在处理复杂的连续任务时,现有的生成式离线强化学习方法常表现出其局限性。
这些方法产生的路径往往陷入局部合理但全局失调的状态。
它们过于关注即时的步骤而忽略了最终的目标。

针对这一问题,厦门大学与香港科技大学联合提出了一种创新算法——MAGE(即“魔法师”,Multi-scale Autoregressive Generation)。
与传统序列生成方法不同,MAGE采用了自顶向下的递进生成策略,首先构建宏观规划模型,再逐步细化至微观层面。
这种方法的设计理念契合人类的直观逻辑:“从粗到细”的思路。
类似于绘画一幅素描画时,不会一开始就描绘细节如眼睛的睫毛,而是先勾勒出整个身体轮廓(即宏观规划),然后再渐进地细化五官和表情。
(微观动作)
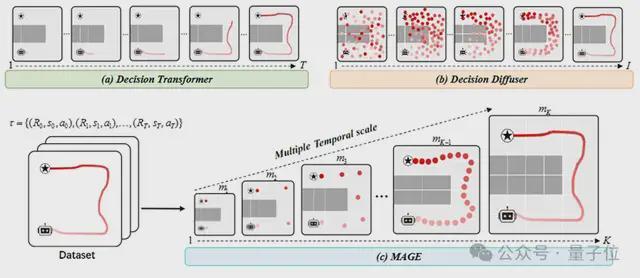
△MAGE的思考过程
一项名为“迷宫寻宝”的实验揭示了AI规划中的盲点
研究人员设计了一个迷宫吃金币的小型任务来直观展示现有模型的缺陷。智能体需要从随机起点出发,依靠对环境空间的理解,先吃银币再吃金币,最后到达终点。
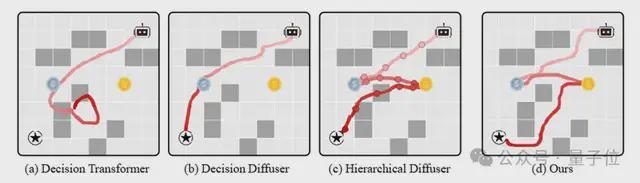
各种算法在迷宫中的表现
在这种需要全局规划的情境下,现有的大多数模型都暴露出明显的不足。
- Decision Transformer由于其单向自回归特性导致的上下文缺失问题,在长程规划中完全迷失方向,并且未能抵达终点。
- Decision Diffuser则因为扩散模型固有的局部生成偏差,虽然智能体最终到达了目的地,但路径规划中遗漏了一枚重要的金币,全局连贯性较差。
- Hierarchical Diffuser尽管尝试通过分层结构来建模全局轨迹,但由于其固定的双层架构过于僵硬,导致高低层次之间的策略协同效果不佳,生成的路径出现了物理违规的现象,局部动作与整体规划严重脱节。
相较之下,MAGE凭借多尺度“从粗到细”的生成架构成功完成了任务。它首先在宏观层面勾勒出所有关键节点的大致轮廓,再通过多尺度Transformer逐步细化至微观层次,最终顺利地规划出了完整的路径。
MAGE的核心理念:先画大体框架后添细节
为了实现“自顶向下、从粗到细”的生成方式,MAGE配备了两个核心模块,并辅以精确的控制机制:
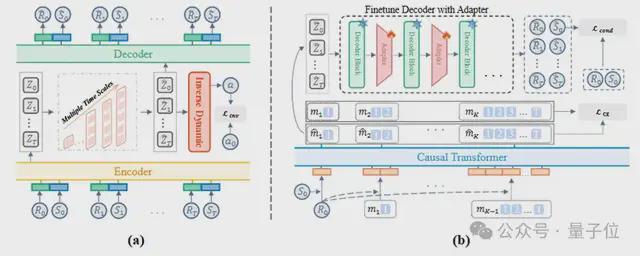
△MAGE的架构图
多尺度轨迹自编码器MTAE:该算法将长序列轨迹转化为多尺度离散Token。较粗的Token用于把控整体结构,而最精细的Token则关注于短期动态细节。
条件引导下的多尺度生成过程:模型通过Transformer顺序生成这些多尺度Token,并在每一步都严格依据“目标回报”和“初始状态”的条件进行约束,确保智能体始终朝着最终目标前进。
适应器模块与条件引导细化机制:由于连续世界的转换会导致信息丢失,普通的生成流程容易使轨迹起点偏离现实。因此,MAGE在解码过程中集成了轻量级的适配器,并引入了条件引导损失函数Lcond,确保解码出的状态能够精确对齐真实环境。最后,通过潜在逆动力学模型来决定最终的动作。
实验结果显示:长序列任务全面超越基准,推理速度满足实时控制要求
研究团队在Adroit、Franka Kitchen等五个离线RL测试环境中将MAGE与15种具有代表性的基线算法进行了广泛对比评估。
多任务表现出色
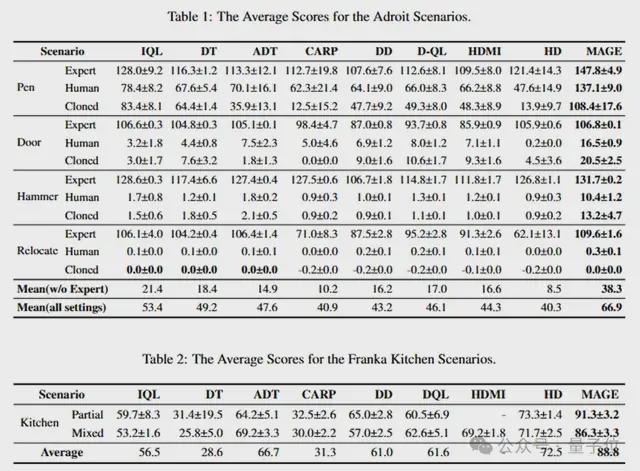
在极具挑战的高维连续控制任务中,面对极其稀疏奖励的情况,MAGE取得了显著的性能提升,并大幅度超越了所有比较方法。在强调子目标执行顺序的任务中,MAGE凭借其捕捉全局结构和细节的能力,以明显的优势胜过其他算法。
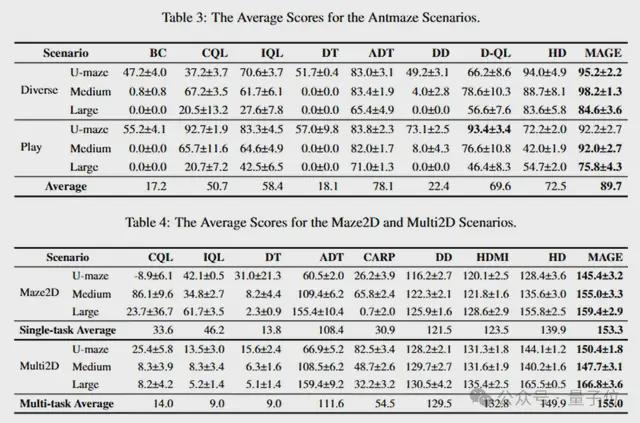
在迷宫导航实验中,MAGE在各个数据集中均表现最佳,证明了它处理长序列任务的优越能力。
出色的计算效率与部署潜力

MAGE不仅保持了高性能的表现,还实现了高效的计算资源利用。实验结果显示,相比Hierarchical Diffuser,其运行速度快约50倍;而与Decision Diffuser相比,则快80倍。每步推理时间控制在27毫秒以内,完全满足真实机器人控制系统所需的实时要求。
结语
MAGE成功整合了多尺度轨迹建模和条件引导机制,通过“从粗到细”的自回归框架生成连贯且可控的高回报路径。当机器人能够自主审视全局、制定长远计划并流畅执行时,也许具身智能将进入新的发展阶段。
论文链接:
https://arxiv.org/abs/2602.23770
开源代码:
https://github.com/xmu-rl-3dv/MAGE
实验室主页:
https://asc.xmu.edu.cn/
作者介绍:
本文第一作者来自厦门大学空间感知与计算实验室(ASC Lab)2024级硕士生林晨兴、2025级硕士生高鑫辉,通讯作者为厦门大学沈思淇副教授,并由张海鹏、李欣然(香港科技大学)、王海涛、梅松竹副研究员、刘伟权副教授(集美大学)、王程教授共同合作完成。研究团队长期聚焦于强化学习,多智能体系统以及大模型智能体。