具身龙虾,上车理想
 Jay
Jay当你准备取车时,系统会主动向你问候。
最近,理想公司推出了一项全新的流式视频理解和具身智能的集成框架——StreamingClaw。
比如,这个系统能够检测到驾驶员在驾驶过程中出现的异常行为,并及时发出警告;同时还能识别出你手中的物品并提供相应的帮助。
除此之外,StreamingClaw还引入了一种自主多代理调度机制,它能通过主从协作完成复杂的任务规划和逻辑决策。
系统整合了丰富的工具库与技能集,在现实应用中实现了以指令为驱动的具身智能功能。

在这种模式下,机器人或终端设备能够实时地“观察、记录并行动”,并且具备极低延迟的特点:
它可以即时识别你手中的物品,并给出相应的解决方案。
显而易见,在这些复杂的应用场景中,StreamingClaw的核心竞争力在于其实时推理和快速响应的能力。
这种能力背后支撑的是一个围绕“流式架构”设计的一整套系统方案。
相较于传统的离线处理模式,这种新方法能够在毫秒级别内完成感知、决策及执行的闭环操作:
从视觉信息捕捉到环境分析再到指令输出,整个过程几乎无缝连接。
然而,在传统视频Agent中,实时感知往往面临较高的延迟问题。
原因在于传统的处理方式通常将视频视作一个完整的文件来解析,这导致计算量急剧增加,难以实现实时响应;
同时,模型很难持续追踪长时间的信息流,从而影响了决策的准确性和效率。
对此,以往的研究尝试通过压缩或简化Token的方式来减轻负载,但这往往会导致细节丢失和定位不准确的问题。
更糟糕的是,传统的方法通常是被动触发式的:没有用户指令就不会启动任务处理,缺乏对环境变化的主动感知能力。
StreamingClaw则打破了这种固有的逻辑模式。
- 它不再依赖于重复解析历史数据,而是将环境中的微小变动视为增量信号进行推理更新。
- 这使得系统不仅能更准确地“看”、还能更长时间地记住,并且在分析过程中自主调用工具,实现了从感知到物理干预的闭环过程。
- 与离线模式不同的是,流式推理要求AI能够像观看现场直播那样即时处理源源不断涌入的数据流,不允许有任何延迟现象发生。
接下来,我们具体来看看StreamingClaw是如何实现这些功能的。
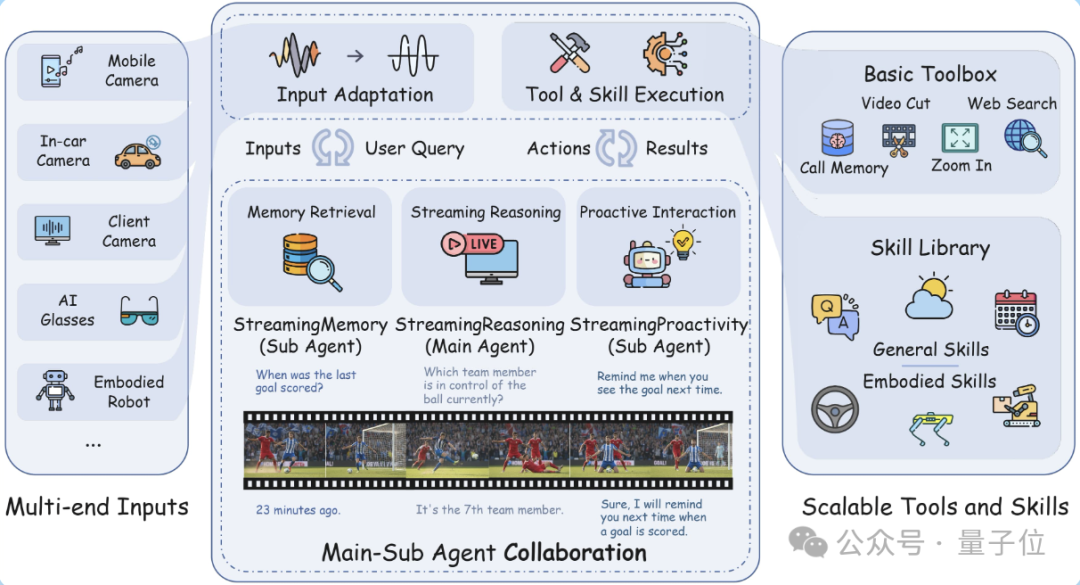
StreamingClaw的核心在于其多代理架构和协同流水线设计,它通过标准化的时间戳对齐与共享缓存机制打破了不同硬件设备之间的隔阂:
首先,无论是智能眼镜、自动驾驶芯片还是具身机器人,所有的多模态流式输入都会经过统一处理;
其次,系统的核心大脑StreamingReasoning负责实时感知和规划任务;而辅助代理则分别提供长效记忆支持与主动决策功能。
最后,代理生成的指令会直接驱动工具箱,并将结果反馈至代理模块中形成闭环。
这种设计使StreamingClaw不仅能理解命令还能通过自主计划及调用工具来解决实际问题。
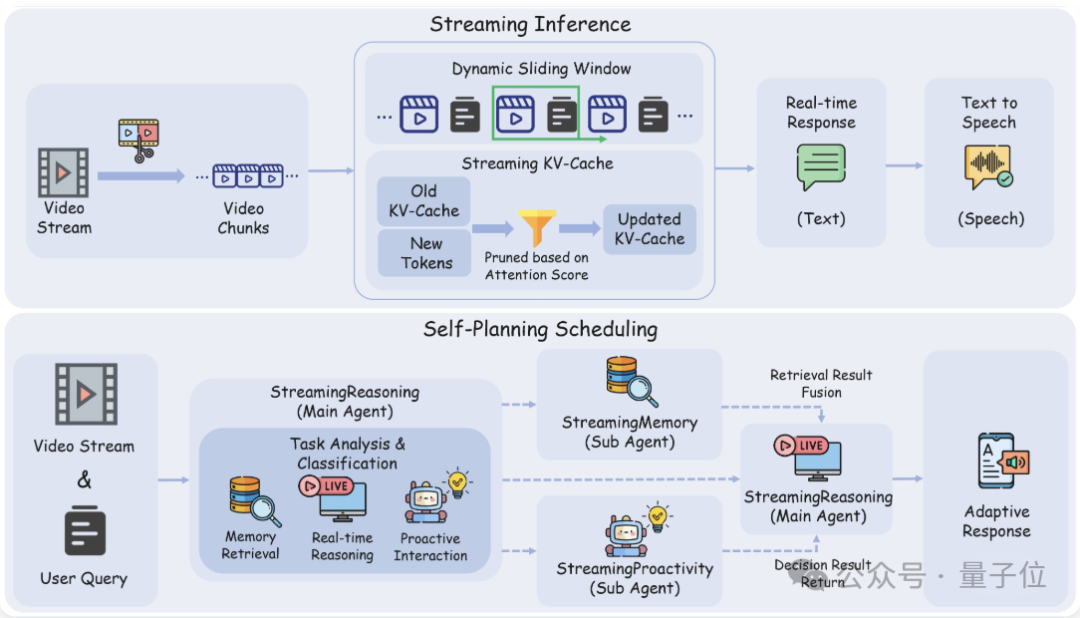
流式推理(StreamingReasoning)主要针对连续输入输出场景下的流视频理解任务。
其目标是在低延迟的前提下,实现对现实世界的实时感知、理解和推理分析。
在这一过程中,系统会将输入的视频流分解成细小片段,并通过动态滑动窗口控制上下文范围以避免无效信息堆积;
然后利用优化过的流式KV-Cache机制进行高效的增量解码,确保整体推理过程紧跟视频流节奏运行。
同时,系统还引入了自动调度功能作为整个流程的“总指挥”:
它可以动态解析用户指令,并根据需要调用层级化记忆检索或触发主动决策机制;
而在常规场景下则保持低延迟的多模态推理处理。
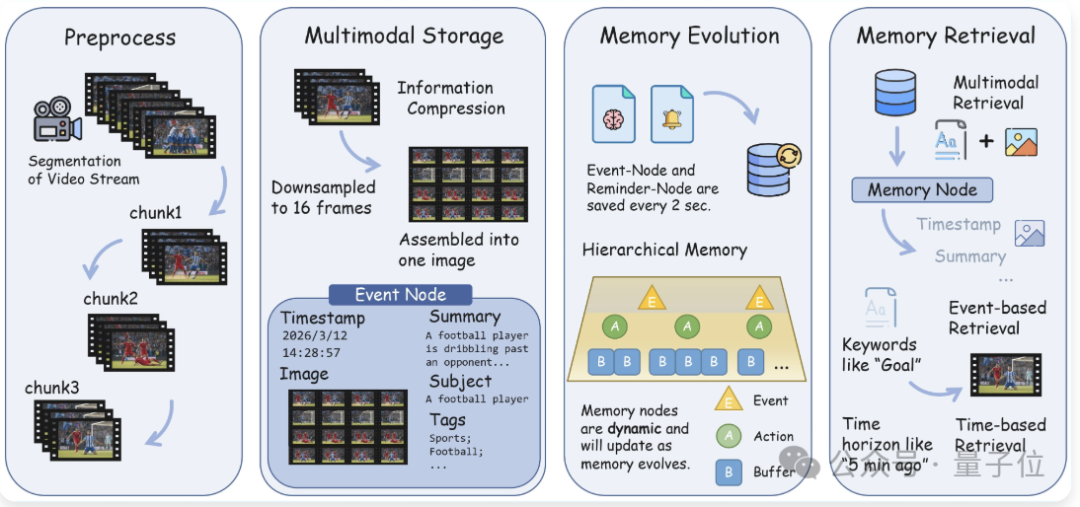
流式存储(StreamingMemory)负责保存真正的多模态向量,通过层级记忆演化机制应对复杂的流视频理解任务。
具体来说,在记忆机制上,系统以视觉信息为核心,将多种模式的信息组织成可持续增长的增量节点;
这些记忆进一步发展成为更高层次的“行为”和“事件”,使检索对象从原始画面转向可用于决策的结构化经验。
在此基础上,通过命令驱动的时间并行遍历实现高效检索,在长时间序列信息中快速定位关键内容,同时保持鲁棒性。
此外,统一接口设计使得不同代理之间可以共享记忆,从而支持更高效的协同工作。
从代理(StreamingProactivity)则专注于未来的事件预测、推理与主动交互功能。
它的目标既可以由用户预先设定也可以在流式过程中持续演化;
当请求被识别为主动交互时,主代理会将其转化为持续在线监控任务,如追踪行为或判断风险事件;
一旦满足触发条件,系统即刻生成通知或解释性响应,形成“感知—推理—反馈”的闭环。
在实现上,该机制分为免训练适配与训练适配两种路径:
免训练适配无需额外训练,通过将触发条件结构化为可监控节点,在流式过程中匹配视觉信号并即时生成响应;
训练适配则建模状态变化,并引入场景专用触发Token使感知和任务解耦。
整体而言,StreamingProactivity实现了全天候在线的主动交互功能。
为了真正让AI影响物理世界,StreamingClaw还提供了高效的工具接口,从而完成了“感知—决策—执行”闭环的最后一环:
这包括一系列专为视频理解和流式交互定制的专业工具;
如Video Cut工具可以在关键片段中进行精确裁剪,并送入大型多模态模型进行分析。
总体来说,StreamingClaw面向流式视频场景提供了基于多模态大模型的感知、理解与语音输出功能。
尽管当前主要支持“视觉+文本”输入范式,但未来系统将演进为统一的全模态代理框架;
实现真正的感知-执行闭环,并强化长时程建模、空间理解和跨模态对齐能力。
StreamingProactivity面向未来事件预测、推理与主动交互设计,其目标既可以由用户预先设定,也可以在流式过程中持续演化。
当请求被识别为主动交互时,主代理会将其转化为持续在线的监控任务,例如追踪行为、判断事件或监控风险。
一旦满足触发条件,系统即刻生成通知或解释性响应,形成“感知—推理—触发—反馈”的闭环,避免反复查询。
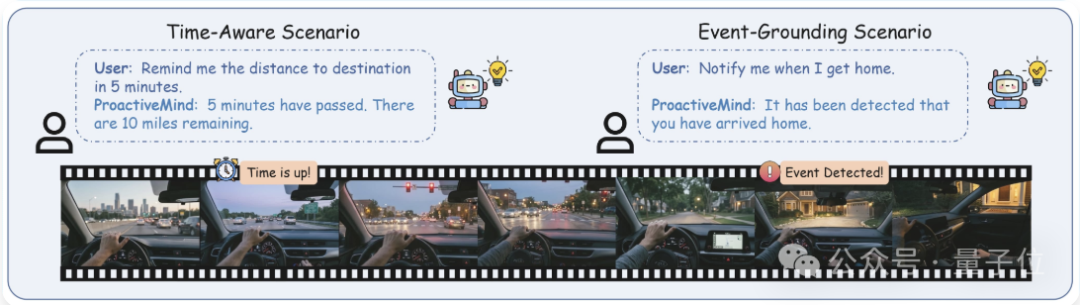
这一机制主要覆盖两类场景,一类是时间感知交互,强调对状态随时间演化的持续跟踪;
另一类是事件定位交互,聚焦关键事件在时间流中的精确识别,常见于异常检测与自动标注等任务。
在实现上,系统分为免训练适配与训练适配两种路径。
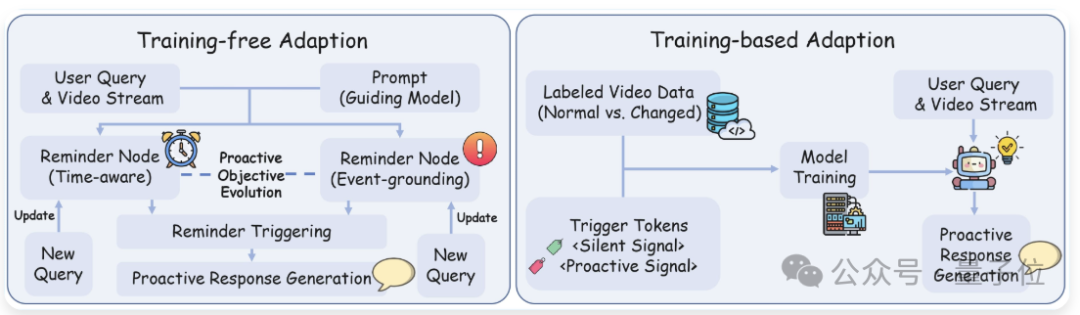
免训练适配无需额外训练,通过将触发条件结构化为可监控节点,在流式过程中匹配视觉信号并即时生成响应;同时支持目标在线更新,形成持续演化的主动交互闭环。
训练适配则将状态变化建模为视觉语言信号,引入场景专用触发Token,使感知与任务解耦,并在单次推理中完成多事件识别与响应生成。
该方案在复杂场景下具备更高精度、更强泛化能力,同时显著降低并发任务下的推理开销。
整体来看,StreamingProactivity实现了全天候在线的主动交互,使系统能够持续感知变化并触发响应。
可扩展的工具与技能:闭环的最后一公里
为了真正让AI影响物理世界,StreamingClaw还提供了高效工具与技能接口,从而完成了“感知—决策—执行”闭环的最后一个环节。
除了标准的工具组合外,研究还引入了专为视频理解和流式交互定制的专业工具。
比如,Video Cut工具可以在关键片段中精准裁剪时间戳,将内容送入大型多模态模型进行“显微级分析”,再输出精简文本结果。

总体而言,StreamingClaw面向流式视频场景,基于多模态大模型实现感知、理解与语音输出,但当前仍以“视觉+文本”为核心输入范式,对音频输入、精细时序对齐及跨模态联合推理的支持仍有限。
未来,系统将演进为统一的全模态代理框架,打通视频、图像、音频与文本的输入输出,实现真正的感知-执行闭环;
同时强化长时程建模、空间理解与跨模态对齐能力,并持续优化低延迟部署与记忆、工具调用机制,以支撑更真实世界的具身交互。
参考链接
[1]https://jackyu6.github.io/StreamingClaw-Page/
[2]https://arxiv.org/pdf/2603.22120