3 Flash之外,第二名和第三名均来自国内。
- 第一名(Gemini 3 Flash):95.1%的成功率
- 第二名(MiniMax M2.1):93.6%的成功率
- 第三名(Kimi K2.5):93.4%的成功率
需要注意的是,尽管成绩显著,但MiniMax用的并非最新版模型。
(注:MiniMax M2.5在春节期间上线,宣称其目标是“让无限运行复杂代理在经济上可行”。)

在速度方面,国产模型MiniMax M2.5超越了Gemini和Llama等其他知名模型,位居榜首。
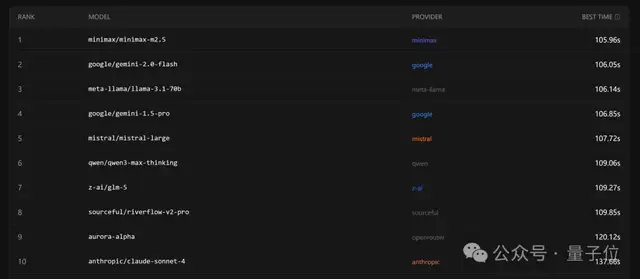
当时发布时,MiniMax M2.5在SWE-Bench Verified测试中,任务完成时间比前一代M2.1快37%,端到端运行时间为22.8分钟,与Claude Opus 4.6持平。
目前,Claude Opus 4.6的排名是第30位(而M2.1则是第22位)。
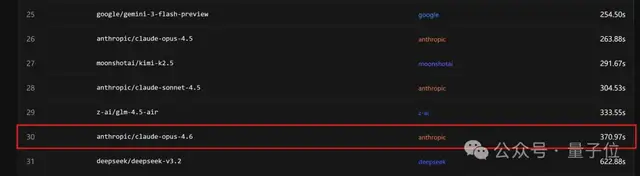
不过在价格方面,国产模型相较于OpenAI和谷歌等公司的产品显得稍逊一筹。
排名第一的是GPT-5-nano,其定价为每百万token输入费用0.05美元、输出费用0.40美元。
国产模型中价格最低的MiniMax M2.1则是输入成本约为0.3美元/百万tokens(即2.1元人民币),输出则为约1.2美元/百万tokens(即8.4元人民币)。
平均而言,后者的价格大约是前者的三倍。
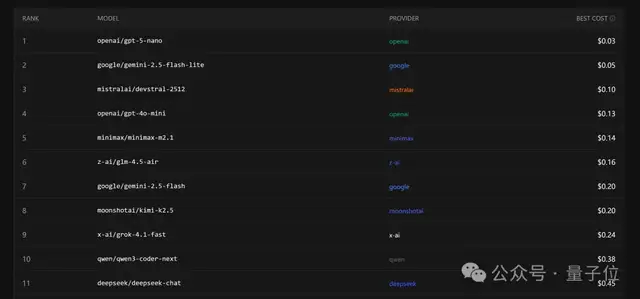
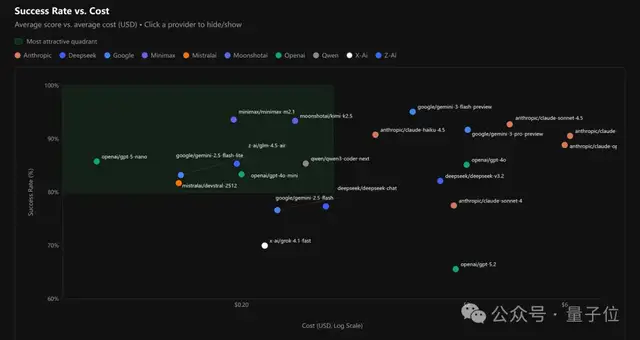
综合来看,若要在成功率和价格之间找到最佳平衡点,这张图表可以作为参考。
图表左上角框选出了八个不错的模型——其中四个是中国制造的。
总之,在这份专为龙虾而设的Benchmark中,国产模型的表现非常亮眼,并在某些单项测试中有卓越成绩。
那么问题来了,这个榜单是否可信?其背后的筛选机制又是什么?
让我们来了解一下PinchBench的相关信息。
简而言之,PinchBench并不是由某一家大公司推出的标准Benchmark,而是来自一个专注于Agent基础设施的创业团队。
该团队名为Kilo AI,由GitLab前联合创始人兼CEO Sid Sijbrandij投资并亲自参与创立。此前他们曾成功推出了风靡一时的“氛围编程”工具Kilo Code。
在年初龙虾热潮兴起后,他们顺势推出了基于OpenClaw构建的全托管智能体平台KiloClaw。
随着KiloClaw一同发布的还有一个智能体框架评测工具——PinchBench。
PinchBench的主要用途是测试不同大模型在实际工作流程中的执行能力,其定位更接近于“代理功能评估”,不同于传统的知识问答和数学推理等基准测试。
它不仅仅是看模型能否回答问题,而是要看它们是否能够完成整个任务。
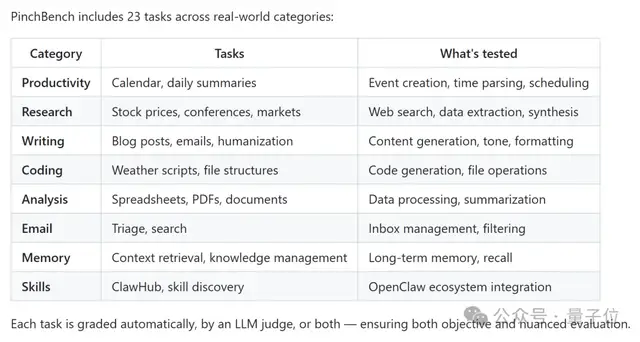
目前它大约包括23个真实世界的任务测试项目,例如但不限于:
- 查询并整理资料
- 写邮件或生成报告
- 调用API完成操作
- ……
在评分机制上,PinchBench采用自动化检查加LLM评审相结合的方式进行评估。
部分任务有明确的自动脚本执行标准;而另一些则需要通过LLM Judge来判定结果的质量。
最终统计的关键指标包括我们之前提到的成功率、速度和成本。
由于测试方式偏向于模拟实际工作流程,因此在PinchBench的排行榜上,你会看到一个有趣的现象——
大型模型并不总是占据优势地位。
这意味着那些优化了代理功能或提高了推理效率的模型排名反而高于传统的主流大模型。
正是这一点让PinchBench最近在行业内引起了广泛讨论。

需要注意的是,目前PinchBench仍然是完全开源的,用户可以在其平台上自行运行和添加新的测试任务。
如果未来大家不知道如何选择合适的模型,不妨亲自尝试一下。
PinchBench开源地址:https://github.com/pinchbench/skill