最新研究揭示,大模型现在可以“就地”调整参数了。
 鱼羊
鱼羊即插即用
字节Seed与北京大学的研究团队发现了一种方法,在推理时无需增加额外的训练层级即可直接修改现有参数。
随着智能时代的发展,大模型面临越来越多的任务挑战和更复杂的背景信息需求。如何使这些模型能够边执行任务边学习适应新的情况成为了一个重要的研究课题。
测试时训练(TTT)技术允许模型在推理过程中更新部分参数,但现有的实现方法存在架构不兼容、计算效率低以及优化目标不匹配等难题。

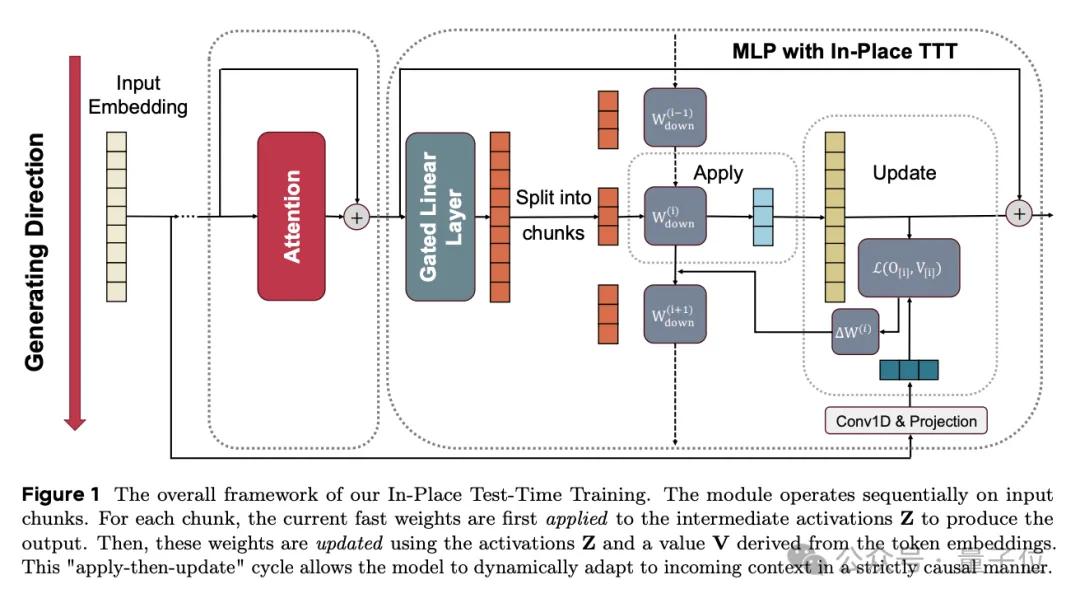
研究人员提出了一种称为“就地测试时训练”(In-Place TTT)的技术方案,有效解决了这些问题。该方法利用了Transformer模型内部已有的MLP模块,并将其作为更新参数的临时机制。
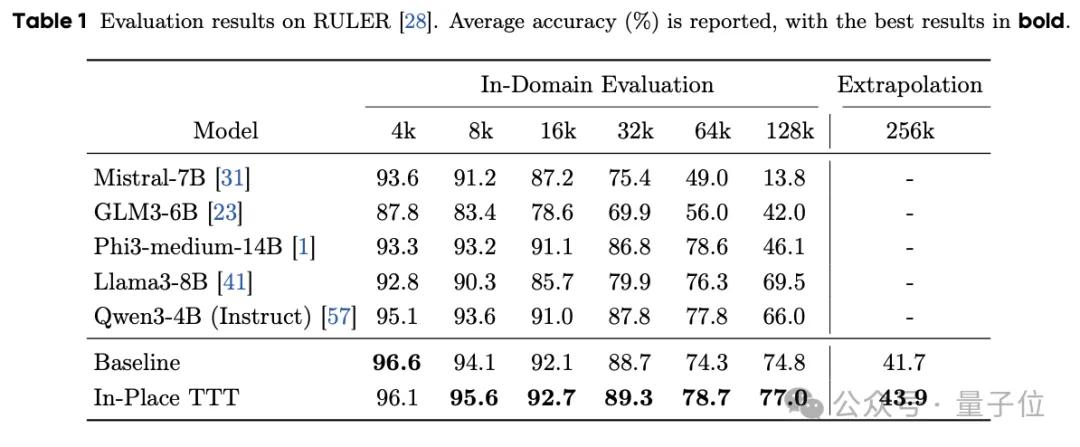
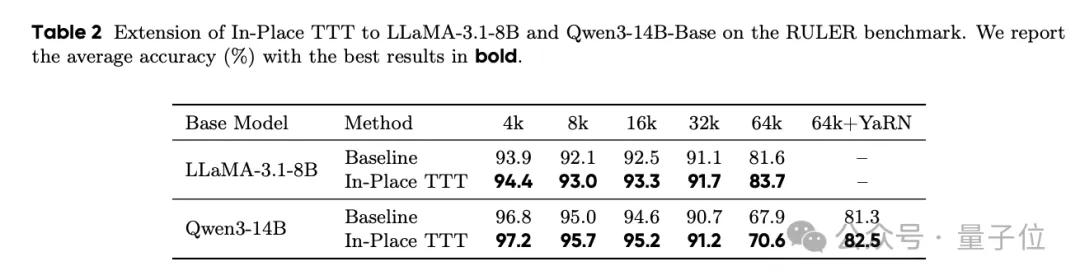
实验结果表明,在Qwen3-4B、Llama3.1-8B和Qwen3-14B等大型语言模型中引入In-Place TTT后,它们在处理长文本任务时性能显著提高。
In-Place TTT不仅实现了即插即用的目标,还避免了重新训练的需要。这种灵活性为大模型的应用开辟了新的可能性。
研究团队通过复用MLP模块中的投影矩阵Wdown作为快速权重,并在推理过程中对其进行原地更新,消除了对新增专用层的需求。
为了与语言模型的核心目标——预测下一个Token相匹配,In-Place TTT引入了一种新的优化策略。这种方法利用一维卷积和投影矩阵来使TTT的目标值包含对未来Token的预测信息。
研究表明,通过这种方式可以有效提升快速权重对未来的预测能力,从而增强模型在处理长上下文任务时的表现。
该技术还支持分块更新策略,并利用上下文并行技术实现了更高的计算效率和吞吐量。
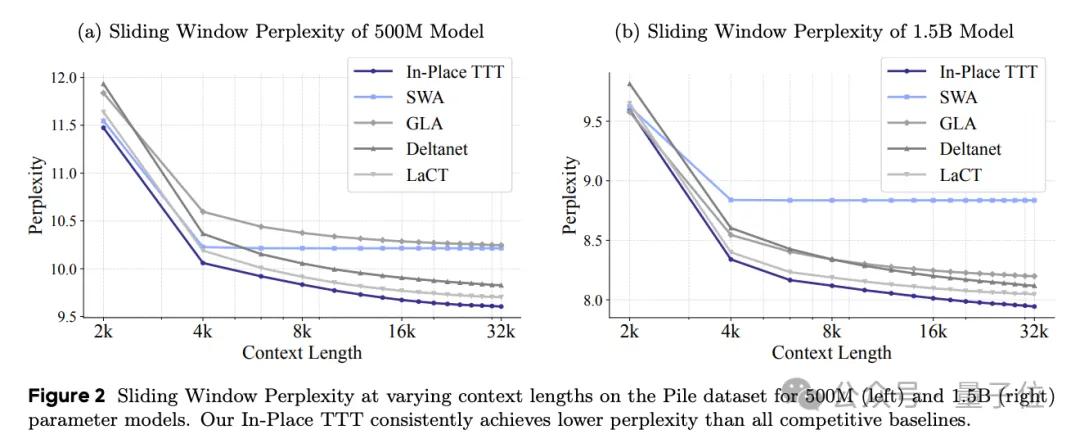
实验数据进一步证实了In-Place TTT的有效性,在与从头训练的其他TTT方法对比中表现更佳。
这项研究由冯古豪和罗胜杰共同完成,前者是北京大学的学生及字节Seed实习生,后者则在北大攻读博士学位,并师从王立威教授和贺笛教授。
Wenhao Huang作为论文的另一位通讯作者参与了这项工作。
这篇论文已经中了ICLR 2026 Oral。
让大模型在推理时“原地改参数”
话不多说,还是来看论文的详细内容。
In-Place TTT核心要解决的问题,是在不折腾模型架构的前提下,让大模型在推理/回答问题时,也能悄悄更新自己,适配当前的上下文。
实现即插即用,字节Seed和北大的研究人员主要做了3点创新。
原地架构设计
在In-Place TTT中,研究人员巧妙地复用了Transformer中无处不在的MLP(多层感知机)。
他们将MLP的最后一个投影矩阵Wdown作为快速权重(fast weights),在推理时进行原地更新。
这样就无需引入新的专用层来处理快速权重。已经训好的大模型也可以拿来直接用,不必重新训练。
语言模型对齐的优化目标
原来的TTT只让模型“记住当前Token”,前文已经提到,这与语言模型的优化目标是不一致的。
为此,In-Place TTT设计了专门针对自回归语言模型的优化目标:
通过引入一维卷积(Conv1D)和投影矩阵,使TTT的目标值包含了未来 Token的信息,从而显式地与“预测下一个Token”的任务对齐。
研究人员还分析证明,这种做法能促使快速权重压缩对未来预测有用的信息,从而有效提升模型的上下文学习能力。
高效的块级更新机制
In-Place TTT是对MLP进行改造,保留了原有的注意力层,这就使得该方法可以实现分块更新,不用再逐Token去处理。
结合上下文并行技术,In-Place能实现更高的吞吐量和计算效率,支持更长的上下文。

实验表明,In-Place TTT能大幅提升现有模型(如Qwen3-4B)在128K甚至256K长上下文任务中的表现。
在从头训练的对比中,也优于其他TTT方法。
研究团队
In-Place TTT的论文一作是冯古豪和罗胜杰。
冯古豪目前就读于北京大学,是字节Seed的实习生。
罗胜杰同样毕业于北大,师从王立威教授和本文通讯作者贺笛教授。
本文的另一位通讯作者是字节Seed的Wenhao Huang。
论文地址:
https://arxiv.org/abs/2604.06169v1