
头图由智象未来AI大模型生成
在演唱会和大型晚会上,机器人伴舞团队以其整齐划一、精准的舞蹈动作吸引了观众的目光。这种表演不仅展示了硬件技术的进步,还体现了训练技巧的重要性。
具身智能的关键挑战之一在于如何使模型在虚拟环境中学习到符合物理规律的真实互动能力,这对许多企业来说是一道难以逾越的技术门槛。
近期,专注于AIGC视频大模型及应用的国产AI公司智象未来(HiDream),与具身智能领域的领军者诺亦腾机器人(Noitom Robotics)展开了战略合作。双方通过结合真实数据和虚拟增强技术,为行业提供了大规模高质量的训练素材。
这种跨领域合作模式为解决行业发展瓶颈带来了新的思路。
这种跨界协同的模式,也为破解行业发展瓶颈提供了全新思路。
一、诺亦腾机器人提供现实场景中的精确动作数据,智象未来则利用生成式模型将其放大
合作的核心在于结合真实世界的数据和生成技术,以及双方的技术优势互补。
真实数据的关键价值在于其不可替代的物理属性,这是确保模型贴近实际的基础。而生成式技术的价值则体现在突破了采集真实数据的局限性,实现了规模与多样性的扩展。
诺亦腾机器人作为具身智能领域中基础数据构建的重要角色,借助高精度人体动作捕捉和多模态数据收集设备,提供了来自现实世界中的精准人类行为样本。
这些数据基于真实的物理互动反馈,为模型训练提供了坚实的物理规律依据。
智象未来利用其先进的多模态大模型的视频生成能力,扮演着“炼金术士”的角色。
通过对诺亦腾机器人采集到的高精度多模态Human-centric数据进行百倍以上的精细化处理,并将其扩展至各种视觉场景中,智象未来不仅实现了数据量的增长,还保证了每一帧生成视频与动作指令的高度匹配。

▲左:诺亦腾机器人数据采集原始场景 右:智象未来生成式模型生成式处理效果
双方合作的一个重要成果是利用视频生成技术有效消除了真实数据中的视觉障碍及干扰因素。
二、解决数据采集难题:李飞飞“三层金字塔”理论解析
理解为何要进行这种合作,首先要明确具身智能领域当前面临的挑战是什么。
“AI教母”李飞飞提出了一个关于具身数据的三级结构模型:“网络和视频层、仿真合成层以及真实机器人操作层。”
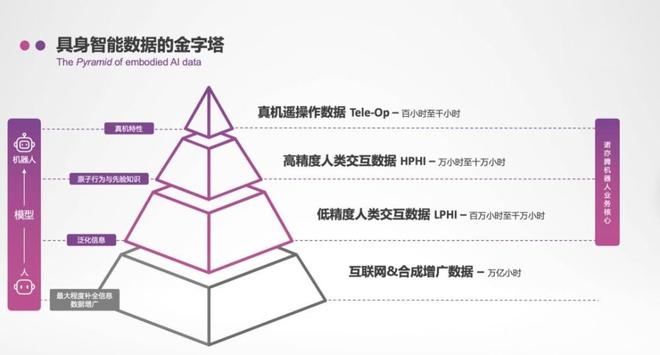
对于最高级的真实机器人数据和最低级别的网络与人类视频数据,行业已经进行了大量探索,并发现了两个主要问题:
一方面,在采集真实数据时,成本高昂且难以获取足够的视觉多样性来训练模型。另一方面,则是对多模态数据进行高精度捕捉的过程中产生的“Vision Gap”现象。
标准化的环境虽然可以提高采集效率并降低单位数据的成本,但要提升模型的视觉泛化能力,需要在多样性的环境下收集数据以应对现实中的不确定性挑战。
在这种情况下,各种光学、惯性动作捕捉系统以及触觉装置的使用会对人体形态造成干扰,导致“Vision Gap”现象出现。
对于采集到的数据进行后期修复虽然可以部分解决问题,但效果往往不尽如人意,难以满足训练模型所需的高质量要求。
这也让真实数据的应用受到了进一步限制。
三、探索数据生成的新模式:数万小时的全新实践
智象未来与诺亦腾机器人的合作正是针对上述问题的一次精准应对。他们创建了一种全新的混合范式,即真实采集结合生成式大模型协同。
这一方法既避免了单纯依赖某种类型数据的不足之处,又发挥了两者的优势互补作用,保持了现实世界物理一致性的同时突破了传统收集方式在场景多样性和规模上的限制。
实验表明,智象未来的生成式技术能够有效地弥补真实采集过程中产生的视觉缺陷,并产生符合物理规律的高质量训练素材。
通过这种“消除Vision Gap”的方法,双方成功制造出了既准确又丰富的训练数据,使大规模地生产这类数据成为可能。
这种做法为构建一个能够真正理解现实世界的智能模型提供了必要的支持。预计年内合作生成的具身智能视频资料将超过数万小时。
结语:具身智能进入“混合数据”时代
结语:迈向“混合数据”时代
业内普遍认为,2026年将是具身智能领域发展的关键一年,这一判断并非毫无根据。
近年来,行业在完全依赖真实采集和虚拟仿真的两极之间摇摆不定。单纯依靠现实数据虽然精度高但成本昂贵且场景有限;而仅凭虚拟仿真又存在物理真实性不足的问题。越来越多的人开始认识到,这两者都无法独立解决当前面临的挑战。
智象未来与诺亦腾机器人的合作恰好抓住了这一转型的关键点。
当下,两家公司的合作为业界提供了一种新的解决方案——“真实数据+生成式扩展”的混合模式。这有望成为行业标准,并引领具身智能进入一个全新的发展阶段。