Cursor自主研发的新模型一举超越了Opus 4.6,价格策略也更加亲民,引发了编程界的热烈讨论。
 一水
一水新模型采用了先进的强化学习技术,大大提升了性能和效率。
倒反天罡了朋友!
Cursor的新编程模型Composer 2不仅在性能上超越了Claude,而且价格更加实惠,直接降低了成本。

作为早期Claude模型的供应商,Cursor凭借这款新模型迅速吸引了大量关注。
现在,Cursor推出了自己的编程模型,并成功超越了Claude,其最新模型Composer 2不仅功能强大,而且价格更低。
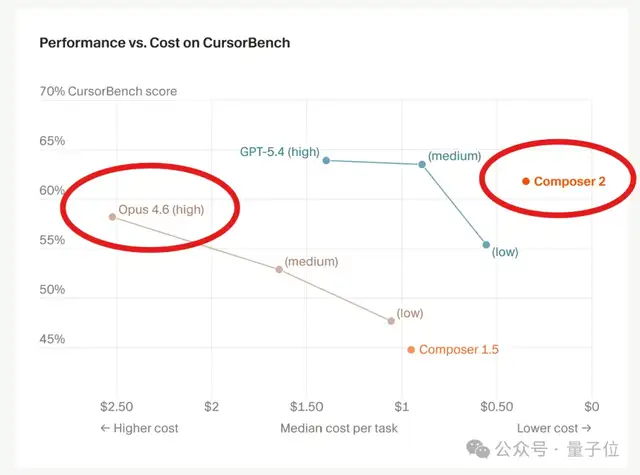
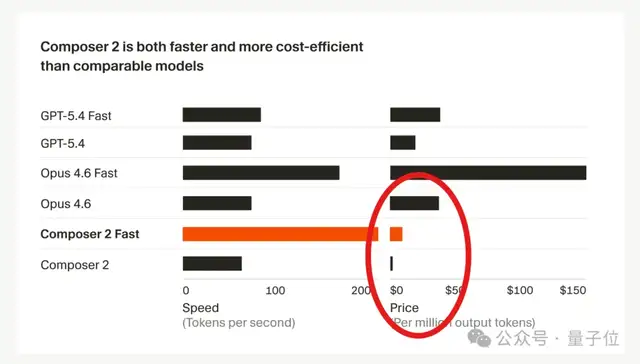
Composer 2在性能上超越了Claude Opus 4.6,并且价格大幅度降低。
相比其他公司降价仅“腰斩”,Cursor的降价力度直接“脚踝斩”。
为什么Cursor能在其他公司纷纷涨价的情况下,依然能够降低价格呢?
(随着“龙虾”现象的流行,全球大型模型的Token消耗量急剧增加,从年初开始,国内外的云服务提供商和大型模型公司都在提高价格。)
Cursor给出了答案:新的强化学习方法。
一种新的强化学习方法,使得Cursor的模型既强大又经济。
Composer 2的推出标志着Cursor的新一轮技术突破。
Composer 2不仅名字寓意“编曲家”,更体现了其作为“编程家”的强大能力。
面对“龙虾”现象导致的编程消耗Token用量激增,Cursor的目标非常明确——提高性价比。
性价比,即是“智能与成本的最佳结合”。
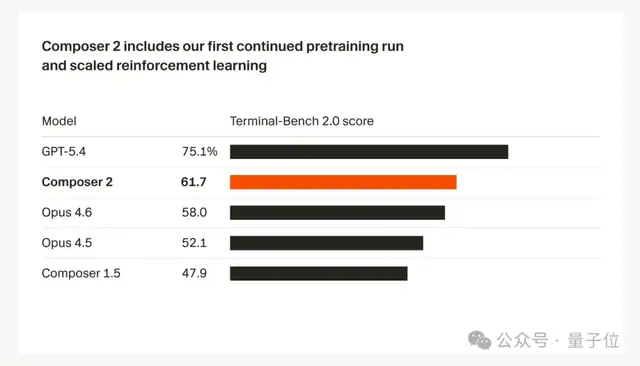
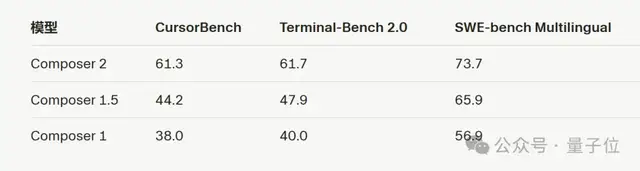
Composer 2在所有基准测试中均表现出色,包括Terminal-Bench 2.0和SWE-bench Multilingual。

Composer 2在衡量智能体终端操作能力的Terminal-Bench 2.0测试中,性能已经超越了GPT-5.4和Claude Opus 4.6。
Composer 2的进化速度也在不断加快。
Composer 2的标准版定价为每百万输入tokens 0.5美元(约合人民币3.5元),每百万输出tokens 2.5美元(约合人民币17.2元)。
与此同时,Cursor还推出了一款“智能水平相同但速度更快的变体”——Composer 2 Fast。
Composer 2 Fast的定价为每百万输入tokens 1.5美元(约合人民币10.3元),每百万输出tokens 7.5美元(约合人民币51.7元)。
Composer 2 Fast不仅延续了价格优势,而且速度更快。
Cursor表示,之所以能在性能和价格之间找到平衡,关键在于引入了一种新的强化学习方法。
这种方法的核心在于训练模型学会“自己给自己做会议纪要”,从而提高模型的处理能力。
用一句话来概括这种新方法,就是让模型学会“自己给自己做笔记”。
Cursor的解释是,这种名为“自我总结的强化学习方法”虽然听起来复杂,但其实非常实用。
这种方法主要解决的问题是,当前大多数AI编程助手在面对复杂任务时会出错。
任务越长,模型越容易出错,因为模型的上下文窗口总是有限的。

为了解决上下文瓶颈,业界有两种主流解决方案:摘要法和滑动窗口法。
这些方法虽然可以压缩上下文,但可能导致模型遗忘关键信息。
而Cursor的解法是让模型学会自我总结,将这种总结能力内化为模型的一部分。
Composer模型使用了一套“self-summary(自我总结)”机制,使得模型能够在处理任务时主动总结上下文。

Composer的提示词非常简单,但压缩后的输出却能更有效地保留关键信息。
在一项高难度软件工程任务中,Composer的提示词仅需一句“Please summarize the conversation”,而压缩后的输出平均只有1000个tokens。
相比之下,传统摘要法的token用量高达5000+。
Composer不仅压缩得更狠,而且信息更关键,解决了长链条任务的问题。
在一项经典难题中,Composer展示了其强大的处理能力。
Composer在经过170轮交互后,找到了精确的解法,并将10w+tokens总结压缩到了1000个。
- 一系列内部测试表明,Composer通过将压缩整合进训练循环,学会了将关键信息向后传递的机制。
- 通过将压缩整合进训练循环,Composer在高难度任务上变得更加有能力。
未来,Cursor将继续推进技术创新。
Cursor的CEO表示,Cursor既不是纯粹的应用程序开发商,也不是模型提供商,而是两者之间的桥梁。
只是不知道Cursor会不会开源,不过已经有热心网友帮忙求证了。
而Cursor的解法是——首先总结很重要,其次把这种总结能力内化成模型自己的能力也很重要。
所以他们给自家模型加了一套“self-summary(自我总结)”的机制:
模型干活干到一半,不是被动压缩,而是主动停下来给自己写一段“阶段总结”,俗称“做笔记”。
具体流程大致如下:
1、Composer基于提示词持续生成,直到达到固定的token长度触发点。
2、插入一个合成查询,要求模型总结当前上下文。
3、给模型提供一定的草稿思考空间,让它构思最佳总结,然后生成压缩后的上下文。
4、Composer使用压缩后的上下文回到步骤1;该上下文包含总结以及对话状态(规划状态、剩余任务、之前总结的次数等) 。
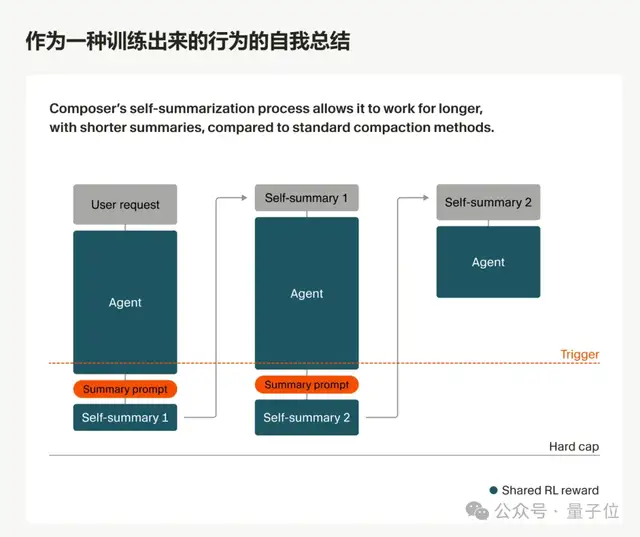
这里面比较关键的一点是,模型的自我总结能力不是推理技巧,而是训练出来的。
在强化学习过程中,这种总结能力会被算进奖励里:
- 总结得好→后面任务更容易成功→奖励更高
- 总结丢信息→任务失败→被惩罚
结果就是,模型慢慢搞清了:什么信息值得留下,什么可以丢掉。
具体效果可以看和传统方法的对比。
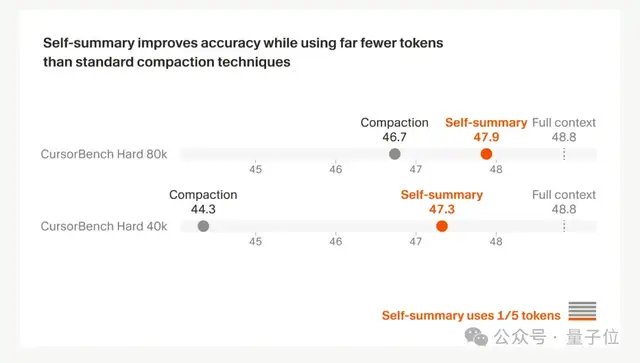
在一组高难度软件工程任务上,“传统摘要法”光是总结提示词就要写几千个tokens,而且压缩后的结果也不短,平均需要5000+tokens。
而Composer的提示词非常简单,基本就一句话“Please summarize the conversation”,且压缩后的输出平均只有1000个tokens。
在同样的任务上,后者token用量只有传统方法的1/5,而且压缩带来的错误直接减少约50%。
换句话说,压缩得更狠,但信息更关键。
更有意思的是,它真能解决长链条任务。
Cursor拿出了一道难倒一众模型的经典难题——把Doom游戏跑在MIPS架构上。
我已经提供了 /app/doomgeneric/,也就是 doom 的源代码。我还编写了一个特殊的 doomgeneric_img.c,希望您使用它;它会将绘制的每一帧写入 /tmp/frame.bmp。最后,我还提供了 vm.js,它会读取一个名为 doomgeneric_mips 的文件并运行它。其余部分请您自行解决……
由于需要模型自己改代码、编译调试、反复试错……所以很多模型到后来基本都直接卡死了。
但Composer在经过170轮交互后,找到了精确的解法,并在过程中将10w+tokens总结压缩到了1000个。

总之,一系列内部测试表明:
通过将压缩整合进训练循环,Composer学会了一种显式机制,能够高效地将关键信息向后传递,并在高难度任务上变得更有能力。
而且前面不是说了Cursor节奏很快,这不,Cursor研究员也已经开始放出Composer 3的消息了。
只能说发展到现在,Cursor以后也是有双重身份的“人”了。其CEO表示:
Cursor是一个典型的新公司,既不是纯粹的应用程序开发商,也不是模型提供商。

就是不知道能不能等一个开源?反正抱抱脸联创兼CEO已经去帮大家求了(抱拳jpg)。