
近来,清华大学智能产业研究院(AIR)与DISCOVER Lab联合多家企业推出了一种新的高通量视觉仿真器——GS-Playground。
该成果已被机器人领域顶级学术会议RSS 2026接收,证明了国内在具身智能仿真的基础设施建设上,在视觉真实度和训练效率两方面均取得了国际领先的突破性进展。

- 相关论文已发表于arxiv.org(编号:2604.25459)。
- 更多详细信息可访问其官方网站:https://gsplayground.github.io,并在GitHub上获取代码库:https://github.com/discoverse-dev/gs_playground。
- 为何选择GS-Playground?关键在于解决三大核心挑战
当前,具身AI研究正经历从“本体感知”向“视觉感知”的转变。机器人需像人类一样通过视觉来学习决策,这是学术界普遍认为的下一代技术路线。然而,在这一过程中现有仿真器面临了三个主要障碍:
首先,渲染成本过高。尽管现有的大规模并行仿真器(如Isaac Lab、ManiSkill和Genesis等)在物理模拟吞吐量方面表现出色,但一旦加入高分辨率的逼真渲染管线,GPU显存就会被物理仿真与渲染任务争夺殆尽,频繁导致溢出问题,迫使研究者不得不在画质和训练规模之间做出艰难抉择。
其次,仿真资产制作依赖大量人工。创建一个既具备高质量物理又具有高保真视觉的仿真环境通常需要大量的美术建模和工程调试工作。尽管3D重建技术已经成熟,但将其转化为“可仿真的”数字孪生依然是一项劳动密集型任务。
再次,Sim2Real迁移难度大。由于仿真画面与真实世界的视觉及物理特性存在差距,训练出的策略难以直接应用于实际机器人上,需要进行大量的视觉随机化和手动微调,从而增加了计算成本和技术复杂度。
GS-Playground的设计目标就是解决这些核心难题——大幅降低照片级视觉反馈的成本,使其从“强化学习训练的核心瓶颈”变为可以规模化应用的技术。
核心架构:物理引擎 × 批量渲染 × 资产流水线
GS-Playground的架构图展示了其独特的设计理念。
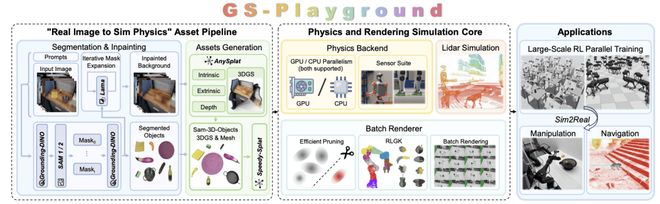
该平台并非简单地堆砌现有功能,而是从底层到上层进行了全面重新设计。它由三个主要层次构成:
自主研发的高性能并行物理引擎
GS-Playground采用了一种基于国产自研跨平台(Windows/Linux/macOS)并行物理引擎的技术路径,并支持CPU和GPU后端。
与其他主流方案(如PhysX、MuJoCo、Taichi)不同,该引擎为了提高几何精度而牺牲了梯度平滑性——能够模拟刚体的静态平衡状态,并且支持大时间步长仿真(dt=10ms),特别适合需要精确接触建模的操作任务。
在工程实现上,团队优化了两个关键方面:约束岛并行化和时间相干热启动。前者将约束图分解为独立子问题进行多核CPU并行求解;后者通过跨帧复用上一步冲量的方式大大减少了迭代次数(从50+次减少到不足10次)。在高密度场景下,GS-Playground的性能表现尤为突出,能够达到1,015 FPS的吞吐量。
在接触稳定性测试中,通过牛顿摆、Boston Dynamics Spot大步长稳定性测试和密集货架多体交互实验验证了引擎在复杂环境下的优越稳定性和精确性。
高效批量3DGS渲染引擎
GS-Playground采用了3D高斯泼溅(3D Gaussian Splatting, 3DGS)作为渲染方式,取代传统光线追踪或光栅化技术,并围绕其构建了优化吞吐量和显存效率的批量渲染后端。
核心设计包括三个关键模块:
高效点剪枝策略:保留约30%的高斯点而不会显著影响视觉质量,动态物体和机器人本体则进一步压缩至仅保留10%,从根本上解决了大规模并行训练中渲染与计算争用显存的问题。
刚体链高斯运动学(RLGK):将数百万高斯点绑定到物理引擎中的低维刚体状态,通过GPU批量向量操作在亚毫秒内完成同步更新,实现动态场景的零开销视觉更新。
- 单模板批量广播机制:仅需占用一份场景模板即可跨最多2048个并行环境进行传播,显著减轻了显存带宽的压力。
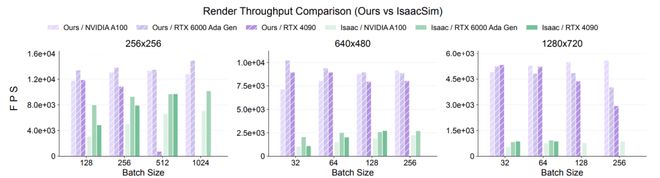
- 实验结果表明,在RTX 4090单卡上以640×480分辨率渲染2048个并行场景时,总吞吐量可达10,000 FPS。与Isaac Sim的光线追踪渲染器相比,在所有测试分辨率和多种GPU架构下都保持了显著优势。
- 完全自动化的Real2Sim资产流水线
GS-Playground提出了一套自动化“图像到物理”的流水线,解决了仿真资产制作的最后一公里问题。只需输入一张RGB图像即可生成完整的数字孪生场景:
RGB图像 → Grounding-DINO(开放词汇检测)→ SAM1/SAM2(实例分割)+迭代掩码扩张 → LaMa(背景修复)→ AnySplat(场景级3DGS重建)+ SAM-3D(物体级3DGS与Mesh重建)→ 深度对齐 + 尺寸校正 + Speedy-Splat剪枝 → 输出完整仿真资产
单张图像的端到端处理时间约为5分钟。基于Bridge-v2数据集,团队已经生成了配套的Bridge-GS数据集,为每个场景补充了3DGS表示、物体Mesh、6D位姿和相机参数。
全任务覆盖:操作、导航、行走的Sim2Real验证
GS-Playground提供了完整的多模态传感器栈,包括RGB相机、深度相机、三种类型的LiDAR(旋转式、固态、非重复扫描)、力/接触传感器及地形感知扫描。它是目前唯一基于3DGS表示并行LiDAR仿真的平台,并且其API兼容MuJoCo MJCF格式的完整子集,使现有项目能够轻松迁移。

团队在四类具身任务上进行了系统验证:
四足行走(Unitree Go2):利用1,024个并行环境,在十分钟内策略收敛,并成功部署到真实设备上实现了速度跟踪;
人形行走(Unitree G1):使用2,048个并行环境和全碰撞流形,23自由度的人形策略在大约六小时内达到稳定状态;
视觉抓取(Airbot Play机械臂):直接从RGB图像中学习端到端6自由度关节控制策略,在未经简化的真实环境中实现了90%的零微调成功率——相比之下,使用MuJoCo、ManiSkill3和Isaac Lab训练的策略在真实世界中的成功率为0;
视觉导航(Unitree Go2):采用分层强化学习架构,高层从第一人称RGB图像中学习目标搜索与导航决策,低层输出关节级控制信号,仿真训练后直接部署到实际Go2上完成定向导航。
- GS-Playground的核心价值在于重新设计了一整套面向视觉机器人学习的仿真实验平台。通过将照片级视觉反馈的成本降至可规模化应用的程度,它使得视觉强化学习首次达到了此前只有本体感知强化学习才能达到的训练规模。
- 开源是GS-Playground的重要特点之一,团队表示未来将继续开源全栈框架及Bridge-GS数据集,并计划利用该平台为VLA(视觉 - 语言 - 动作)和VLN(视觉 - 语言 - 导航)模型合成大规模视觉训练数据。同时还将构建可扩展的机器人策略验证基准。
- 对于正在规划具身AI仿真基础设施的研究团队与工程团队而言,GS-Playground是当前开源项目中技术栈最完整且Sim2Real验证最为充分的一个平台之一。
- 视觉导航(Unitree Go2):采用分层强化学习架构,高层策略从第一人称 RGB 图像中学习目标搜索与导航决策,低层策略输出关节级控制信号,仿真训练后直接部署到真实 Go2 上,仅依靠机载摄像头即可完成目标导向导航。

意义与展望
GS-Playground 的核心价值在于:它不是某个单点技术的改进,而是一整套面向视觉机器人学习的仿真基础设施的重新设计。通过将照片级视觉反馈的计算成本降至可规模化的水平,GS-Playground 让视觉强化学习首次达到了此前只有本体感知强化学习才能触达的训练规模。
团队表示,GS-Playground 将完整开源全栈框架及 Bridge-GS 数据集。未来,团队计划利用该平台为 VLA(视觉 - 语言 - 动作)和 VLN(视觉 - 语言 - 导航)模型合成大规模视觉训练数据,同时构建可扩展的机器人策略验证基准。当前版本在动态光照处理和柔性体仿真方面仍有进一步提升空间,团队已规划整合粒子动力学(PBD/MPIM)与高斯泼溅的技术方案来支持非刚性交互场景。
对于正在布局具身 AI 仿真基础设施的研究团队与工程团队而言,GS-Playground 是当前开源方向上技术栈最完整、Sim2Real 验证最充分的平台之一。