
“岁月如歌,谁还手写日记?昔日往事,摄影为证。” —— 许嵩《摄影艺术》
当你想起某次烟花秀后的海边照片时,现有的图像检索系统可能帮不上忙。尽管人工智能能够识别海滩和烟花,但它们无法理解这些图片之间的联系。
这是因为当前所有的图像搜索技术都存在一个核心问题:将每张单独的照片视为孤立的个体,而不是视作一系列事件的一部分。这种模式使得机器难以理解时间线、空间位置和故事背景。
中国人民大学高瓴人工智能学院窦志成教授团队与OPPO研究院联合提出了一种新的图像检索方法DeepImageSearch,该技术从“逐张匹配”转向了“上下文推理”。
研究人员开发了一个评估基准DISBench,并使用ImageSeeker框架对现有前沿模型进行了评测。结果表明,即使是强大的多模态模型,也无法在新基准中取得理想的性能。
当AI不再仅仅是识别单张图片的内容,而是像人一样理解整个经历,图像搜索才能进入深度检索时代。这项技术的发展才刚刚开始。

- 论文标题为《DeepImageSearch: Benchmarking Multimodal Agents for Context-Aware Image Retrieval in Visual Histories》
- GitHub项目地址:https://github.com/RUC-NLPIR/DeepImageSearch
- 研究论文可以在arXiv上查看,链接为 https://arxiv.org/abs/2602.10809
- 数据集可在Huggingface平台上获取,地址是https://huggingface.co/datasets/RUC-NLPIR/DISBench
- DISBench排行榜位于https://huggingface.co/spaces/RUC-NLPIR/DISBench-Leaderboard
从识别物体到理解事件:
DeepImageSearch定义了一种新的图像检索方式。
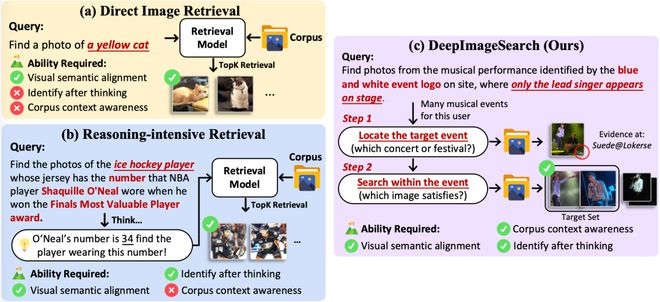
这一新方法的核心在于,它将查找照片的过程比作侦探工作:通过推理和关联线索,最终找到目标。
随着视觉语言模型的发展,图像搜索的能力有了显著提升。例如,可以借助这些模型找到特定颜色的猫或某个历史事件的照片。
但是,现有技术仍然遵循一个基本假设:每张图片独立于其他照片存在,并且可以通过其自身的内容被单独识别出来。
DeepImageSearch打破了这一传统观念。
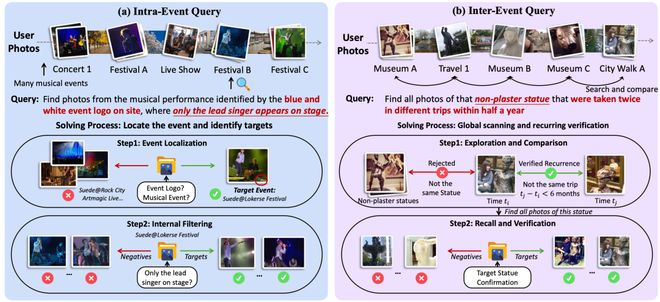
举个例子来说,如果用户想找到某次音乐节上主唱独自站在台上的那一幕的照片,传统的搜索方法可能会遇到困难。因为这些图片中可能包含许多类似的场景,而没有明显的独特特征区分它们。
不过,通过一些线索(比如特定的活动标志),DeepImageSearch能够帮助用户识别正确的照片。
这种方法不仅依赖于视觉信息,还利用了上下文信息来理解事件之间的联系和差异。
DISBench测试显示,即使是当前最先进的模型也无法在该基准上获得令人满意的结果。这表明传统的嵌入式搜索技术在此场景中效果不佳。
进一步的研究发现,这些模型的主要问题在于规划和推理能力不足,而不是感知功能的限制。
研究团队还注意到,在跨事件推理方面存在显著挑战:即使是强大的AI系统也难以在这类任务上表现出色。同时,尽管某些搜索技术可以提高准确性,但如何正确地从结果中筛选出所需信息才是真正的难点。
出一张高难度考卷
通过重复测试发现,虽然模型有可能在多次尝试后找到正确的答案,但仍需进一步探索如何更有效地利用它们的潜力。
回到最初的场景:“那场烟花秀后的海边照片”,DeepImageSearch表明这不是一个简单的匹配问题,而是需要理解事件间联系和记忆片段的问题。
该工作的贡献在于提出了一种新的图像检索范式,建立了评估这种能力的标准,并揭示了当前模型在规划、状态管理和长期推理方面的局限性。
当AI能够理解和串联个人经历中的关键节点时,它将成为一个理解用户生活的伙伴,而不仅仅是搜索工具。
这项技术的开发虽然才刚刚起步,但已经为未来的探索铺平了道路。
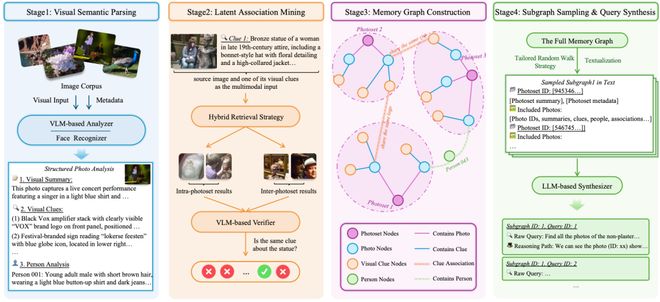
本论文的第一作者邓琛龙,现为中国人民大学高瓴人工智能学院博士四年级学生。他的研究方向包括高效长上下文语言模型和深度搜索智能体,在多个国际会议和期刊上发表了多篇论文,并担任过ACL和EMNLP的领域主席。
论文通讯作者窦志成教授是中国人民大学高瓴人工智能学院长聘教授,博士生导师。他的研究主要涉及信息检索、大模型应用以及AI搜索等领域,在学术界享有很高的声誉。他带领团队开发了一系列创新工具,并在国际知名期刊和会议中发表了200多篇论文。他的工作得到了广泛的认可,其项目GitHub上的星标数量超过了一万枚。
2.Inter-Event 查询(占 53.3%)” 跨越整个相册的多段经历,理解他们之间的关联关系”。比如 “我曾经在半年内的两次不同旅行中拍到过有一座非石膏雕像,请找到包含这个雕像的所有照片”。模型需要在所有旅行照片中全局扫描、识别同一座雕像、核实时间约束,再召回全部相关照片。
整个基准覆盖 57 位用户、近 11 万张照片,平均每位用户的视觉历史跨度 3.4 年,每条查询平均指向 3.84 张目标图片。而模型在评测时对 "哪些照片属于同一事件" 这样的内在结构完全不可见。它必须像一个真正的助手一样,从一片混沌中自主发现结构、串联线索。
3. ImageSeeker:探索视觉历史的深度搜索
需要什么样的 Agent?
DeepImageSearch 定义了一个全新的任务,但一个随之而来的问题是:要完成这种以个人相册为代表的视觉历史深度搜索,agent 到底需要具备什么样的能力?这在此前是一片空白。没有人在 “探索视觉历史” 这个场景下系统性地思考过这个问题。
研究团队因此设计了 ImageSeeker 框架。它的目标不是追求极致性能,而是作为先驱者做一次系统性的探索:这类任务到底需要什么能力?工具该怎么设计?长程推理中的状态该怎么管理?这些探索所得到的 insight,和框架本身一起,为后续研究提供了参考基线。
工具层面:一种能力远远不够。团队的核心观察是,模型需要灵活组合四种能力才能应对这个任务:语义检索(用自然语言在相册中搜图)、时空过滤(处理时间和地理位置的精确约束)、视觉确认(把照片调出来仔细看,做细粒度判断)、以及外部知识补充(解决查询中涉及的百科类知识)。更关键的是,这些能力之间可以协同。agent 能把一次检索的结果保存为命名子集,后续在子集内继续搜索或过滤,使得先缩小范围,再精确定位的多步推理成为可能。
记忆层面:战线太长,记不住怎么办?一次查询可能需要数十步交互,处理大量图片很容易撑爆上下文窗口。ImageSeeker 为此引入了双层记忆机制。一层是显式状态记忆,通过命名子集把中间发现持久化保存,确保多步探索中不丢失已有成果;另一层是压缩上下文记忆,在对话历史接近上限时,自动将其提炼为 "全局目标" 和 "当前行动计划" 两部分摘要,在有限的空间内尽可能保留关键推理状态。
4. 最强模型们暂时也无法完美解决好这个问题
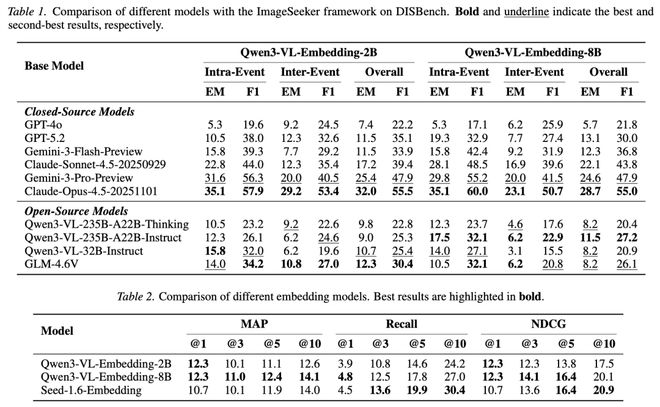
ImageSeeker 框架的模块化设计,使得我们可以将不同的多模态大模型插入同一套工具和记忆机制中,公平地比较它们在这个全新任务上的表现。研究团队测试了几乎所有主流前沿模型:闭源阵营的 GPT-4o、GPT-5.2、Gemini-3-Flash/Pro、Claude-Sonnet-4.5/Opus-4.5,开源阵营的 Qwen3-VL-235B/32B 和 GLM-4.6V。
结果是全线受挫:表现最好的 Claude-Opus-4.5,一次尝试的完美率也只有约 29%。开源最佳的 GLM-4.6V,综合得分不到最强闭源模型的四成。要知道,在传统图像检索基准上,这些模型的表现早已逼近天花板,而 DISBench 让它们集体回到了及格都困难的状态。
那干脆不用 agent,直接用最好的 Embedding 模型做传统检索行不行呢?更不行。三个代表性 Embedding 模型的表现几乎等于盲猜,因为个人相册中存在大量视觉高度相似的照片,传统检索会把所有 “看起来像” 的图片一股脑返回,完全无法区分 “满足上下文约束的真正目标” 和 “来自其他事件的干扰项”。这不是模型不够强的问题,而是范式本身的天花板。
但更值得关注的,是这些模型到底 “笨” 在哪里。研究团队对失败案例进行了系统性的人工分析,发现了一个清晰的结论:感知能力已经不是主要短板,规划和推理才是。
具体来说:最大的错误类型是推理出错,占所有错误的 36% 到 50%。模型已经找到了正确的线索,却在执行多步计划的过程中迷了路、丢了约束、或者过早停了下来。其次是视觉判别失败,比如把不同角度拍摄的同一座建筑误判为两座不同的建筑。AI 不是看不见答案,而是在推理的半路上把答案弄丢了。
还有几个值得进一步关注的发现:
跨事件推理是核心瓶颈:强模型在单个事件内的搜索明显优于跨事件搜索(如 Claude-Opus-4.5 的表现直接打了八折),而弱模型则是一视同仁地差。这说明一旦基本的 agent 能力建立起来,真正拉开差距的是长程的跨事件关联发现能力。
搜得更准不等于答得更好:将检索用的 Embedding 模型从小换到大,各模型表现并不一致,有的提升、有的反降,但总的差异不大。核心挑战不在于搜索本身,而在于如何对搜到的结果进行正确的推理和筛选。
模型们有着做对的潜力:通过 Best@k 和 Majority Voting 等方式测试,可以发现总分会随着测试次数的增加而提升。这表明模型在多次尝试中是有可能得到正确结果的,但是如何释放他们的潜力有待后续工作的继续探索。
5. 结语
回到最开始的问题,“找到那次看完那场烟花秀的几天后,我去海边拍的那些照片”。DeepImageSearch 告诉我们,这不是一个更好的 Embedding 能解决的问题,而是一个需要理解你人生叙事结构的推理问题。
这篇工作的贡献可以归纳为三件事:提出了从独立语义匹配到上下文推理的图像检索新范式;构建了第一个评估这种能力的高质量基准 DISBench;并通过 ImageSeeker 框架的系统探索,揭示了当前最强模型在规划、状态管理和长程推理上的关键短板。
当 AI 真正学会在我们的视觉历史中 "读懂" 事件之间的脉络、串联碎片化的记忆线索,相册搜索将不再只是一个工具功能,而会成为一个真正理解你人生故事的记忆伙伴。
通往这个时代的路已经被打开,但显然,我们还有很长的路要走。
作者简介:
本工作第一作者邓琛龙,目前就读于中国人民大学高瓴人工智能学院,博士四年级,目前研究方向聚焦于高效长上下文语言模型与深度搜索智能体。在NeurIPS、ACL、EMNLP、WSDM等国际顶级会议和期刊发表多篇论文,曾担任ACL 2025和EMNLP 2025审稿周期的领域主席。
本文的通信作者窦志成,中国人民大学高瓴人工智能学院长聘教授、博士生导师、副院长。主要研究方向为信息检索、大模型、智能体、大模型检索增强、AI搜索、司法智能等。在国际知名学术会议和期刊上发表论文200余篇,带领团队研发涉外法治大模型,开源大模型检索增强工具包FlashRAG、信息智能体系列工作累计获得GitHub星标1万余枚。