
在两个月前举行的 CES 展会上,英伟达创始人黄仁勋宣布开源了公司的首个 VLA(视觉-语言-动作)模型,并且预告物理 AI 的「ChatGPT 时刻」即将到来。
现在,物理世界的 AI 正在成为一个重要的发展趋势:从机器人到辅助驾驶系统,越来越多的企业正尝试使用 VLA 模型来革新机器与现实世界互动的方式。
在自动驾驶领域,端到端的 VLA 方法已经经过了大量的测试和验证,并取得了前所未有的成果。然而,这种架构面临着一个内在挑战:作为中间层的语言难以完整准确地表达出物理世界的每一个细节。李飞飞曾在一次访谈中指出,“语言只是对现实的一种有损描述。”
在需要实时理解环境并生成驾驶决策的自动驾驶环境中,通过使用语言这一中间环节来表述物理世界可能会引入信息损失,并增加额外的推理路径。随着驾驶场景复杂度的提升,这种架构缺陷限制了系统准确率与效率的进一步提高。
针对这个问题,小鹏汽车提出了一种创新解决方案:直接跳过“语言翻译”步骤,在行业内首次实现了从视觉信号到动作指令的端到端生成过程。这是该公司在去年 11 月发布的第二代 VLA(XPENG VLA 2.0),并在随后几个月内完成了多次更新。
这项新技术迅速带来了质的变化:在 3 月初举办的「小鹏第二代 VLA 媒体体验日」上,何小鹏宣布该技术将于本月开始推送。

大家普遍预测,2026 年将成为“物理 AI 元年”。而小鹏汽车推出的第二代 VLA 技术,则为实现完全自动驾驶提供了首个“中国答案”。
跨代级的驾驶体验
在实际体验上,第二代 VLA 的提升主要体现在三大方面:安心舒适、全场景适应能力和高效率
由于端到端模型的泛化能力,小鹏汽车开发的第二代 VLA 已经能够准确识别各种形状和大小不同的车辆。

即使是在对面来车发生交通事故的情况下,VLA 系统也能够正确地识别障碍物及阻碍路线的车辆,并进行实时路径规划。

在确保安全性和流畅性的同时,小鹏第二代 VLA 成为了真正意义上的“全场景辅助驾驶”,支持从停车位、P 挡启动等多种环境下的激活操作,覆盖了园区小路、乡村土路以及没有导航的道路等复杂路况。
在拥挤且复杂的停车场内,该系统能够自动漫游直至你离开车辆前的每一个角落,并让你有足够的时间设置好导航路线,从而开始正式行程。

这意味着从按下启动键那一刻起,AI 系统就能接管驾驶任务,真正实现了从家中的停车位到公司车位全程无缝衔接。何小鹏表示,全场景辅助驾驶能力将在年内推出,在所有情况下都能达到类似主干道上的高水平表现。
第二代 VLA 的通行效率也有了显著提升,据实测数据显示,在保证安全的前提下综合行车效率提高了约 23%。尤其在城市晚高峰等复杂路况下,其通行效率甚至超过了传统的 L2 智能驾驶和 Robotaxi。
基于这些能力的展现,第二代 VLA 的使用门槛大幅降低。何小鹏强调,好的技术应该让每个人都能轻松上手使用,就像乘坐电梯一样简单便捷,做到易于操作、安全且实用。
尽管体验极其简便易用,并不代表其背后的技术只是简单的修补工作。实际上,第二代 VLA 的开发是对底层技术架构的一次彻底重建和创新。
重新构建技术基础:原生多模态物理大模型
面向 L4 目标,小鹏汽车自几年前就开始着手研究端到端智能驾驶的完全重构工作。
小鹏公司为将自动驾驶推向物理 AI 的核心本质,创建了一套完整的流程能力体系。其中第二代 VLA 作为关键技术基础,是实现高阶自动驾驶的关键所在。
相较于传统的 VLA 模型,小鹏的第二代 VLA 去除了通过视觉感知获取环境信息后再转化为基于语言推理步骤的过程,并直接生成车辆行动指令,实现了架构上的重要升级。
采用端到端的“视觉-动作”(Vision-to-Action)框架后,该系统可以直接将环境感知转变为驾驶决策,极大提升了整体效率并加快了响应速度。
第二代 VLA 可以概括为:一个统一模型贯穿环境感知、场景推理及行动决定的过程,实现了“感知—推理—行动”的一体化操作。
在感知层面,通过原生多模态 Tokenizer 技术打破了不同模态间的壁垒,实现了视觉、语音和文本的统一编码与融合,对物理世界形成了全面理解。
推理方面,则采用超密集的视觉思维链(Visual CoT),提升了复杂场景下高效推理的能力,其效率相比传统 CoT 提升约 32 倍。同时预测误差也减少了 33%,增强了系统对复杂驾驶环境的理解与决策能力。
在行动环节中,则直接生成包含语音、视觉反馈以及具体行为和动作的多模态输出。

小鹏通用智能中心负责人刘先明
另外,小鹏汽车还联合北京大学提出了一种全新的视觉 token 剪枝框架 FastDriveVLA。该技术能使 AI 类似于人类驾驶员,在复杂路况下忽略路边广告牌和其他无关信息,专注于核心道路情况分析。
通过使 AI 聚焦于关键信息并过滤掉无用数据,此方法有效地解决了自动驾驶模型 VLA 在处理高帧率图像时面临的计算量问题。相关研究成果已被人工智能顶级会议 AAAI 2026 接收。

论文地址:https://arxiv.org/pdf/2507.23318
当然,构建强大的 AI 基础是关键的第一步,在复杂的物理世界中实现 L4 级别的辅助驾驶还需要依赖于其他几个核心因素。
能力公式重塑:模型 × 算力 × 数据 × 物理实体
小鹏公司认为,第二代 VLA 的突破不仅仅是单一能力的提升,而是遵循了 L4 能力等同于“模型 × 算力 × 数据 × 本体”的规模法则。
实际应用证明,仅仅堆砌通用芯片算力或追求大参数量模型往往会在实际部署时遇到瓶颈。真正的能力壁垒需要在算法、硬件和数据方面进行全面优化。
在训练 AI 的过程中,必须构建起强大的数据飞轮机制,以充分利用视觉数据的高密度信息价值。
一个值得注意的数据对比是:目前全国数字 AI(主要指各种大语言模型)的日调用量约为 0.737 万亿 Token,而小鹏搭载第二代 VLA Ultra 的车辆每天消耗高达 58.8 万亿 Token——相当于全国所有数字 AI 日调用量的近 80 倍。
目前,小鹏已经积累了超过 50PB 的训练数据,并且每秒处理高达 53 亿字节的视觉数据。

最后,这一切都依赖于强大的 AI 基础设施,并通过世界模型仿真训练实现闭环。
自去年科技日以来,在半年时间里小鹏完成了 468 次模型版本迭代。

针对现实中难以穷尽的各种边缘情况(Corner Case),小鹏引入了世界模型进行闭环仿真。目前其仿真场景库已从一年前的三万个激增至五十多万个,每天在虚拟环境中通过强化学习方式进行“自我博弈”,等效于完成 3000 万公里实车测试。
小鹏第二代 VLA 是基于端到端 AI 算法、定制芯片高度整合,并由海量数据和世界模型知识共同构建的超级物理 AI 生命体。
随着新一代 VLA 智能驾驶技术的发展,物理 AI 的实力正在逐步显现出来。
何小鹏表示,基于端到端模型的辅助驾驶能力将成为未来三年内汽车行业的重要突破,并作为迈向完全自动驾驶的第一步。而在内部开发过程中,该技术正以前所未有的速度迭代更新。
对于一家汽车制造商而言,第二代 VLA 技术标志着小鹏在自动驾驶技术路径上的一次重要探索:不同于传统驾驶系统各个模块逐一优化的方法,它围绕自研基座模型打造统一的物理世界智能系统,具备理解真实世界并持续学习、演进的能力。
随着自动驾驶技术向 AI 驱动的智能时代迈进,这种全新的技术体系将有望成为其在未来竞争中占据主动权的关键变量。
此外为了应对现实世界中难以穷尽的 Corner Case,小鹏引入了世界模型进行闭环仿真。如今,其仿真场景库已从一年前的 3 万个激增至 50 多万个,每天在虚拟世界中进行基于强化学习的「自我对弈」,日均仿真测试里程等效于 3000 万公里的实车测试。
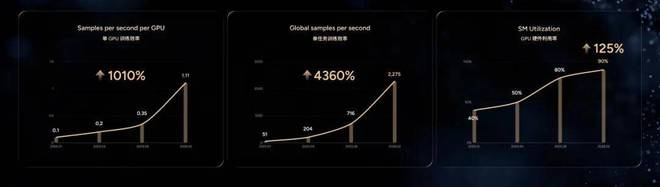
可以说,小鹏第二代 VLA 是一个基于端到端 AI 算法、定制芯片高度整合,由海量数据和世界模型知识共同构建的超级物理 AI 生命体。
结语
随着新一代 VLA 智能驾驶的出现,物理 AI 的实力正在逐渐展现。

何小鹏表示,基于端到端模型的辅助驾驶能力将会成为汽车行业未来三年的重要突破,它是面向完全自动驾驶的第一个版本。在小鹏内部,该技术正在以前所未有的速度迭代。
对于一家车企而言,第二代 VLA 是小鹏在自动驾驶技术路径上的一次重要探索:不同于传统驾驶系统各个模块(如感知、规划、控制)逐一优化的工程化思路,其围绕自研基座模型打造统一的物理世界智能系统,从而具备理解真实世界并持续学习、演进的能力。
随着自动驾驶技术加速迈向 AI 驱动的智能时代,这种技术体系势必成为其在下一阶段竞争中争夺主动权的关键变量。