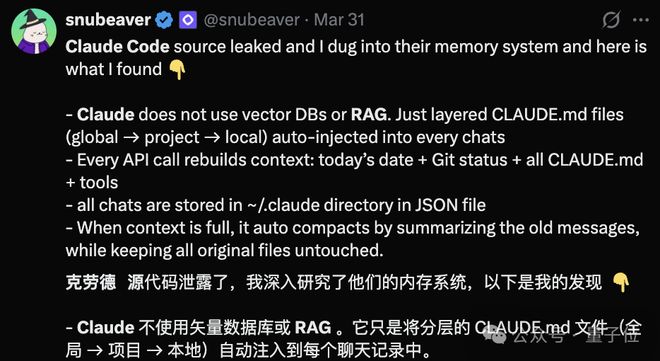
最近,AI圈内围绕Claude Code源码泄露的余波仍在持续发酵。
然而令人惊讶的是,虽然Claude几乎完全贡献了所有关于RAG记忆项目的代码,但泄露的文件却揭示了一个出乎意料的事实——它似乎并没有采用主流的RAG技术方案?
这一矛盾现象引发了诸多疑问:Anthropic在其官方文档和技术博客中明确表示支持RAG检索功能。
与此同时,“弃用”传统RAG的做法也表明,现有的RAG解决方案在性能上未能达到理想标准。
自2023年以来,混合检索逐渐成为记忆引擎的标准配置逻辑,包括向量加关键词匹配、权重排序等技术的迭代更新。

随着AI应用场景变得越来越复杂,传统RAG的技术瓶颈也日益凸显。尽管被称为“记忆引擎”,但其实它们仍然在执行搜索引擎的功能:仅能进行文本相似度匹配而缺乏真正的理解和联想能力。
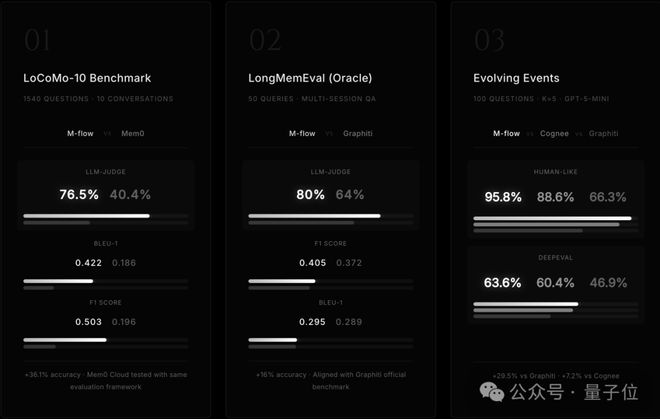
在这种背景下,一个名为M-FLOW的项目脱颖而出,它由一支平均年龄仅为19岁的年轻团队所开发,并且已经达到了世界级的技术领先水平。
M-FLOW不仅实现了国内记忆引擎领域的从无到有的突破,还坚持开源开放的原则,这无疑为未来的创新注入了新的活力和可能性。
许多人初接触记忆引擎时都会有一个疑问:人类的记忆难道不是在寻找相关信息吗?为什么AI的“记忆”却往往局限于文本形式上的相似匹配?
推倒,重来。
这个核心问题正是长期以来困扰业界的主要症结所在。从早期全量上下文硬塞式的记忆方法,到后来采用向量和关键词进行检索的方式,AI的记忆系统始终未能实现真正的理解和联想。
然而,M-FLOW通过引入图结构彻底重构了人工智能记忆的底层逻辑,并解决了粒度与联系的问题。这使得AI能够从简单的文本相似匹配跨越至具有推理能力的记忆模式。
这项技术突破背后的故事同样令人振奋:平均年龄仅19岁且来自常青藤高校的年轻人,正引领着这一领域的创新浪潮。
他们未来还能走多远?这是一个让人充满期待的问题。从M-FLOW的成功案例中,我们可以看到年轻一代在科技创新方面的巨大潜力和无限可能。

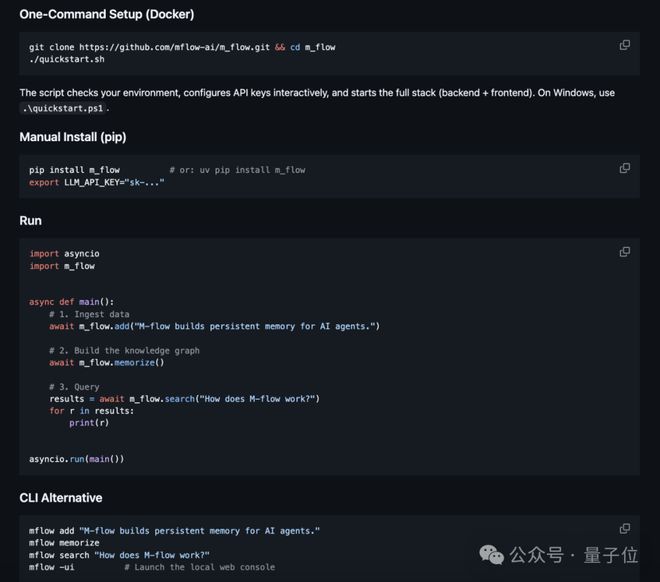
M-FLOW的项目地址为https://github.com/FlowElement-ai/m_flow ,产品网站则位于 https://m-flow.ai ,而公司官网则是 https://flowelement.ai 。
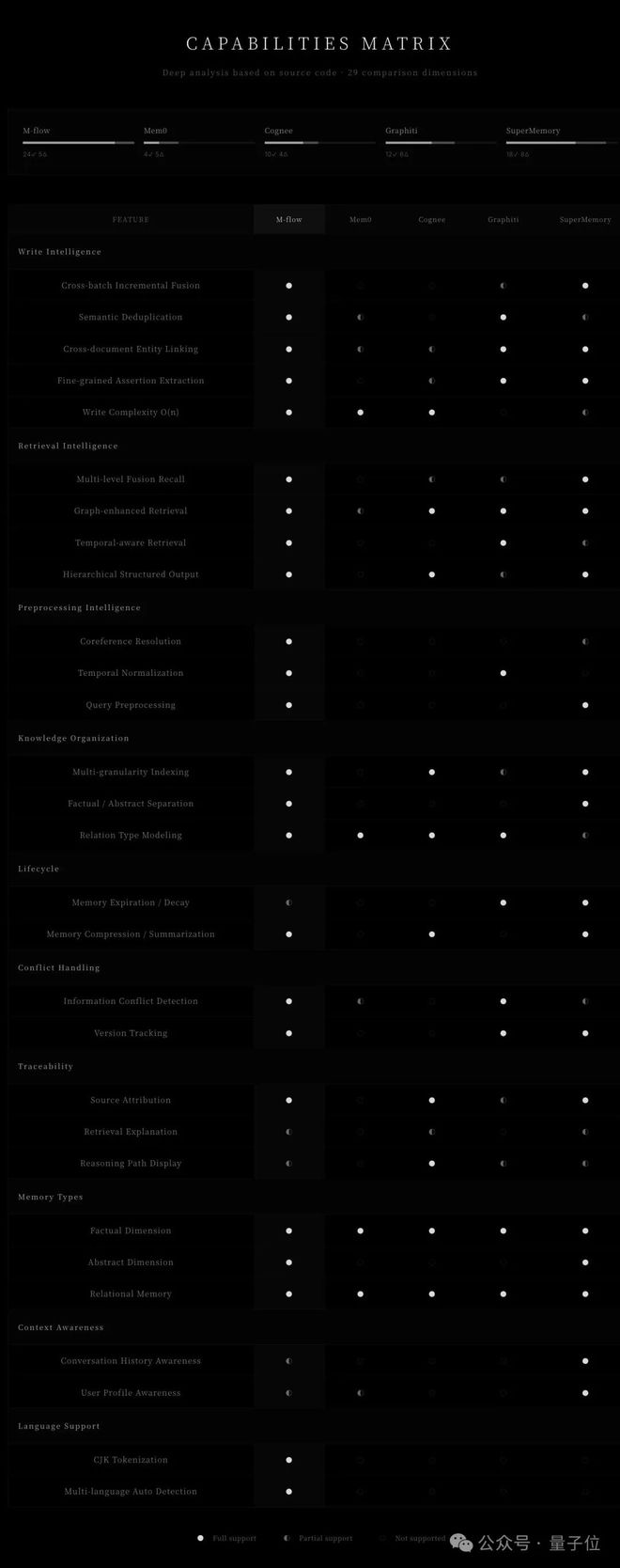
通过对图拓扑结构的应用,M-FLOW不仅能够实现多粒度检索和跨文档实体桥接的功能,还具备强大的语义噪声过滤能力。
其中代价传播机制更是实现了轻量级推理功能,无需调用大型语言模型即可完成复杂的查询任务。
此外,M-FLOW系统还引入了多种调节策略来优化检索过程中的路径选择,确保最终结果的准确性和相关性。
总而言之,图结构已成为M-FLOW检索机制的核心组成部分,为AI记忆系统的未来发展开辟了一条全新的道路。
在国内这个相对冷门的技术领域内,M-FLOW团队凭借创新思维和不懈努力实现了从无到有的跨越,并且其性能已经达到了国际领先水平。
这一系列的技术革新不仅推动了整个行业的发展,也为年轻一代在科技创新领域的成长提供了宝贵的经验与启示。
- 我们期待着这些天才少年未来能够继续探索未知领域,在人工智能的广阔天地中创造更多令人瞩目的成就。
- 跨越传统限制,M-FLOW展示了新一代记忆引擎技术的可能性和潜力,引领了AI行业的新一轮创新热潮。
- 从简单的文本匹配到复杂的图推理,M-FLOW实现了巨大的跨越,为未来的应用开发提供了无限可能。
 这些年轻开发者们的成就不仅令人赞叹,也为整个科技界注入了一股新的活力和动力。我们期待他们在未来能够继续书写辉煌的篇章。
这些年轻开发者们的成就不仅令人赞叹,也为整个科技界注入了一股新的活力和动力。我们期待他们在未来能够继续书写辉煌的篇章。
通过不断的技术创新与突破,M-FLOW团队正一步步将梦想变为现实,并为AI行业的持续进步贡献着自己的力量。
随着更多应用场景的落地,相信M-FLOW将会在未来的科技发展中扮演越来越重要的角色,引领行业向着更加智能的方向迈进。
在技术日新月异的时代背景下,年轻一代正以创新思维和不懈努力,在人工智能领域书写属于自己的辉煌篇章。
- M-FLOW的成功案例不仅激励着更多年轻人投身于科研事业中,也为整个行业的持续发展注入了新的活力与希望。
- 我们期待在未来能看到这些年轻开发者们更多的精彩表现,并为他们所创造的未来感到无比兴奋和自豪!
- 无论是在技术创新还是产品应用方面,M-FLOW团队都展现出了卓越的能力和无限潜力,成为引领行业发展的先锋力量。

随着项目的不断推进和完善,相信在未来会有更多令人期待的技术突破与应用场景涌现出来。
在这个充满机遇的时代里,我们有理由相信这些年轻的天才们将会继续书写更加辉煌的篇章,并为人类社会的进步作出贡献。
从底层逻辑重构到复杂推理实现,M-FLOW不仅解决了现有的技术瓶颈问题,还为未来的应用开发提供了无限可能。
在这个过程中所展现出的强大创新能力和不断进取的精神,无疑将成为新一代科技人才的典范与榜样。
随着M-FLOW项目的持续发展和完善,我们期待它在未来能够带来更多令人惊叹的技术突破和应用场景,引领行业迈向更加智能化的新时代。
通过引入图结构、多粒度检索及轻量级推理等一系列创新技术手段,M-FLOW不仅克服了传统记忆引擎存在的诸多局限性问题。
让记忆会关联、能推理
这些年轻开发者们所展示出来的卓越才能和创造力,无疑为整个科技界注入了一股新的活力与动力。
我们相信随着项目的发展和完善,M-FLOW将会在未来的应用开发中发挥越来越重要的作用,并引领行业迈向更加智能化的新阶段。
通过引入图结构及多粒度检索等创新技术手段,M-FLOW不仅解决了现有记忆引擎存在的诸多局限性问题。
- 它还为未来的发展奠定了坚实的基础,在未来的应用场景开发中展现出广阔的应用前景和无限可能。
- 查询与存储粒度不匹配:宏观问题检索到琐碎片段,微观问题匹配到笼统摘要;
- 同实体异语境割裂:两份文档讨论同一实体但语境不同时,向量空间中距离遥远,无法建立关联。
究其原因,是因为平坦向量检索丢弃了知识的内在结构
它能判断文本与查询的相似度,却完全不清楚这段文本在整个知识体系中的拓扑位置。
在这一点上,M-FLOW以图路由检索替代传统平坦检索,核心逻辑围绕分层知识拓扑展开,其核心洞察是:
不止找到“匹配的文本”,更要定位匹配点所属的完整知识结构,再对整个结构进行评分。
倒锥结构设计
M-FLOW将所有摄入的知识组织为一个四层有向图,形成一个倒锥(inverted cone):
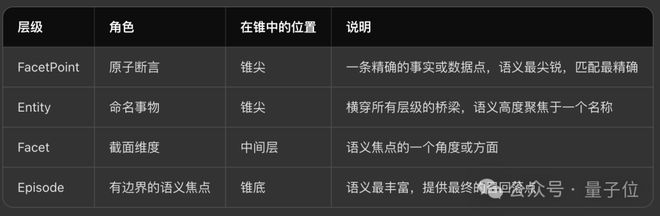
这个结构的方向性是反直觉的:在传统的知识图谱或分类树中,越往下越具体。
但在M-FLOW中,搜索的“入口在锥尖”(细粒度的Entity和FacetPoint是最容易被向量搜索精确命中的),而搜索的“目标在锥底”(Episode是最终返回给用户的知识单元)。
信息流从尖锐的匹配点向下汇聚到宽广的语义落点。
这打破了“从上到下浏览”的传统检索范式。
用户不是在层级中逐层缩小范围,而是系统在最尖锐的点上捕获信号,然后沿图结构向下传播到它所归属的完整语义单元。
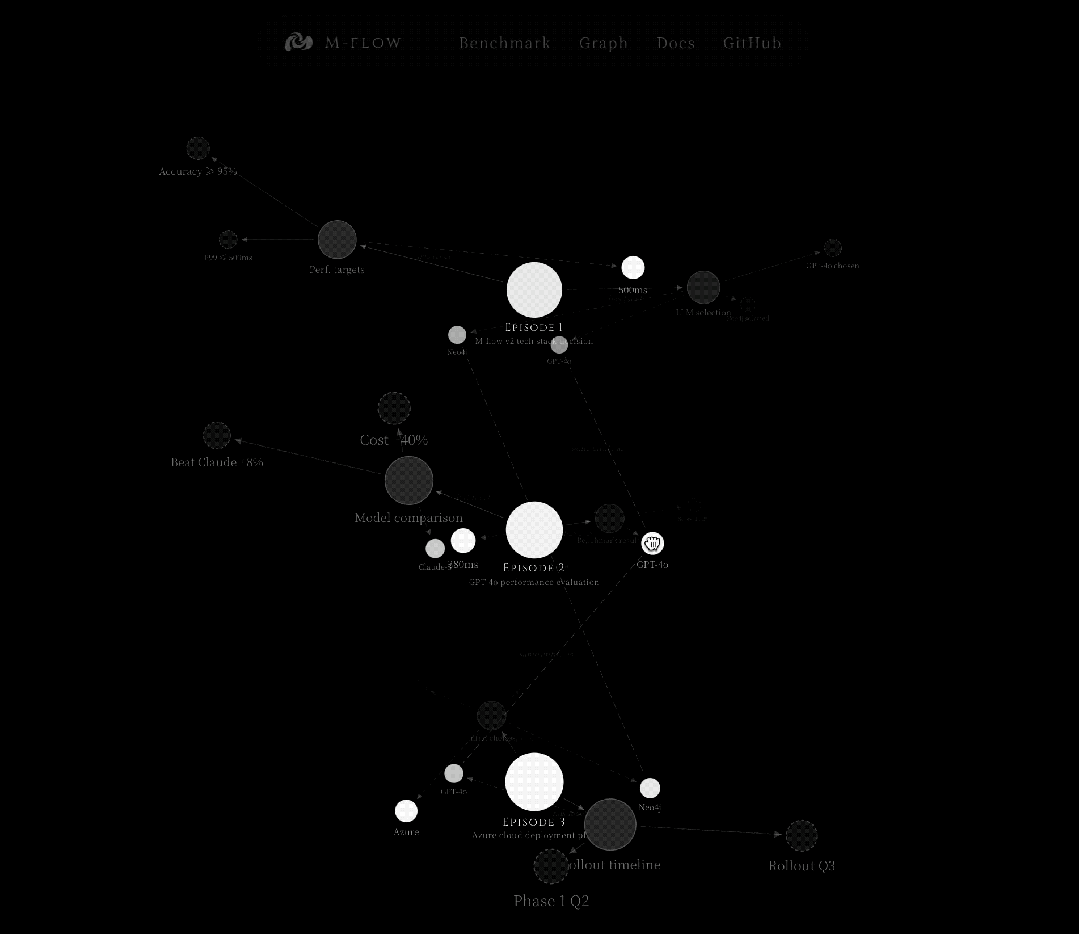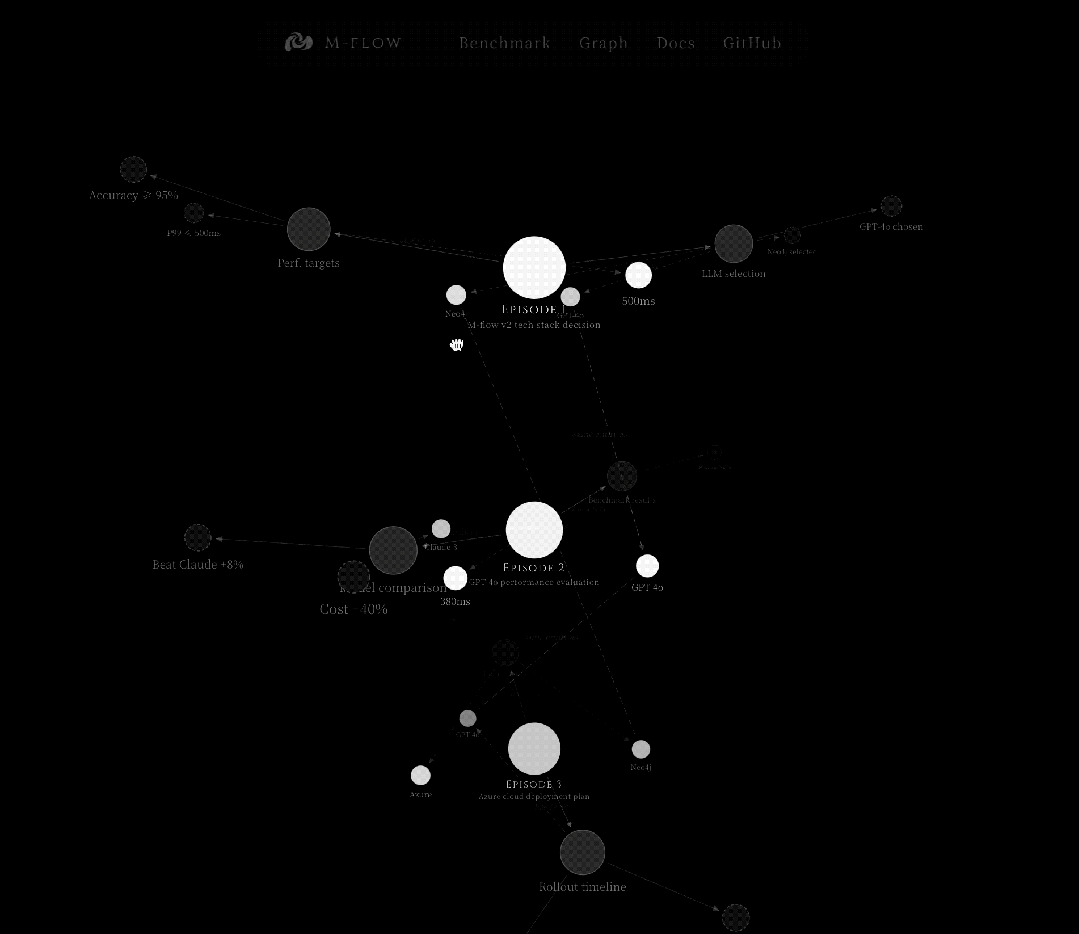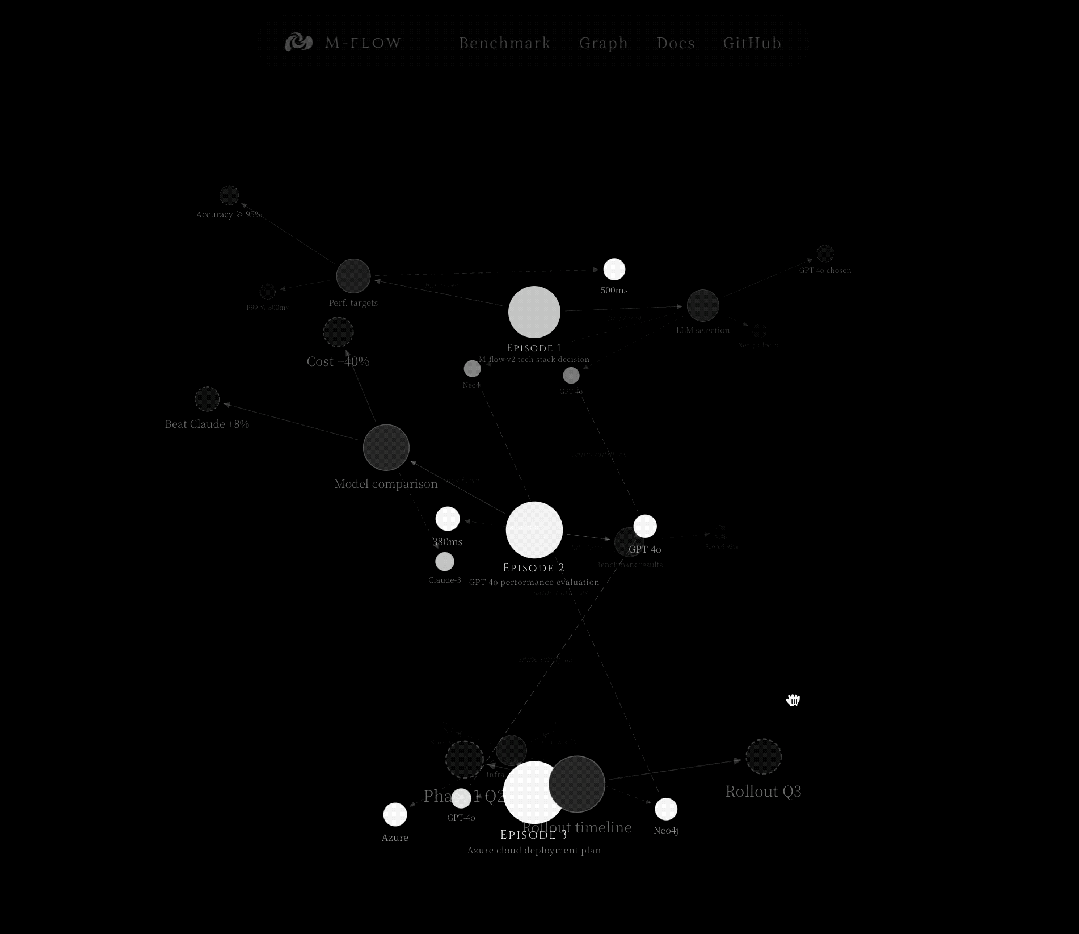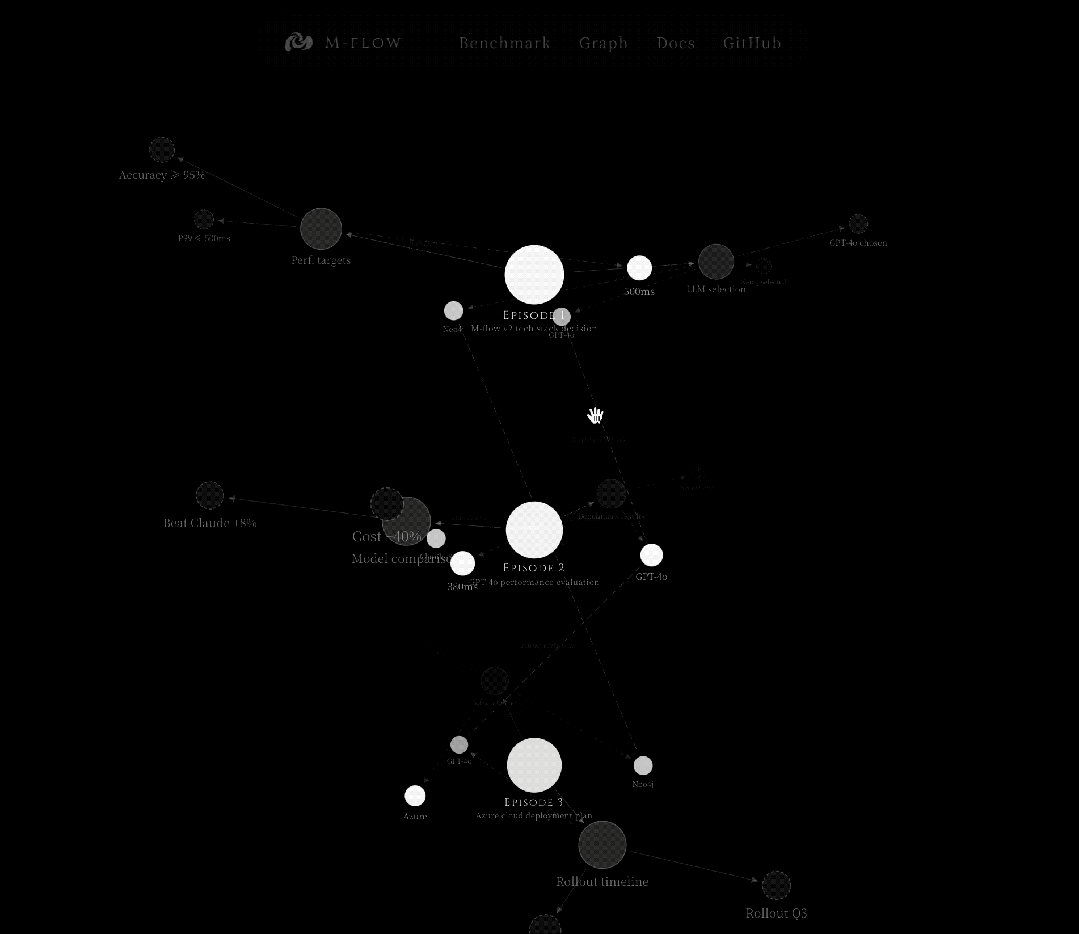
这是一个从细到粗的过程,先在最尖锐的点上捕获信号精准瞄准,然后沿图结构向下传播到它所归属的完整语义单元。
图路由Bundle Search的工作方式
当查询到达时,系统不是简单地找到最近的节点。
它通过评估图中所有可能到达每个Episode的路径,找到最优的Episode。
阶段一:在锥尖广撒网
查询被向量化后,同时在七个向量集合中搜索,从锥尖到锥底覆盖每一层。每个集合返回最多100个候选。
最容易被精确命中的是锥尖处的节点,一个Entity名称、一个FacetPoint的断言。
这些细粒度锚点的语义极度聚焦,向量距离小。
锥底的Episode摘要也可能被命中,但因为语义更宽泛,匹配通常不如锥尖精确。
阶段二:投影到图中
这些锚点被用作进入知识图谱的入口节点。
系统提取它们周围的子图,边、邻居、连接关系,然后扩展一跳邻居。
这将一组孤立的向量命中点转化为一个连通的拓扑结构。
阶段三:从锥尖向锥底传播代价
这是核心步骤,也是图路由Bundle Search的本质——
在锥尖捕获信号,沿图边向锥底传播,在Episode处汇聚评分。
对于子图中的每个Episode,系统评估从锚点到达它的所有可能路径:

每条路径的代价由三部分构成:
- 起始代价,锚点的向量距离(信号的尖锐程度);
- 边代价,沿途每条边的向量距离(连接关系与查询的相关度)加跳跃惩罚;
- 未命中惩罚,边没有被向量搜索命中时的默认高代价。
Episode的最终得分是所有路径中的最小代价。
三大打破常规的设计
1.边也携带语义,成为主动过滤器
传统知识图谱中,边(图谱中节点之间的连线)只是作为类型标签,比如’works_at’、’located_in’,不参与语义检索。
查询一个图时,你要么遍历边,要么忽略边,因为边本身不携带可被搜索的语义。
而M-FLOW中,每条边都附带自然语言描述文本,这些文本会被向量化、同样参与搜索。
这意味着边不再是被动连接器,而是主动的语义过滤器。

在代价传播阶段,系统不仅知道两个节点之间存在连接,还知道这条连接关系本身与当前查询有多相关。
这样一来,即便一条边的两个节点都被搜索命中,只要这条边本身的语义和查询无关,就会被判定为高代价,从而直接切断这条不合理的关联路径。
2.取路径最小代价,而非平均代价
为什么取最小值呢?团队主要考虑到一个检索哲学——一条强的证据链就足以证明相关性。
一个Episode可能关联10个Facet,但9个与查询都无关。
传统方式会平均所有路径代价,这就会让无关路径拉高分数;
而M-FLOW只看那条最好的路径。
只要有一个Facet通过低代价路径连接到查询,这个Episode就应该被检索到。
这也对应了人类记忆的工作方式,比如你想起一件事,通常是因为某一个线索足够强烈,而不是因为所有线索都指向它。
3.惩罚直接命中,偏好精准锚点路径
这是最反直觉的设计,当查询直接匹配了Episode摘要时,系统反而对这条路径施加额外惩罚。
惩罚最直接命中的原因是,它们和很多查询看起来相关。
一个关于项目管理的Episode摘要,可能和任何提到项目或管理的查询都有不错的向量距离。
但这种匹配是宽泛的、缺乏焦点的,这其实也反映了众多RAG系统检索噪声的根本原因。
M-FLOW系统的设计偏好,是优先选择从锥尖(FacetPoint、Entity)出发的精确路径。
即使多走几跳,也优先选择它,直接的Episode命中只在没有更好替代路径时才胜出。
这样就确保了检索结果的精确性——不是什么都沾点边的宽泛摘要,而是有具体证据链支撑的Episode。
拓扑论证
要说这套机制为什么有效,根本优势还是在于图拓扑编码了向量本身无法捕获的知识组织结构
多粒度均可找到锚点。比如问“数据库迁移发生了什么?” 这类宏观问题时,系统会直接匹配到Episode摘要。
虽然会受到直接命中惩罚,但因为没有更精确的锥尖路径,这条结果依然会胜出。
而像“P99目标是否低于500ms?” 这类精确问题,则会强匹配一个FacetPoint,从锥尖经过两跳到达Episode,极小的起始距离让整体代价非常低。
系统不需要人为选择粒度,倒锥拓扑会自动在最合适的层级找到锚点。
跨文档实体桥接。当“张博士在MIT工作”出现在文档A,“MIT发表了量子计算突破”出现在文档B时,两个Episode会共享同一个Entity节点:MIT。
用户查询MIT时,锥尖命中该实体,代价会同时向下传播到两个Episode,从而从两个独立文档中拿到关联结果,不需要LLM做额外推理,图结构本身就完成了桥接。

结构噪声过滤。在传统平坦检索中,很多语义相似但主题无关的文本片段会排在前面。
而在Bundle Search中,任何片段都必须沿着边追溯到某个Episode。
如果沿途的边和查询语义无关,路径代价会迅速升高,让不相关结果自然下沉。
图结构本身,就是一层强大的语义噪声过滤器。
代价传播即推理。图中的每一条路径,本质上都是一条推理链——
查询匹配这个事实→事实属于这个维度→维度属于这个事件。
路径代价量化了这条推理链的紧密程度,系统在2–3跳内就能完成轻量级多跳推理,检索阶段不需要调用LLM。
自适应置信度
并不是每一层向量集合对每个查询都同样可靠。
系统会为每个集合计算两个指标,绝对匹配强度与区分度,然后把集合分为“节点类”和“边类”,按置信度动态分配权重。
比如某一次查询中,Entity集合的置信度明显高于Facet集合,系统就会自动提高Entity路径的影响力。
它不是用固定权重,而是根据本次搜索中哪个粒度的命中更可信,实时调整检索策略。
一个额外的调节机制
还有一个额外的调节机制是,当某个Facet与查询向量距离极小、高度吻合时,系统会显著降低这条路径上的边代价和跳跃代价。
逻辑很直观,如果一个Facet已经几乎完美匹配查询,那么它到Episode的连接基本就是可靠的,不需要再通过边语义反复验证。
除此之外,系统还包含查询预处理、并行多模式调度、结果裁剪等机制……
所以总结来看,M-FLOW的检索并不是向量搜索+图数据库的简单叠加,图本身就是检索机制
中国记忆引擎后发先至?
在国内,外置记忆远没有国外的关注度高,然而M-FLOW团队不做同质化堆砌,实现了国产在该领域的从无到有,并且性能领先世界、还坚持开源开放……
其实很多初次接触记忆引擎的人都会有一个直观困惑,人类的回忆难道不是寻找相关信息吗?为什么AI的记忆,却总是在找文本形态相似的信息?
这个最普遍的问题,恰恰是AI记忆解决方案的核心症结。
从初代全量上下文硬塞式记忆,到第二代向量+关键词的检索式记忆,AI始终停留在文本形态匹配,离真正的理解与联想相去甚远。
而M-FLOW用图结构重构了AI记忆的底层逻辑,解决了记忆图谱的粒度与联系问题,让AI记忆完成了从形态相似匹配到联想与推理的跨越。
而且值得一提的是,这个项目是由一支平均年龄19岁、从常青藤辍学的团队独立开发的。
在AI圈里,天才少年的故事总是备受瞩目。在这次技术突破之后,我们也想知道:
这群年轻人,未来又可以走多远呢……
项目地址:https://github.com/FlowElement-ai/m_flow
产品网站地址:https://m-flow.ai
公司地址:https://flowelement.ai