一项由17岁高中生陈广宇主导的新架构让科技界大佬如马斯克等人大为赞叹。
 克雷西
克雷西这次创新的核心在于将注意力机制进行了巧妙的“旋转”。
陈广宇采用的创新方法,将传统按时间顺序处理数据的LSTM网络的“时间轴”旋转为“模型深度轴”,并提出了新的Attention Residuals技术。
这项技术在深度维度上模仿了时间维度上的注意力机制,使得模型在处理当前层时能够根据需要选择性地提取前面各层的信息。
这项成果不仅吸引了马斯克的注意,也让大神Karpathy对Transformer的理解产生了新的思考。
在自家的Kimi Linear 48B大模型上进行验证后,模型的训练效率提高了25%,而推理延迟仅增加了不到2%。
传统残差连接的问题在于“记忆负担”。
残差连接的工作原理是将当前层的输出与前一层的输出相加。
然而,在大模型的PreNorm范式下,这种做法会导致早期信息难以检索,形成所谓的“PreNorm dilution problem”。

更严重的是,随着网络深度的增加,隐藏状态的范数会无限制地增长,导致训练过程不稳定。

为了解决这一问题,月之暗面团队提出了Attention Residuals机制。

该机制通过注意力机制让网络决定记忆哪些层的信息。
这种方式使得模型能够根据当前计算的需要,智能地选择性提取之前的层的信息。
然而,这种方法也带来了一个新的挑战:计算量急剧增加。
为了解决计算量问题,论文提出了Block AttnRes方法。
该方法将连续的若干层打包成一个block,仅保留一个“摘要向量”。
通过这种方法,attention的复杂度从O(L²)降低到了O(L·B),其中B可以设定得很小。
此外,团队还进行了一系列工程优化,包括缓存式流水线通信、序列分片预填充、KV 缓存粒度优化等。
实验结果表明,在自家Kimi Linear架构上,Attention Residuals确实能够显著提升效率。
这种技术不仅理论基础扎实,而且在实际应用中也表现出色。
陈广宇能够参与到这项研究中,得益于他的一系列成长经历。
一年前,他参加了一场中学生黑客松,并展示了关于“第三只机械辅助手”的创新构想。
- 这个项目让他遇到了创业导师董科含,后者引导他深入学习机器学习技术。
- 在导师的指导下,陈广宇逐步建立了对Transformer的理解,并最终加入了Kimi团队。
-
用注意力机制加权聚合
在硅谷实习期间,他不仅在技术上取得了显著进展,还积累了宝贵的商业经验。
回国后,他加入月之暗面团队,专注于Flash Linear Attention的研究。
从最初被前沿技术吸引,到最终投入到最底层、最核心的技术工作中,陈广宇的成长历程令人印象深刻。
他的故事为我们展示了一条不同于传统路径的成长道路,证明了兴趣和能力可以共同推动技术创新。
论文中的解决方案是Block AttnRes。
核心思想是把连续的若干层打包成一个block,对block内部的输出做压缩,只保留一个“摘要向量”。
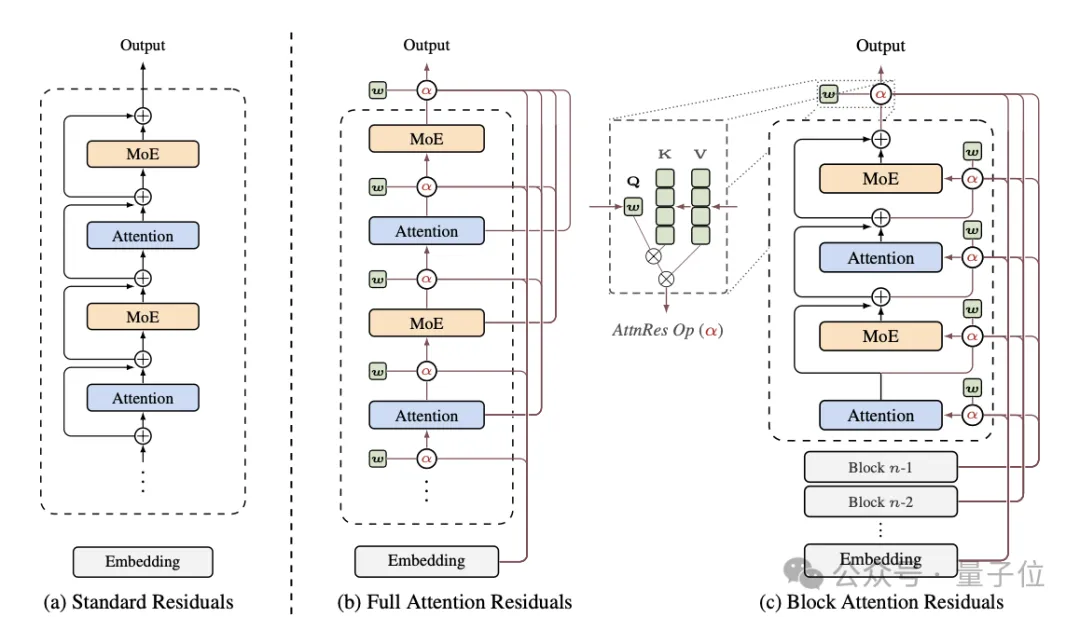
具体操作如下:
-
把L层网络分成B个block,每个block包含若干层 -
每个block结束时,把block内的信息压缩成单个向量 -
后续层做attention时,只需要关注块间表征+块内实时层输出,而非全部L个层
这样一来,attention的复杂度从O(L²)降到了O(L·B),在实践中B可以设得很小(论文用的是8-16)。
此外,团队还做了数个工程优化:缓存式流水线通信、序列分片预填充、KV 缓存粒度优化等等。
Kimi Linear验证:1.25倍效率提升
理论说得通,但真正让人信服的是大规模验证。
团队在自家的Kimi Linear架构上做了测试。这是一个采用线性注意力的大模型,总参数48B,激活参数3B(MoE架构)。
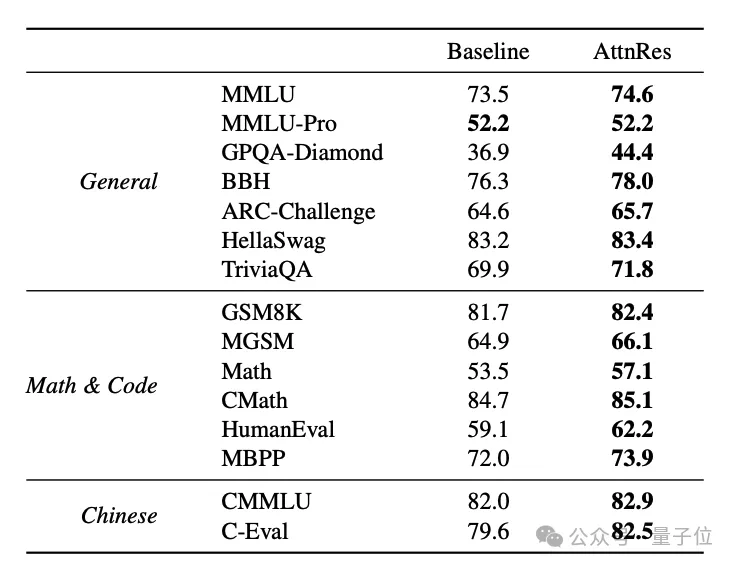
同等计算预算下,Attention Residuals能获得更好的下游性能;反过来说,达到相同性能需要的训练计算量减少了约20%,相当于获得了1.25倍的效率优势。
在具体任务上,数学推理(MATH、GSM8K)、代码生成(HumanEval、MBPP)均持平或略优,多语言理解的一致性也有所改善。
更重要的是,Attention Residuals是一个drop-in replacement,不需要修改网络其他部分,直接替换残差连接即可。
论文里还讲到一个有意思的视角。
团队把这项工作称为“时间-深度对偶性”(time-depth duality)的应用。
在他们看来,深度神经网络的“层”和循环神经网络的“时间步”,本质上是都是对信息的迭代处理。
Transformer之所以成功,是因为用attention替代了RNN中固定的recurrence。
那么在深度维度上,是不是也该用attention替代固定的residual?
17岁高中生入列共同一作
更有意思的是,这篇让马斯克、Karpathy等人都为之一震的论文,共同一作之一是一名年仅17岁的高中生——陈广宇(Nathan)。
另外两名共同一作,分别是Kimi的关键人物之一、RoPE(旋转位置编码)的提出者苏神(苏剑林),以及Kimi Linear的第一作者张宇。
诚然Attention Residuals是团队协作取得的成果,但一名高中生出现在这样的团队之中,还与两位大神共列一作,已经足够震撼。
a16z创始人Marc Andreessen、Thinking Machines的联创等人都关注了他的X账号。
一年前才刚刚开始了解大模型的陈广宇,是从北京的一场黑客松开始,一路走向硅谷的。
后来回国时,他选择加入了Kimi。
经手过月之暗面投资的奇绩创坛(原YC中国)创始成员董科含,也曾在其个人公众号上刊载过陈广宇的一份自传。
去年二月,北京的一场中学生黑客松上,陈广宇展示了一个关于“人类第三只机械辅助手”的创新构想——ThirdArm。
也正是这个项目,让他结识了黑客松评委董科含,后者也成为了他的创业导师。
当时,董科含追问他,未来是否会深耕这项技术,这促使他开始重新审视自己的职业方向。
随后他入选了董科含发起的只有极少数人入选的青年计划,开始接触IOI(国际信息学奥林匹克)金牌得主及资深科研人员。
此前他曾尝试经营Shopify跨境电商店铺、运营短视频账号,但经过董科含的建议,他决定转向理解时代的底层技术。
当时还不知道Transformer是什么的他,在DeepSeek研究员袁境阳的指导下,利用Gemini作为辅助工具,通过研读经典论文、追踪GitHub开源项目等方式逐步建立认知。
有一次他在推特上分享了对一篇博客的反思后,获得了作者的回复,这篇帖子也因此引起了一家硅谷AI初创公司CEO的关注。
该公司于2024年底成立,2025年初完成了800万美元种子轮融资,资方背景涉及OpenAI与Anthropic。
在通过一项限时通宵完成的实验测试后,他拿到了对方的录用通知。
暑假期间,他前往旧金山开启了为期七周的实习。其中前两周,他负责定义并推进一个涉及144张H100显卡的探索性项目。
在CEO直接指导下,他的工作延伸至运营层面,参与了招聘系统搭建、技术内容输出及融资策略讨论,并获得与早期投资者Vinod Khosla交流的机会。
在硅谷期间,他维持着高强度工作节奏,通过咖啡社交与英伟达工程师及初创创始人建立联系。这次经历让他将科研视为一种支撑创造的底层能力。

实习结束后,陈广宇回到国内,并于去年11月加入月之暗面。
把他吸引进去的,正是Kimi一直做的Flash Linear Attention这一类高效attention工作。
实际上,正是GitHub上的FLA项目,吸引了他对机器学习的兴趣并被邀请加入Kimi团队。
也正是顺着这条线,他开始一路往更底层钻,从读论文、看实现,到研究 Triton kernel、理解attention为什么能被这样重写、这样加速。
到了月之暗面,这条路也算是绕了一圈又落回原点——
他最初是被底层技术吸引,最后做的也正是最底层、最核心的那部分事。
相比于讲一个“少年天才一路开挂”的故事,陈广宇的经历更像是另一种成长路径——
先被时代最前沿的技术击中,再一步步把兴趣磨成能力,把能力带到真正的大模型研发现场里。
论文地址:
https://github.com/MoonshotAI/Attention-Residuals/
参考链接:
[1]https://mp.weixin.qq.com/s/gRR99pEDWb5qsk2a2hwe2w
[2]https://nathanchen.me/public/About%20me.html