真是让人惊讶!
乐天集团在3月17日发布了Rakuten AI 3.0,称其为日本国内性能最为卓越的大型AI模型之一,拥有约7000亿的参数量,并且专门针对日语进行了优化,采用Apache 2.0开源许可,并获得了日本经济产业省和NEDO的GENIAC项目资金支持。

然而,在发布仅仅12小时之后,这款备受瞩目的AI模型就曝出了重大问题。
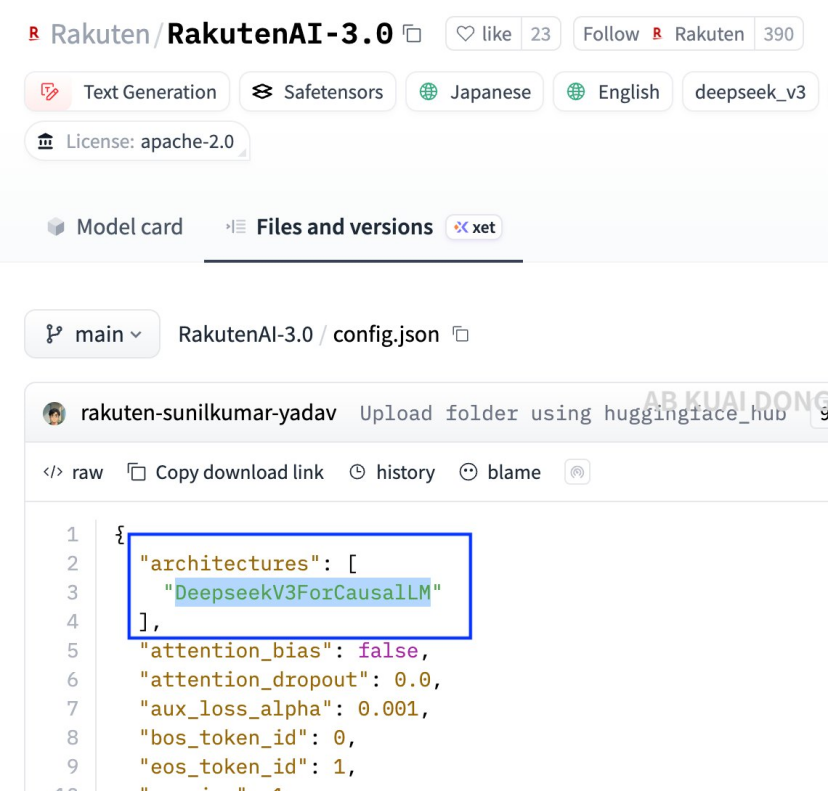
当天下午,有人查看了Rakuten AI 3.0在Hugging Face上的配置文件。
在第一行配置中,架构字段赫然写着一个在中国广为人知的模型名称:DeepseekV3ForCausalLM。
而模型类型字段则标明为deepseek_v3。
这意味着,所谓的日本最大规模高性能AI模型,实际上是DeepSeek V3。
01
发现这一问题的过程并不需要任何高深的技术知识。
在Rakuten AI 3.0发布之后,按照惯例,模型的权重被上传到了Hugging Face的乐天官方仓库。
任何人都可以进入该仓库,切换到“文件和版本”标签页,然后打开config.json文件查看。
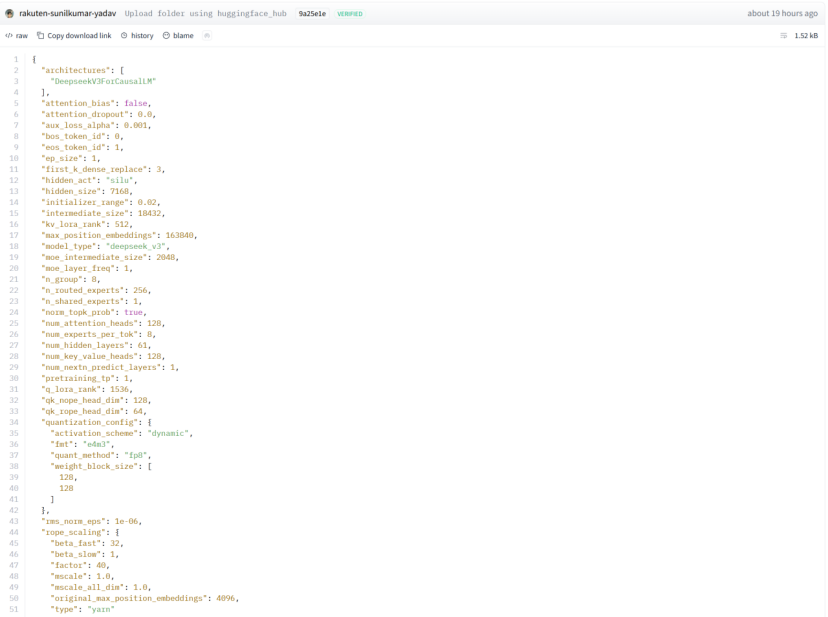
这个config.json文件是大型模型的标准配置文件,记录着模型的架构细节。
architectures字段中的“DeepseekV3ForCausalLM”表明,该模型采用的是DeepSeek V3的因果语言模型架构。
这并不是简单的参考或借鉴,而是直接声明了模型的类别。
接着往下看,隐藏层大小为7168,中间层大小为18432,隐藏层数量为61,专家路由数量为256,词汇量为129280。
这些参数与DeepSeek V3的原始配置完全一致。
说实话,这简直是赤裸裸的。而且,DeepSeek目前已经更新到了V3.2版本,V3版本的幻觉现象较多,实际上并不怎么好用。
乐天声称Rakuten AI 3.0拥有“约7000亿”的参数量,而实际上DeepSeek V3的参数量正好是6810亿。
Hugging Face的模型页面上,标签栏里甚至直接挂上了“deepseek_v3”的标签,这是系统根据config文件自动生成的,并非网友后加。
乐天方面宣称,Rakuten AI 3.0是基于开源社区中最为优秀的模型进行开发的。
这句话出现在官方新闻稿和Hugging Face的模型卡片上,以及乐天集团的PR Times新闻通稿中。从技术角度来看,这句话并未撒谎。
改变名称确实也算是一种开发方式。
DeepSeek V3是一个开源模型,其许可协议允许这种做法。乐天在此基础上使用自己的日语双语数据进行了微调和优化,这在业界非常普遍。
然而,乐天在所有对外宣传中,从未提及“DeepSeek”这个名字。
新闻稿中没有,模型卡片的描述中也没有,接受媒体采访时也没有。
因此,当有人在X(原Twitter)上贴出config.json的截图时,评论区的反应可想而知。
02
一张截图迅速传播开来:Hugging Face上Rakuten AI 3.0的config.json页面,架构字段中的“DeepseekV3ForCausalLM”被高亮显示。
图片下方,有人只写了两个词加一个问号:“deepseek V3?”。

这条帖子很快被转发到了Impress Watch的报道推文下,而该推文原本是一则普通的新闻转发,评论区却成了另一番景象。
Impress Watch是最早报道Rakuten AI 3.0的日本科技媒体之一,其推文下面的评论区引发了热烈讨论。
一位名为Ryu的用户写道:“日本终于到了用中国AI冒充日本产AI的时代了吗?”
日语评论普遍是批评的,而中文评论则多为围观,此处不再一一列出,大家可以自行想象当时的场景。
诚然,从严格意义上来说,乐天并未违反任何规则。DeepSeek V3的开源许可允许商业使用和二次开发,基于开源模型进行微调是行业的常规做法。
但这件事显然没有那么体面。
2025年DeepSeek大热的时候,日本媒体称其为“AI界的黑船事件”。
“黑船”是1853年美国海军准将佩里率舰队强行进入日本的历史事件,日语中用来形容外来力量给日本带来的巨大冲击。
将一个中国AI产品比作“黑船”,这一用词本身就透露了许多信息。
日本政府迅速做出反应。2025年2月初,日本数字大臣平将明公开表示,在安全疑虑消除之前,日本公务员应避免使用DeepSeek,或在使用时格外小心。
他特别提到了个人信息保护的问题。随后,日本政府向各省厅发出警告,要求不要在政府设备上使用DeepSeek。
企业界也采取了直接行动。
丰田汽车明确禁止员工使用DeepSeek,理由是出于信息安全的考虑。三菱重工同样实施了禁令,即使员工提交内部申请也不会被批准。
软银则限制了公司内部对 DeepSeek 的访问,并禁止员工在工作设备上下载和使用。
现在,你怎么让我忍住不笑呢?