长期困扰人们的“调参”难题终于迎来了一线曙光!麻省理工学院的研究团队近日推出了一种名为RandOpt的新算法。
 一水
一水预训练模型其实早就埋藏着大量潜在的专家模型。
只需向模型中加入高斯噪声,其性能便可媲美甚至超越GRPO/PPO等传统调参方法。
这一新发现挑战了长期以来被广泛接受的观点。
很多人为了将预训练模型转化为专业领域的专家,夜以继日地进行复杂的参数调整。
现在,一对麻省理工学院的师生团队在他们的新论文中提出了一种新方法:
通过简单地随机调整参数,然后将结果整合,模型的性能可以和GRPO/PPO等专业调参方法相媲美,甚至更优。

在这篇论文之前,大家普遍认为专家模型是通过细致的训练过程逐步优化参数而来的。
无论是通过梯度下降还是强化学习,都需要精心设计和反复迭代。
但这篇论文揭示,专家模型其实早已存在于预训练模型的权重空间中,只是未曾被发掘。
这种现象被形象地称为“神经丛林”。

实际上,只要在预训练权重附近进行轻微的参数扰动,就有可能找到新的任务专家。
基于这一发现,研究者进一步提出了一种名为RandOpt的简单方法:
仅需向大语言模型中添加高斯噪声(这是一个单一操作,无需迭代、学习率或梯度),然后将这些模型集成起来,便能在数学推理、编程、写作和化学任务上取得媲美甚至超越GRPO/PPO的性能。
同时,他们还发现,模型越大,效果越好。

简而言之,论文表明:
预训练模型周围早已存在大量的“专家模型”。
在权重空间中,能够解决不同任务的模型并不是孤立分布的,而是密集地存在于预训练权重附近。
因此,在理论上,我们不一定需要复杂的训练过程,只要在这一区域进行多次尝试,就有可能找到表现良好的任务专家。
很多人可能会质疑:这不就是随机猜测吗?
一直以来,随机猜测被认为是不可靠的机器学习方法,比如随机猜测ChatGPT的参数向量,其概率几乎为零。
但论文指出,对于预训练模型而言,情况不同——
没错,还真就是靠猜。
在模型权重附近,能够提升任务性能的参数扰动变得非常密集,因此随机猜测也能找到有效的改进方案。
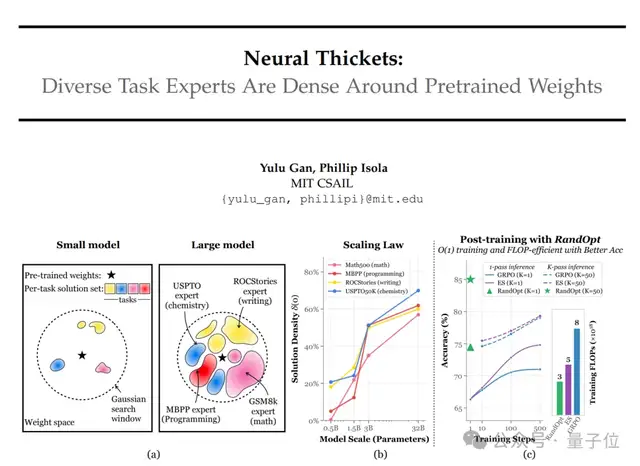
在实验中,作者对预训练的Qwen2.5模型(0.5B~32B)进行了1000次随机权重扰动,并通过随机投影将其映射到二维平面。
结果显示,模型越大,周围“高精度区域”越密集;小模型扰动后大多性能下降(蓝色区域),而大模型周围随处可见性能提升的“专家”(红色区域)。

换句话说,模型越大,这种扰动的效果越显著。
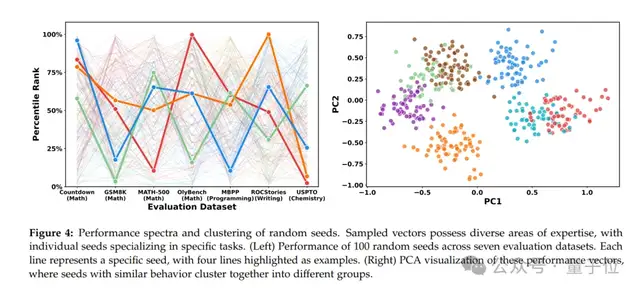
同时需要注意的是,这些随机扰动最后带来的并不是全能选手,而是“偏科战神”。
实验表明,没有任何一次随机扰动能让模型在所有任务上都实现提升。例如,某个扰动能让模型在数学上表现更佳,但在编程上却退步;另一个扰动能让模型在化学上表现出色,但在写作上却表现不佳。
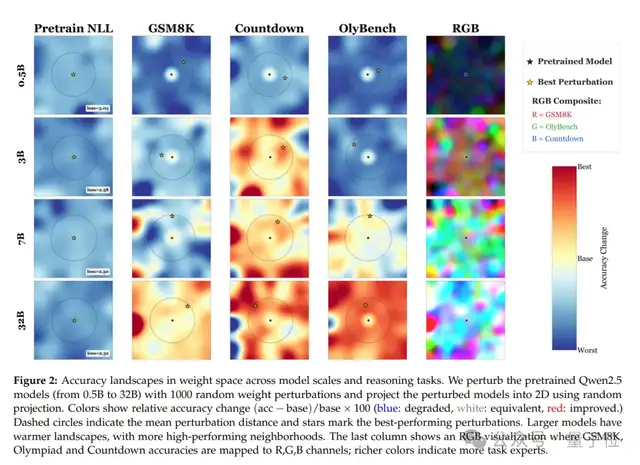
并且随着模型规模的增大,这种偏科现象更加明显。
对于这种“周围隐藏着众多高手”的现象,论文也提供了一个初步的解释。
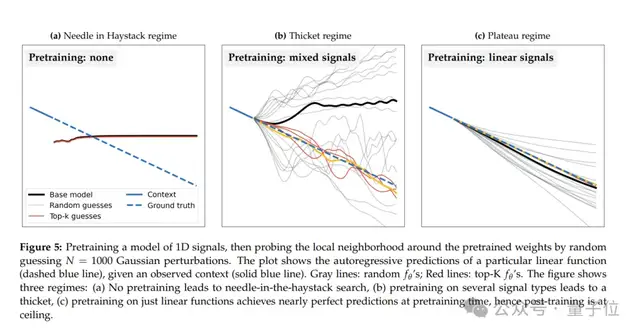
他们选择了结构最简单的1D信号自回归模型,让其学习预测一段时间序列信号的下一个数值。
未进行预训练时:不论如何添加扰动,模型周围都找不到可以提升性能的改动,随机猜测无意义;
单一任务预训练时:模型只能做到经过预训练的任务极致,参数周围不会出现其他优质改动;
结果出现了三种情况:
- 多任务混合预训练时:模型参数周围瞬间布满能提升性能的扰动,随意添加一个小改动,就能解锁擅长某种信号预测的专项能力,成功复刻“神经丛林”的密集状态。
- 由此得出结论,“神经丛林”现象的产生,关键在于大模型的海量多任务预训练。
- 换句话说,正是因为模型基础扎实,所以周围很容易找到可以随机扰动的“专家”。
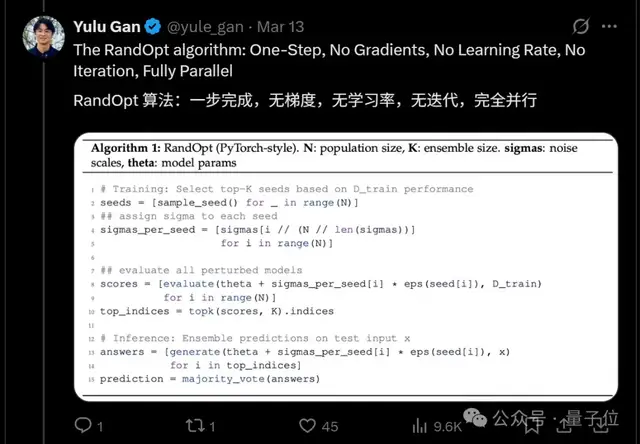
这项研究还启发了RandOpt算法的提出。
RandOpt的运作机制可以分为两步:随机搜索和投票。
“随机搜索”类似于前面提到的方法,给预训练模型的参数做N次随机扰动,然后得到N个“新版本模型”。
接下来用少量的验证数据简单测试这些模型,找出其中表现最好的K个。
拿到这K个模型后,进入实战推理阶段——
让这K个“高手”各自回答问题,最后按“少数服从多数”的原则决定最终结果。
整个过程有两个值得注意的方面:
一是RandOpt在添加扰动sigmas(即噪声强度)时,会尝试不同强度的噪声(如小扰动、中扰动、大扰动),以确保能找到各种类型的专家。
二是这N个模型可以同时在多块GPU上运行,速度非常快。
当然,论文也测试了不同模型对于这一新算法的效果。
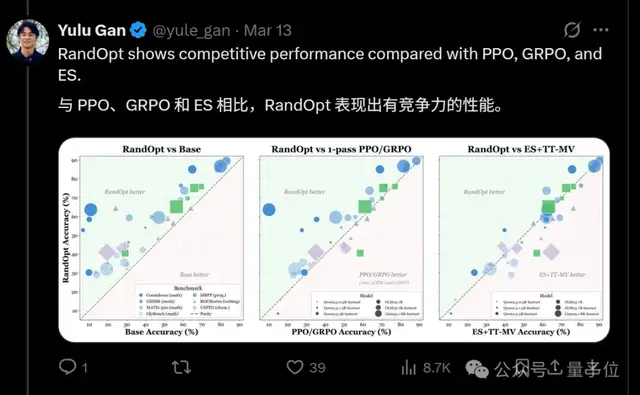
初步结果显示,对于纯语言大模型,在数学、编程、写作和化学任务上,RandOpt的准确率和现在主流的专业调参方法(PPO/GRPO/ES)差不多,甚至更高。
对于视觉-语言模型,RandOpt的提升作用更为显著,准确率直接从56.6%上升到69.0%。
同时,除了语言和视觉-语言模型,论文还在图像扩散模型中观察到了类似的“神经丛林”现象——
参数空间的某些特定区域会倾向于生成具有特定色调或视觉风格的图像。
论文作者也提醒,RandOpt在以下情况下效果更佳:

随机扰动次数越多,所选“高手”越强;
模型越大,RandOpt效果越好。

最后介绍一下这项研究的两位作者。
- Gan Yulu,北京大学工程硕士,现为麻省理工学院计算机科学与人工智能实验室(CSAIL)博士生。
- 他曾实习于微软,研究方向主要包括多模态大语言模型、推理、多智能体系统以及AI for science。
论文作者介绍
另一位作者Phillip Isola是他的导师,目前是麻省理工学院电子工程与计算机科学系副教授。
Phillip Isola在加州大学伯克利分校完成博士后研究后,曾在2017年以技术人员的身份加入OpenAI。
不过不到一年时间,他又去谷歌担任了一年的访问学者。

再后来,他回到了母校麻省理工学院任教。
Phillip Isola的主要研究方向为AI基础理论和计算机视觉,曾提出pix2pix、LPIPS感知损失等经典工作,谷歌学术论文被引用量超过10万次。
通过这项研究,师徒二人想向大家传达一个新观念:
是时候重新审视预训练模型了,它不仅仅是“一个可用的模型”,更是“众多专家的集合”。
只要预训练做得足够好,后续不需要复杂的调参,像RandOpt这样简单随机调整和投票即可,节省时间和计算资源。
当然,这种方法也有明显的缺点:
它依赖于高质量的预训练,这是一个基本前提;
模型只能基于预训练数据寻找改进,无法学会新技能;

K值越大效果越好,但推理时需要运行K个模型,虽然蒸馏可以缓解,但并不适用于所有场景(如生成任务);
- 只适合有明确答案的任务,像写故事、设计分子这样的结构化生成任务,还需要进一步改进集成方式。
- 目前,相关论文和代码已公开,有兴趣可以继续关注。
- K越大效果越好,但推理时要跑K个模型,虽然蒸馏能缓解,但蒸馏不适用于所有场景(比如生成式任务)。
- 只适合有明确答案的任务,像写故事、设计分子这种结构化生成任务,还需要进一步改进集成方式。

目前相关论文和代码已公开,感兴趣可以继续关注。
论文:
https://arxiv.org/pdf/2603.12228
GitHub:
https://github.com/sunrainyg/RandOpt
项目主页:
https://thickets.mit.edu/