最近,理想公司发布了一项新的技术突破——一款结合了流式视频理解和具身智能的新型Agent框架StreamingClaw。
该系统不再像传统的“龙虾”那样只是盯着屏幕玩电脑,在实际应用中已经能够主动介入用户的生活与工作场景之中。
StreamingClaw在确保兼容OpenClaw的基础上,新增了实时多模态流式交互的支持功能。
这种改进使得系统可以像人类一样,在接收到视觉输入时即时进行处理并生成反馈。

例如,它能够主动识别驾驶员的疲劳状态或手机使用行为,并及时发出警告信息;
在用户取车之时,还具备问候的功能。
另外,StreamingClaw引入了自主多代理调度机制,通过主从代理间的紧密合作,实现了复杂的任务规划与逻辑决策。
同时也集成了多种工具和技能库,在实际场景中实现了指令驱动的具身智能操作。
该框架下,机器人和终端设备可以做到极低延迟的操作反馈:
比如,在用户手持物品时,能够实时识别并提供帮助。
StreamingClaw的关键优势在于其实时推理能力与快速响应机制。
支撑这一技术的核心是围绕“流式架构”展开的系统设计。
从传统“离线处理”的模式转向具备主动闭环功能的新框架,这是一个质的变化。
在具身智能、AI硬件和智能座舱等领域中,系统需要在极短的时间内完成感知—决策—执行的过程:
感知阶段通过摄像头捕捉环境信息;
决策阶段依靠强大的算法进行分析与规划;
- 执行阶段则直接驱动相关设备或发出指令,并根据结果调整策略。
- 以往的视频Agent在处理实时感知时,由于计算延迟问题难以实现高效运行。
- 这是因为传统的视频文件处理方法往往会导致数据量过大、信息丢失以及决策不准确等问题。
StreamingClaw则采用“增量计算”的方式解决了这些问题。
它不再依赖于过去的完整历史,而是将环境变化视为新信号进行推理更新。
这使得它不仅能更精确地感知和记忆较长的时间段内发生的事件,还能够在执行过程中自主调用工具,形成从感知到干预的完整闭环。
流式推理要求AI能够像观看实时视频一样,在数据不断流入的情况下即时作出反应。
在接下来的具体介绍中,我们将看到StreamingClaw是如何实现这些功能的。
具身智能流式交互引擎
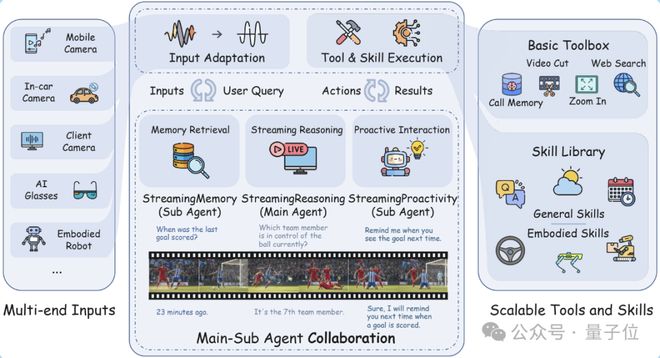
StreamingClaw是一个多代理架构系统,通过一系列标准化流程消除了不同硬件设备之间的障碍。
首先,所有输入的信息都会根据时间戳对齐并存储在共享缓存中;
接下来,核心大脑StreamingReasoning负责实时感知和规划,而StreamingMemory与StreamingProactivity则分别提供长期记忆支持以及主动交互决策。
代理生成的命令会直接驱动工具箱和技能库。
这种设计使得系统能够从简单的视频剪辑到复杂的具身动作序列,实现一个完整的“感知—决策—执行”闭环流程。
流式推理:StreamingReasoning
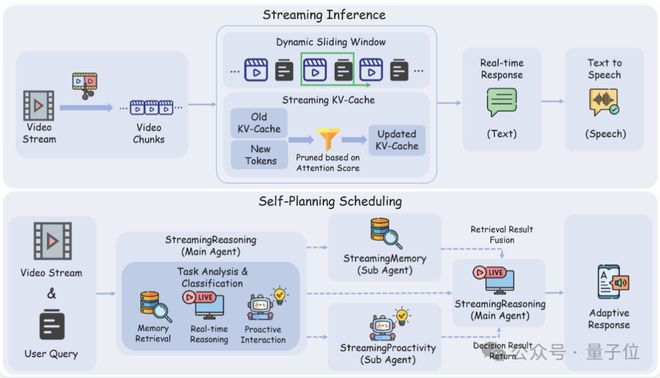
StreamingReasoning主要针对连续输入输出的流视频理解场景进行优化。
它的目标是在低延迟条件下实时感知、理解和推理现实世界的现象。
在实时流式推理方面,系统会将视频流拆分成细小片段,并通过动态滑动窗口来控制上下文范围,避免无效信息堆积。
结合优化的流式KV-Cache机制,StreamingReasoning能够持续高效地进行增量解码,保持与视频节奏同步运行而不会产生延迟问题。
自主规划调度能力被引入作为整个流程的核心控制点。
它可以动态解析用户指令并自主规划任务路径,并根据需要选择调用层级化记忆或触发主动交互决策;
在常规场景下,则保持直接且低延迟的流式多模态推理,确保整体过程顺畅自然。
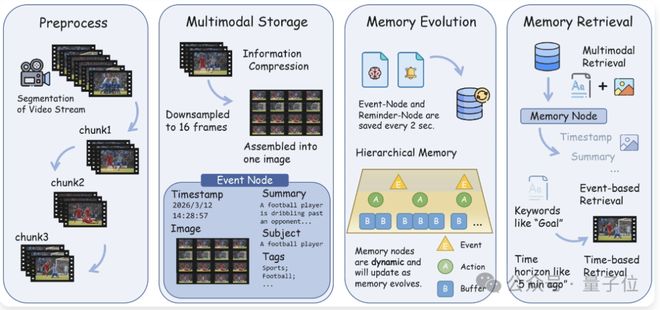
流式存储:StreamingMemory
StreamingMemory用于处理真正的多模态向量数据,并通过层次化记忆演化机制应对复杂的流视频理解任务。
它以视觉信息为中心,将多模态数据组织成增量式的记忆节点,避免原始数据的简单堆叠。
这些记忆随后被进一步转化为可用作决策依据的结构化经验,使系统能够从实际画面中提取出可用于推理的信息。
通过命令驱动的时间遍历检索机制,可以在长时序信息流中快速定位关键内容,并保持鲁棒性。
统一接口设计实现了跨代理记忆共享和差异化管理,支持更高效的协同工作。
下游代理:StreamingProactivity
StreamingProactivity专注于未来事件预测、推理及主动交互功能的设计。
它可以根据预先设定的用户目标或流式过程中的动态需求来调整自身的行为模式。
当识别到需要进行主动干预的情况时,主代理会启动持续在线监控任务;
一旦满足触发条件,系统将立即生成通知或解释性响应,并形成“感知—推理—触发—反馈”的闭环机制,避免不必要的重复查询操作。
这一机制覆盖了时间感知交互与事件定位交互两类场景。
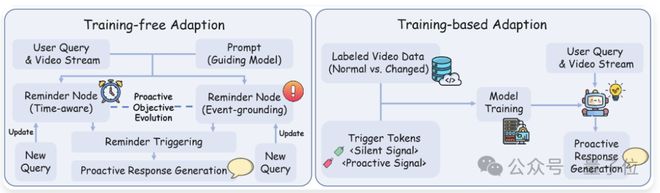
在实现方式上,它分为免训练适配和训练适配两种路径。
免训练适配通过结构化触发条件在流式过程中匹配视觉信号并即时生成响应;同时支持目标在线更新形成持续演化的主动交互闭环;
训练适配则将状态变化建模为视觉语言信号,引入场景专用触发Token,并在单次推理中完成多事件识别与响应。
这种方法在复杂场景下能提供更高精度和更强泛化能力,同时显著降低并发任务下的推理成本。

StreamingProactivity实现了全天候在线的主动交互功能,使系统能够持续感知变化并触发相应动作。
高效工具与技能:闭环的最后一公里
为了实现真正的物理世界影响,StreamingClaw提供了一系列高效的工具和技能接口,从而完成了“感知—决策—执行”闭环的最后一环。
这些包括标准的工具组合以及专为视频理解和流式交互设计的专业工具。
比如Video Cut工具能够在关键片段中精确裁剪时间戳,并将内容送入大型多模态模型进行深入分析,再输出简明的结果文本;
展望未来,StreamingClaw将进一步演进为一个全模态代理框架,打通视频、图像、音频与文本的输入输出通道,实现全面的感知-执行闭环。
同时还将增强长时程建模和空间理解能力,并持续优化低延迟部署及记忆调用机制,以支持更加真实世界的具身交互应用。
可扩展的工具与技能:闭环的最后一公里
为了真正让AI影响物理世界,StreamingClaw还提供了高效工具与技能接口,从而完成了“感知—决策—执行”闭环的最后一个环节。
除了标准的工具组合外,研究还引入了专为视频理解和流式交互定制的专业工具。
比如,Video Cut工具可以在关键片段中精准裁剪时间戳,将内容送入大型多模态模型进行“显微级分析”,再输出精简文本结果。

总体而言,StreamingClaw面向流式视频场景,基于多模态大模型实现感知、理解与语音输出,但当前仍以“视觉+文本”为核心输入范式,对音频输入、精细时序对齐及跨模态联合推理的支持仍有限。
未来,系统将演进为统一的全模态代理框架,打通视频、图像、音频与文本的输入输出,实现真正的感知-执行闭环;
同时强化长时程建模、空间理解与跨模态对齐能力,并持续优化低延迟部署与记忆、工具调用机制,以支撑更真实世界的具身交互。
[1]https://jackyu6.github.io/StreamingClaw-Page/
[2]https://arxiv.org/pdf/2603.22120