
新智元报道
谷歌近日发布了首个原生全模态 Embedding 模型 Gemini Embedding 2,它实现了文本、图像、音频视频以及 PDF 的无缝整合,构成了一个统一的向量空间,显著提升了检索效率。
类似于生成式 AI 大模型在表达方面的功能(即“嘴”),Embedding 模型则扮演着理解和检索的角色,也就是负责记忆的部分。
过去,这种记忆机制一直处在分裂的状态之中。
Gemini API 已经上线了多模态 Embedding 预览版 gemini-embedding-2-preview。
作为首个原生全模态的 Embedding 模型,它成功地将各种类型的数据融合进了一个统一的空间内。
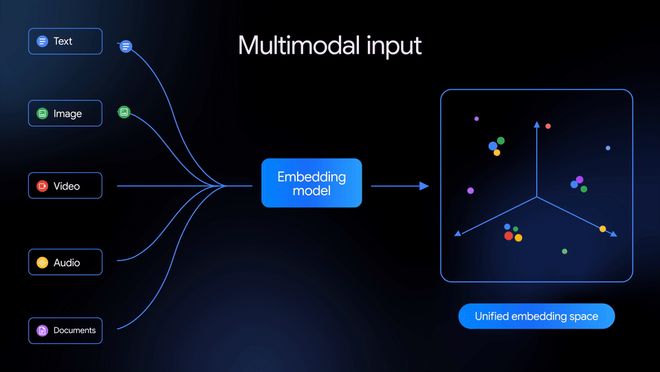
“原生”与“全模态”的概念所带来的变革意义
要理解这项技术的战略价值,我们需要认识到以前 AI 系统在数据检索方面所面临的问题。
在过去,不同的数据形式之间缺乏有效的沟通方式,每一次的信息传递都需要额外的转换步骤。
Gemini Embedding 2 的出现,则像是统一了所有数据类型的语言规则。
消除中间环节,减少信息丢失
“原生”的概念意味着直接处理原始数据,无需任何中间转化过程。
在早期阶段,为了让 AI 理解音频内容,需要先通过语音识别模型将其转化为文本形式,导致了大量细节的损失。
目前,该模型可以直接解析 MP3 文件以及高分辨率图片的数据结构,让那些难以用语言描述的信息找到了其在数学空间中的精确位置。
重构统一坐标系,实现跨模态搜索
当五种不同类型的数据被压缩进同一个向量空间时,它们之间的边界就变得模糊了。
开发人员可以轻松地构建复杂的检索功能:
输入一段机械故障的声音样本,系统可以在大量的 PDF 维修手册中迅速定位到相关的维修指南;
上传一张独特的建筑图片,系统能够准确匹配与之风格相仿的影视片段。
检索过程已经完全转变为基于语义和意图的匹配机制。
简化架构设计,降低工程难度
在过去构建一个跨模态检索应用是一项复杂的任务。
需要维护多个独立模型,并使用复杂的算法强行将不同类型的数据对齐,这种做法不仅效率低下而且容易出错。
现在,这一切都可以通过一次简单的 API 调用来完成,极大地简化了整个开发流程。
早期采用这一技术的开发者们已经对其给予了高度评价。

完整的记忆拼图
Agent 的表现通常不如人类,主要是因为它们缺乏统一的记忆系统。
在处理包含大量图表的研究报告时,Agent 往往只记住文字部分而忽略了视觉信息。
原生全模态 Embedding 赋予了 AI 一种连贯的认知模式,让机器能够像人一样无缝地融合不同形式的信息,形成完整记忆。
“五合一”引擎与成本优势
新模型支持多种类型的数据,并具备极高的处理能力:
- 文本:涵盖超过 100 种语言,上下文长度可达 8192 token;
- 视频:支持长达 128 秒的视频片段;
- 文档:原生读取多达六页的 PDF 文件。
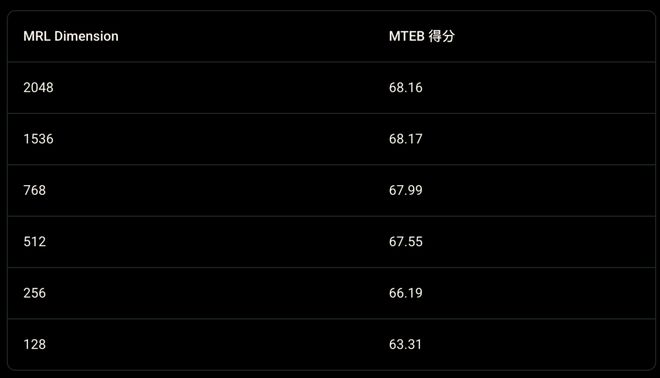
- Gemini Embedding 2 利用了一种称为“俄罗斯套娃”的表示学习技术,允许开发者根据实际需求灵活调整向量的空间维度。
- 即便在压缩后的较低维度(如 1536 或者 768 维)运行,其性能也能够维持在一个较高的水平。
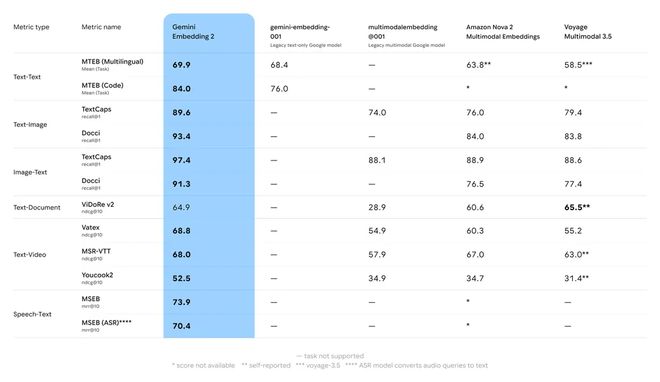
面对激烈的市场竞争,Gemini Embedding 2 凭借全面覆盖五大模态的数据处理能力脱颖而出。
相比之下,其他竞争对手的产品大多只能应对单一类型或者少数几种类型的数据挑战;
因此,Gemini Embedding 2 成为当前唯一能够满足多方面需求的商用级模型。
在尝试使用这款新工具时,有几个常见的问题需要注意:
兼容性断层。从旧版 gemini-embedding-001 升级到新版系统,需要重新编码和索引大量历史数据;
格式限制与时间长度阈值。目前音频文件仅支持 MP3 和 WAV 格式,并且最长不能超过 80 秒,对于较长的录音可能需要自行分割处理。
手动归一化操作。在调用低维度输出时(例如 768 维),开发者还需额外编写脚本进行 L2 归一化。
当数据孤岛被打破,现实世界的信息可以更清晰地反映在代码中。
商业身位与避坑指南
最深刻的变革往往发生在那些看似不起眼的基础架构之中。
现已可以通过 Gemini API 或 Vertex AI 开始使用这款模型。
老牌玩家 Cohere 的 Embed v4 遗漏了音视频两块关键拼图;
开源阵营中最能打的 Jina v4 拿下了图文与 PDF,同样对声音和动态影像无能为力。
Gemini Embedding 2 恰好填补了市场空白,成为当下唯一覆盖五大模态的商用级全能选手,实现了全模态 SOTA!
对于准备尝鲜的工程团队而言,有几个现实的「坑」必须提前规避:
兼容性断层。新老模型的向量空间处于不同的维度规则下。从旧版 gemini-embedding-001 迁移的系统,必须将海量历史数据全部重新编码并重建索引。
格式与时长阈值。目前音频仅支持 MP3 与 WAV,且有 80 秒硬性上限,较长的会议录音必须自行切片。
手动归一化。在代码调用层面,若选择非默认的低维度输出(如 768 维),开发者需要外挂脚本手动进行 L2 归一化处理。
当孤立的数据孤岛被彻底贯通,庞杂的现实世界才得以在代码的深海中投下清晰的倒影。
最深远的智能革命,往往藏在那些不动声色的基础设施里,悄然将万物重塑为同一种语言。
现在,可以通过 Gemini API 或 Vertex AI 开始使用 Gemini Embedding 2 模型,参考调用方式如下:
print(result.embeddings)参考资料:
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-embedding-2/