周四,谷歌宣布推出Gemma 4系列开放权重模型,旨在为AI智能体和编程环境提供优化支持,并采用更为宽松的Apache 2.0许可协议,以吸引更多企业用户。

这一举措恰逢中国大语言模型快速发展之时。目前,多家中国企业如月之暗面、阿里巴巴千问等已推出多款性能优异的大规模语言模型,与国际头部产品形成竞争态势。
针对日趋激烈的市场竞争环境,谷歌通过Gemma 4向企业客户提供了安全可控的本地化部署方案,并明确承诺不会利用企业的敏感数据进行后续模型迭代训练,以此作为核心卖点解决客户的数据安全担忧。
作为DeepMind团队的最新成果,Gemma 4在数学运算和指令遵循能力方面进行了大幅提升,并引入了“高级推理”机制。此外,其应用范围得到了显著扩展,不仅支持140多种语言以及函数调用,还具备处理音视频等多模态输入的能力。
谷歌此次提供了多个不同参数规模的模型版本,以适应从单板计算机到企业级数据中心等多种硬件配置的需求。这一策略延续了以往的分级策略。
其中最大的一款是拥有310亿参数的大语言模型,在微调后可以提供同系列中的最佳输出质量。
这一规模既避免了与谷歌自家大型闭源模型之间的内部竞争,又保证了一定程度上的轻量化特性,使得企业在本地运行或微调时无需投入过多的GPU服务器成本。
计算能力要求的显著降低是此次更新的一大亮点。据谷歌介绍,该系列中16位未量化的版本可以在单块80GB显存的H100显卡上运行;而通过使用4位精度并结合Llama.cpp或Ollama等框架,在24GB显存的消费级显卡(如英伟达RTX 4090或AMD RX 7900 XTX)上也可以部署。
针对低延迟场景,Gemma 4系列推出了一款采用混合专家架构的模型,其参数规模为260亿。在推理阶段,仅激活128个专家网络中的子集(约38亿激活参数),从而提高处理效率和生成词元的速度。
虽然这种机制可能会对输出质量产生一定影响,但在受限于显存带宽的设备上,“以速度换质量”的策略具有重要的实用价值。
值得注意的是,上述两款主力模型均配备了高达25.6万个词元的超大上下文窗口,这使得它们非常适合本地AI代码助手的角色,并成为谷歌发布会上重点展示的应用场景之一。
为满足边缘计算设备的需求,谷歌专门针对智能手机和树莓派等低算力硬件设计了两款微型模型,其“有效参数”分别为20亿和40亿。这里所谓的“有效”,是通过逐层嵌入技术将物理参数量压缩至实际运行时的23亿和45亿级别。
尽管规模较小,这两款边缘模型仍支持高达12.8万个词元的上下文窗口及多模态功能,在特定版本中还能直接解析视觉与音频输入。
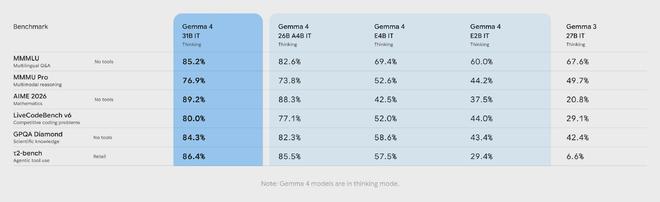
谷歌公布的数据显示,Gemma 4在各项核心AI基准测试中的表现相较于前一代产品均有显著提升。
此次发布还包括许可协议的重大调整。Gemma 4全面转向更为宽松的Apache 2.0许可协议,这为企业提供了更高的自主权,在部署和商业化应用时可以降低因条款变动导致的风险。
在生态系统方面,Gemma 4已上线谷歌自家AI Studio与AI Edge Gallery平台,并在Hugging Face、Kaggle及Ollama等主流开源社区同步推出。该模型自发布首日起便兼容vLLM、SGLang、Llama.cpp以及MLX等多种推理框架。
(本文由AI翻译,网易编辑负责校对)