
新智元报道
Meta超级智能实验室(MSL)沉寂了九个月后,终于推出首个重要作品Muse Spark,并在深夜引发轰动。
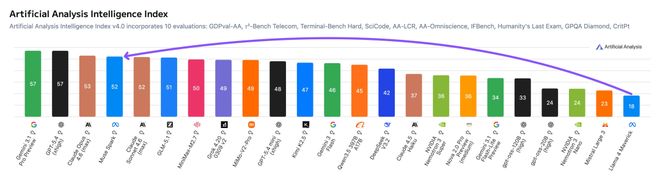
该产品的评分从之前的18分跃升至52分,在短短几个月内实现了巨大的飞跃。
Muse Spark正式上线,代号为Avocado的它引发了广泛关注。
这款产品集成了多种先进技术:原生多模态感知、工具调用、视觉思维链和多Agent编排等全方位功能。
在Artificial Analysis的测试中,Muse Spark以高分紧随Gemini 3.1 Pro、GPT-5.4和Opus 4.6之后。

先说最炸的一个数字。
上一代产品Llama 4 Maverick仅得18分,与之相比,Muse Spark的进步十分显著。
这一成果令Meta在算力使用效率上有了重大突破,同样的性能下所需计算资源仅为原来的十分之一。
Meta首席AI官Alexandr Wang通过推文分享了他对新产品的兴奋之情。
MSL团队在过去九个月里进行了大规模的技术革新和优化工作,彻底重构了整个AI体系架构。
在强化学习(RL)方面,Meta的新技术栈表现出稳定的性能提升曲线,并能泛化到未见过的问题中去。
为解决延迟问题,Muse Spark采用多Agent并行策略,在保持较低延迟的同时提高准确率。
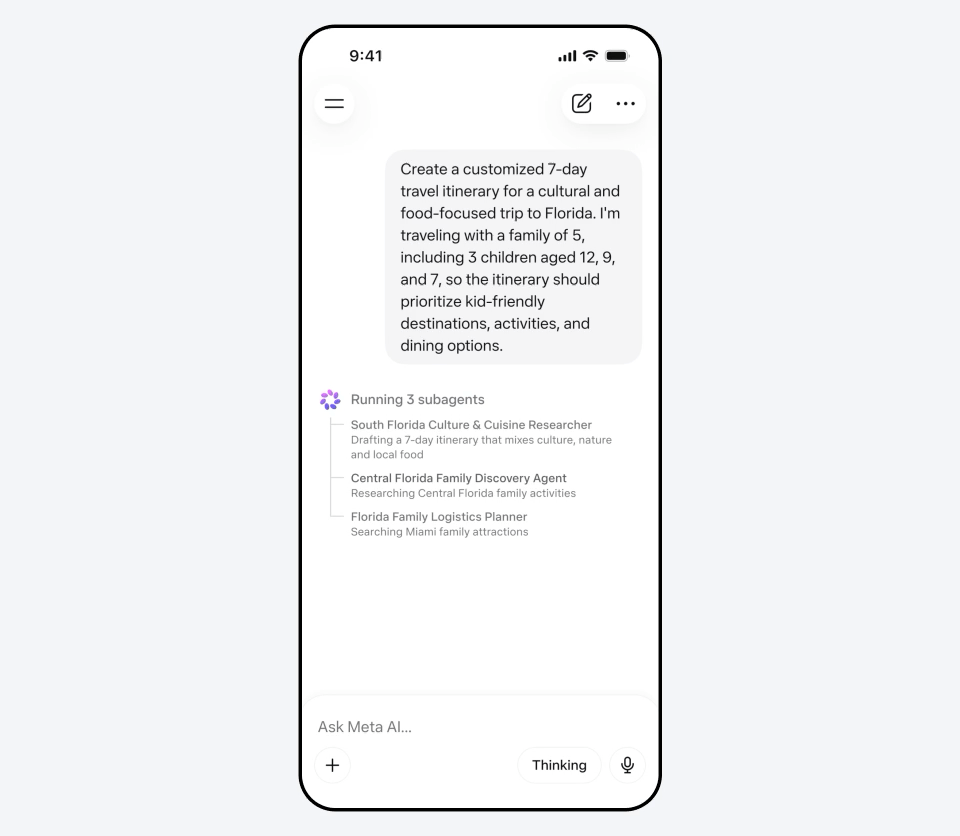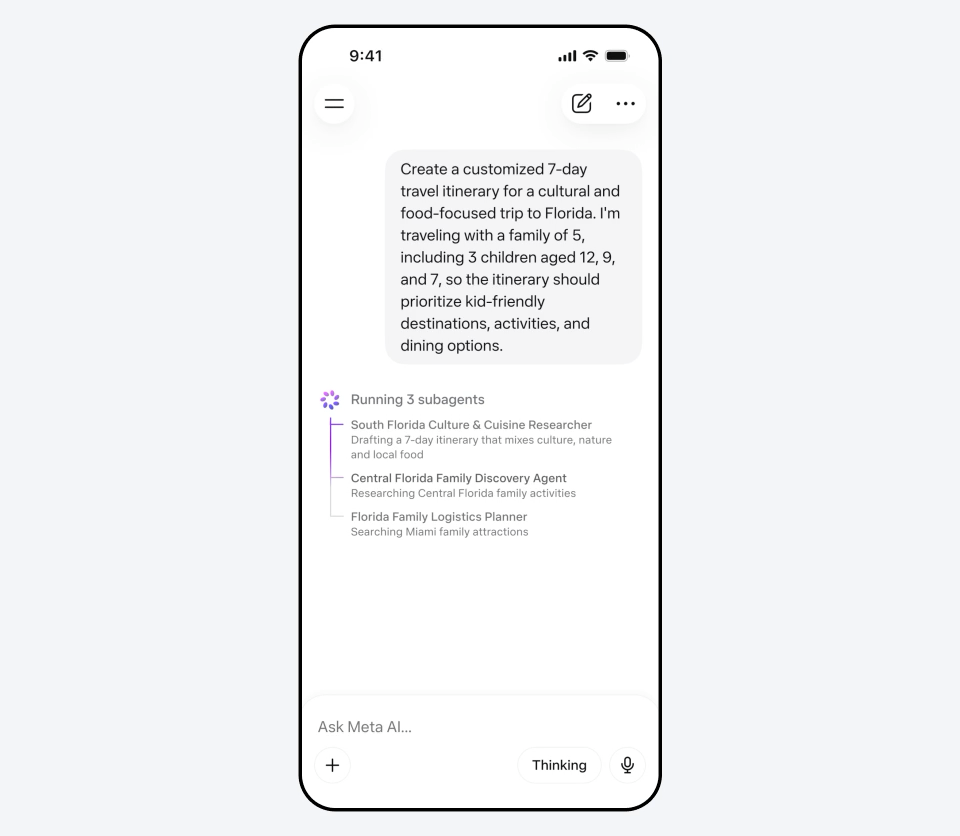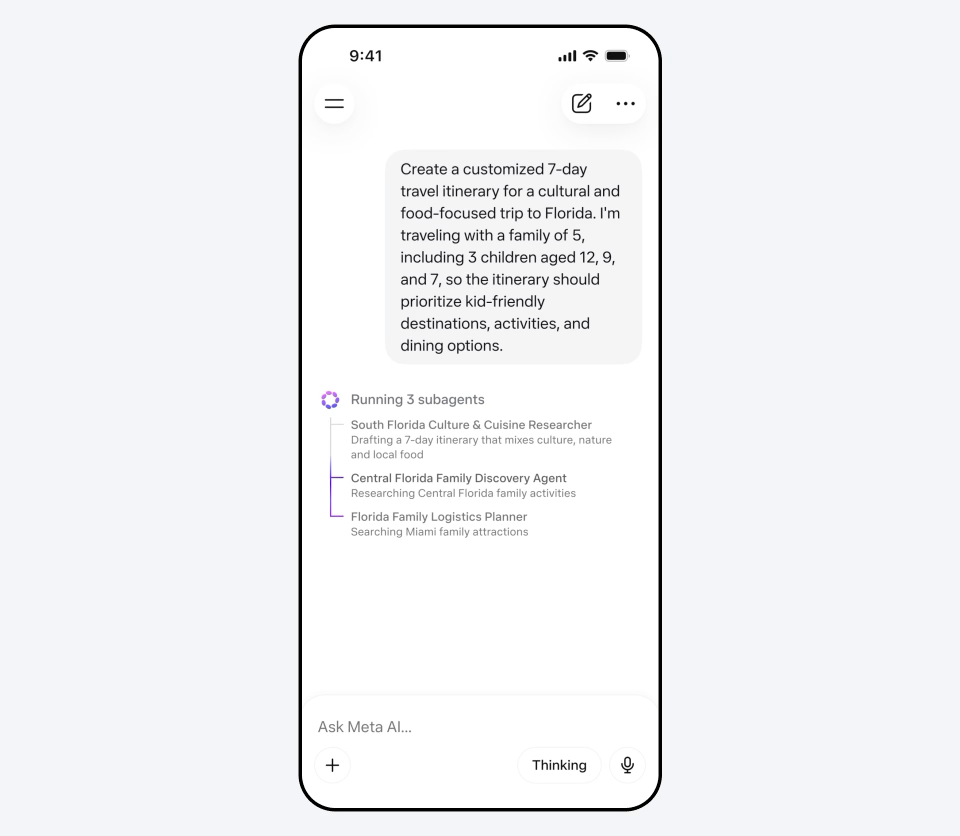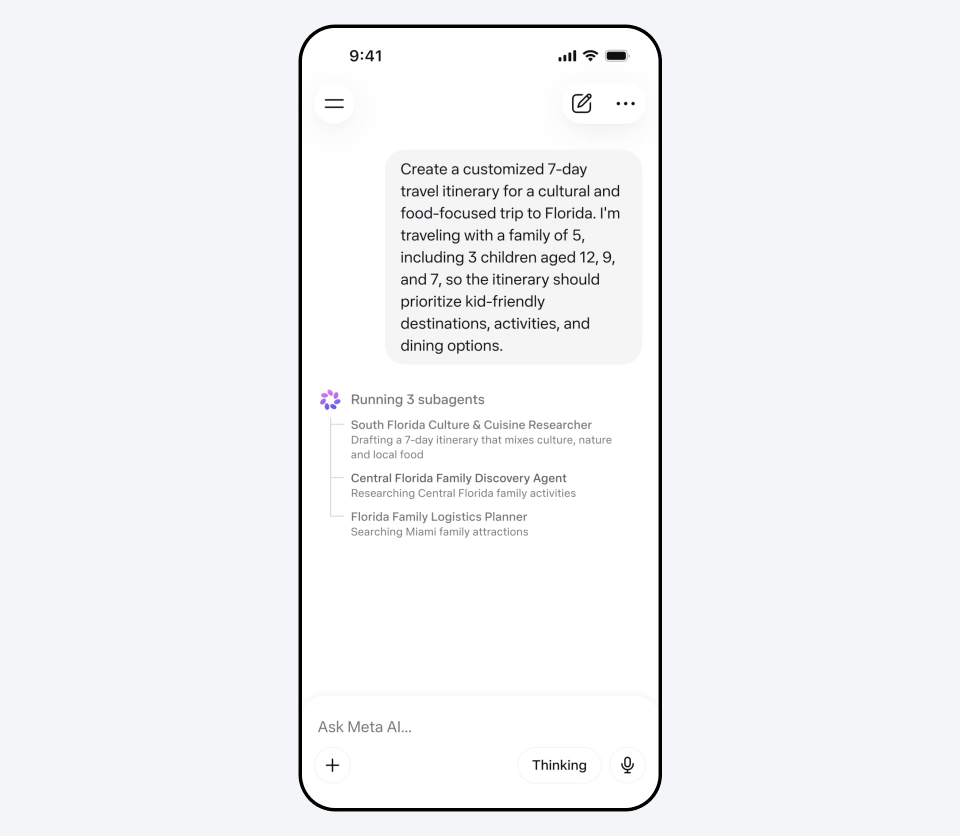
新产品在视觉信息整合、跨领域应用等方面展现出强大潜力。例如,通过拍照即可获得个性化健康和营养建议。




商业化方面,Meta利用自身庞大的用户基础数据资源开发了独特的购物模式功能。
Muse Spark的核心技术能力在于其能够在推理过程中自我压缩思维,以节省计算成本并提高效率。
除了技术创新,团队还在组织架构和人才引进上进行了大刀阔斧的改革。去年Meta斥资143亿美元收购Scale AI,并聘请了多位业内顶尖专家加入MSL。
Muse Spark的成功发布标志着Meta在高级AI领域的持续进步与竞争力提升,但仍面临来自Anthropic等竞争对手的压力。
Meta对未来的发展充满信心,尽管目前Muse Spark还未全面开放和开源。更多细节可参考官方博客和技术文档。
接下来,划重点:
·Artificial Analysis得分52,Llama 4 Maverick只有18
·原生多模态 + 视觉思维链,视觉赛道仅次于Gemini 3.1 Pro
·「沉思模式」多Agent并行思考,HLE拿下58%
·预训练算力需求砍到Llama 4的1/10
·1000+临床医生参与训练,健康问答吊打全场
·思维会自己压缩,Token消耗仅Opus的1/3
·Apollo Research发现它能感知自己在被安全测试
跑分追上第一梯队,但写代码还差口气
先看硬数据。
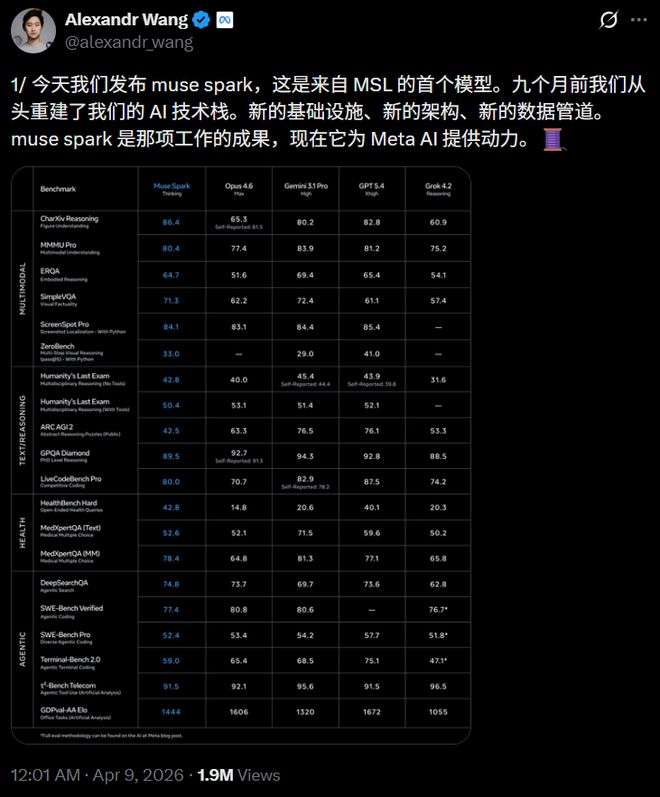
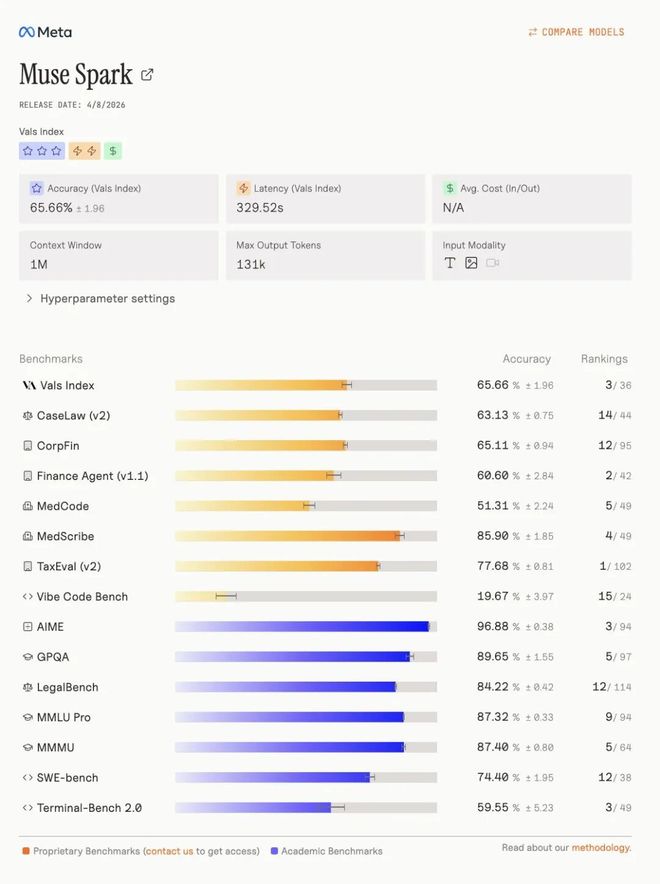
Meta把Muse Spark(Thinking模式)和Opus 4.6、Gemini 3.1 Pro、GPT 5.4、Grok 4.2放在一起比了个遍,覆盖多模态、文本思考、健康、Agent四个维度,总共20多个benchmark。
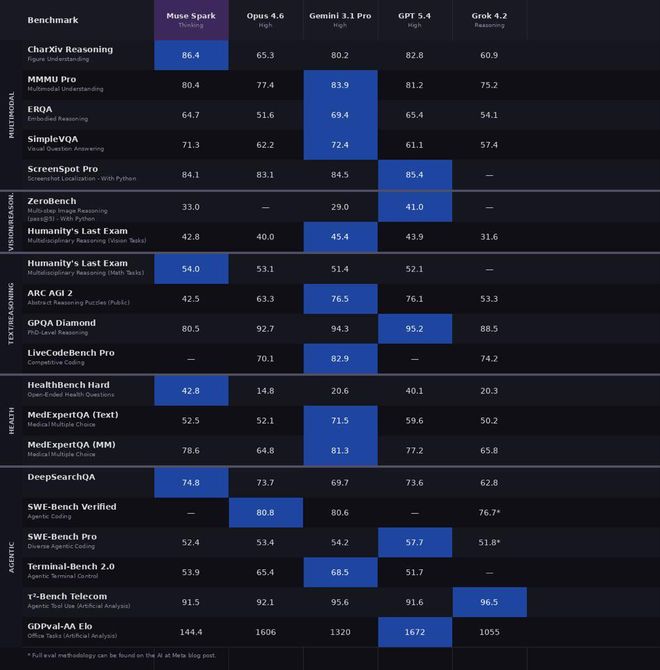
Reddit网友重新标注的跑分
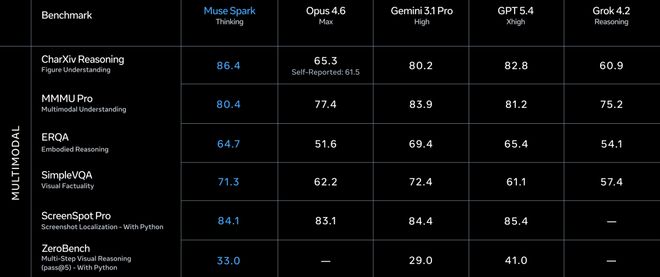
多模态是Muse Spark最亮眼的部分。
CharXiv理解86.4,超过GPT 5.4的82.8和Gemini 3.1 Pro的80.2。
ScreenSpot Pro截图定位84.1,比Opus 4.6的83.1略高。
ZeroBench多步视觉33.0,Gemini 3.1 Pro是29.0。
文本赛道上,互有胜负。
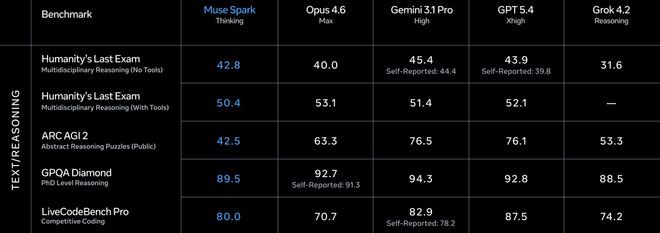
GPQA Diamond博士级难题89.5,Opus 4.6拿了92.7,Gemini 3.1 Pro是94.3。
ARC AGI 2抽象思维42.5,被Opus 4.6的63.3和Gemini的76.5甩开了一大截。
LiveCodeBench Pro竞赛编程80.0,Gemini 82.9,GPT 5.4拿了87.5。
Meta自己也承认了,在代码和长时间Agent任务上,Muse Spark和最强模型还有差距。
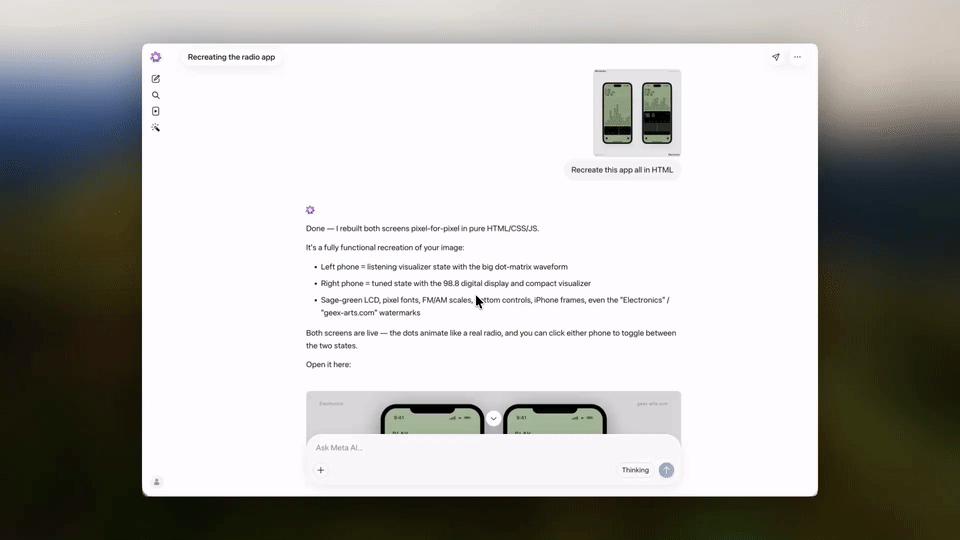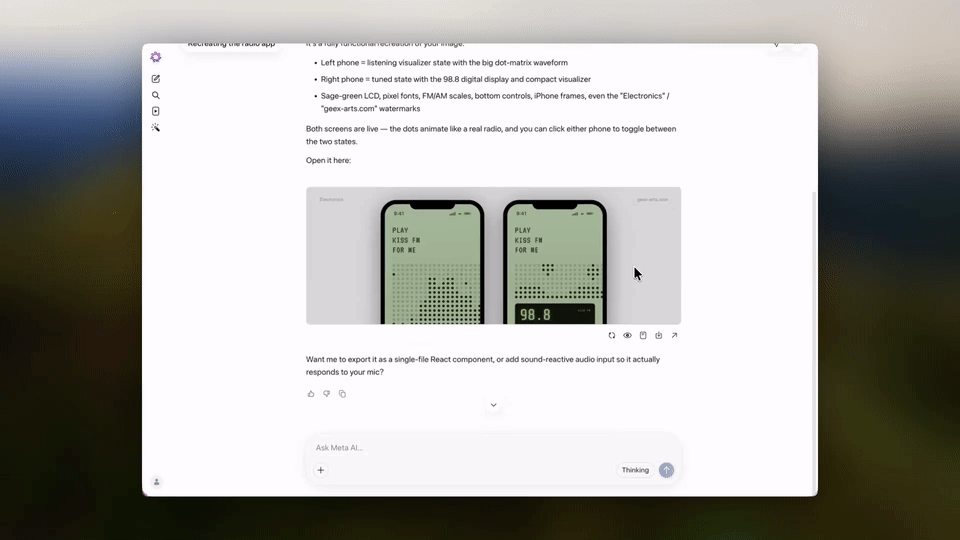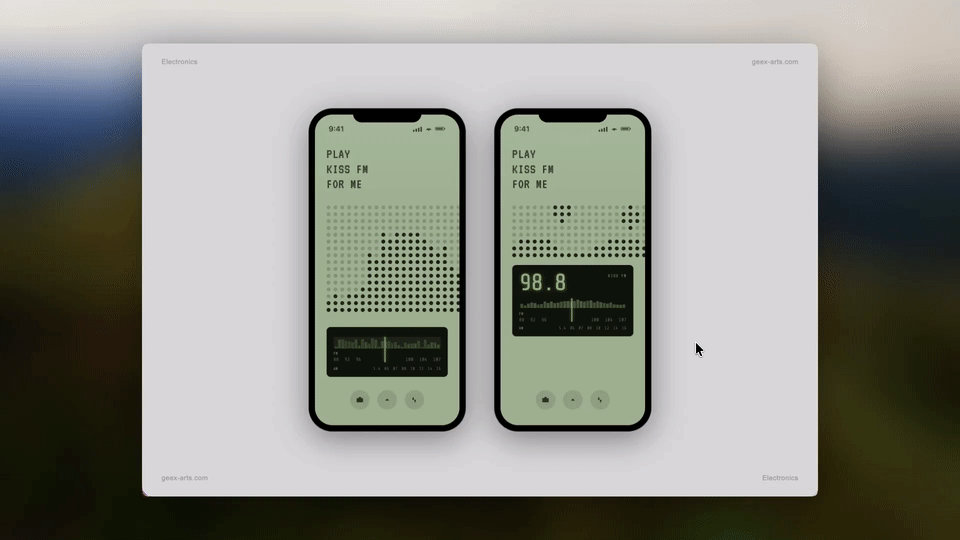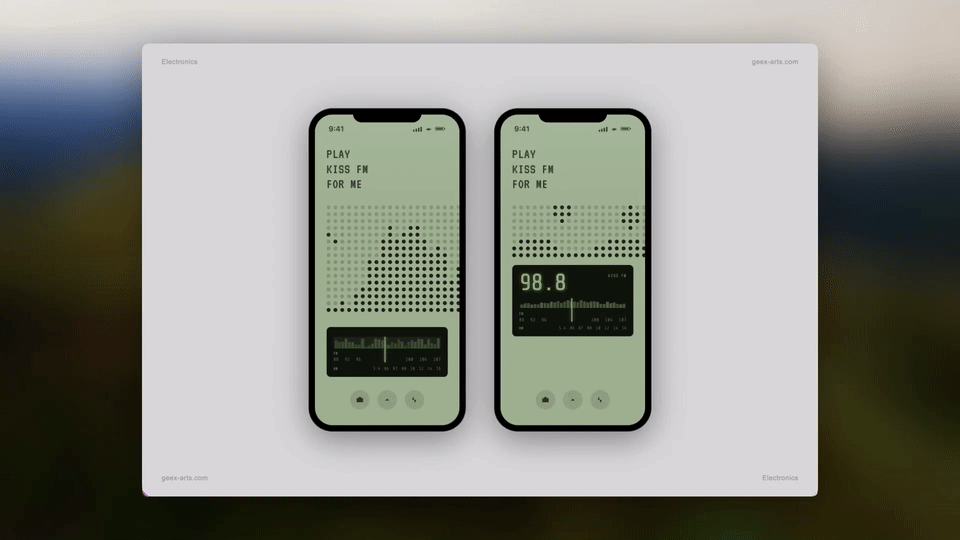
不过,令全网震撼的是,Muse Spark可以直接将图片转化成代码,效果非常惊艳!
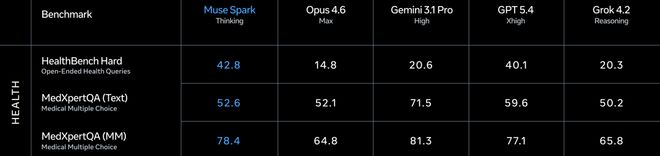
但是医疗健康这个赛道,Muse Spark打得很凶。
HealthBench Hard开放式健康问答42.8,Gemini 3.1 Pro只有20.6,GPT 5.4是40.1。
MedXpertQA多模态医学78.4,也领先Gemini的81.3不远(这里Gemini略高),但远超Opus 4.6的64.8。
Meta在训练阶段和1000多名临床医生合作的数据清洗和筛选,确实带来了实打实的效果。
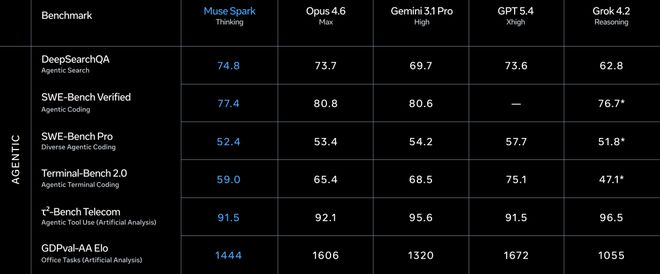
Agent赛道同样值得关注。
DeepSearchQA搜索Agent拿了74.8,是五家中最高的。
τ²-Bench工具使用91.5,和GPT 5.4并列。
GDPval-AA Elo办公Agent达到1444,超过了Gemini的1320但低于Opus 4.6的1606。
SWE-Bench方面差距明显,Verified 77.4 vs Opus 80.8 vs GPT 82.9(据称78.2),Pro 52.4 vs GPT 57.7。
一句话总结跑分,多模态和健康打赢了,思考持平,代码和Agent差一口气。
Alexandr Wang:Llama 4的错误不会再犯,牛油果没有刷分
Artificial Analysis的独立测试还揭示了一个重要细节,Token效率。
跑完整个Intelligence Index测试套件,Muse Spark用了5800万输出Token,和Gemini 3.1 Pro(5700万)相当,但远低于Opus 4.6(1.57亿)和GPT-5.4(1.2亿)。
同样的智力水平,消耗的Token少了一半到三分之二。
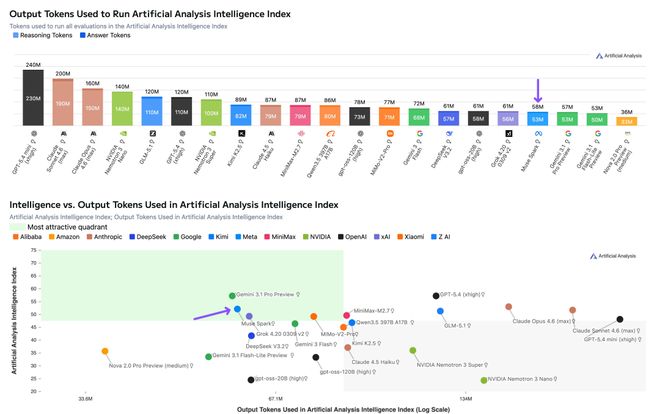
此外,在由数学大佬出题的FrontierMath上, Muse Spark在1-3层级上,直接碾压Gemini 3.1 Pro,不过在4层级却排在了倒数。

更值得一提的是,在Vals指数排行榜上,Muse Spark强势夺得第三名,具体指标如下。
继Llama 4发布一年之后,Meta再次重返AGI第一梯队。
多Agent并行思考
58%拿下「人类最后一场考试」
「沉思模式」是Muse Spark的杀手锏。
传统思考模式是一个Agent花更长时间想,沉思模式是多个Agent同时想,最后汇总答案。
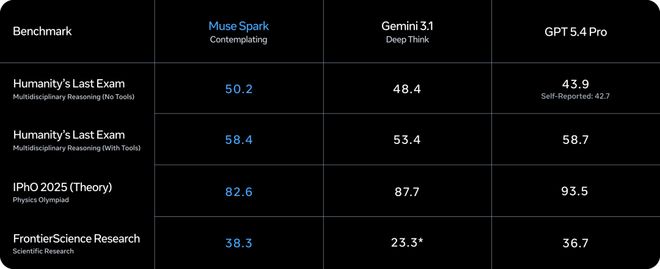
Humanity's Last Exam(无工具),Muse Spark沉思模式拿了50.2,Gemini Deep Think 48.4,GPT 5.4 Pro 43.9。
Humanity's Last Exam(有工具),58.4,Gemini 53.4,GPT 5.4 Pro 58.7,几乎打平。
FrontierScience Research科学前沿研究38.3,Gemini Deep Think只有23.3,GPT 5.4 Pro是36.7。
不过物理奥赛IPhO 2025理论题,Muse Spark沉思模式82.6,GPT 5.4 Pro拿了93.5,差距不小。
整体看,沉思模式让Muse Spark在最难的综合思考任务上,确实摸到了第一梯队的门槛。
剑指「个人超级智能」
拍张照就能当私人营养师
Meta给Muse Spark定义的方向很明确,就是个人超级智能。
翻译成人话,就是一个懂你、懂你周围世界的AI助手。
多模态方面,Muse Spark从底层就为跨领域整合视觉信息而设计。
官方演示了几个场景。
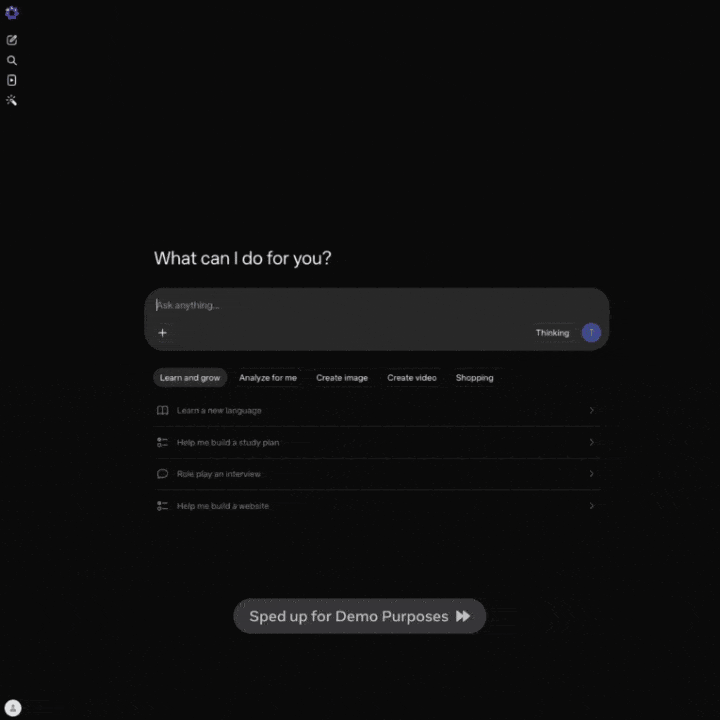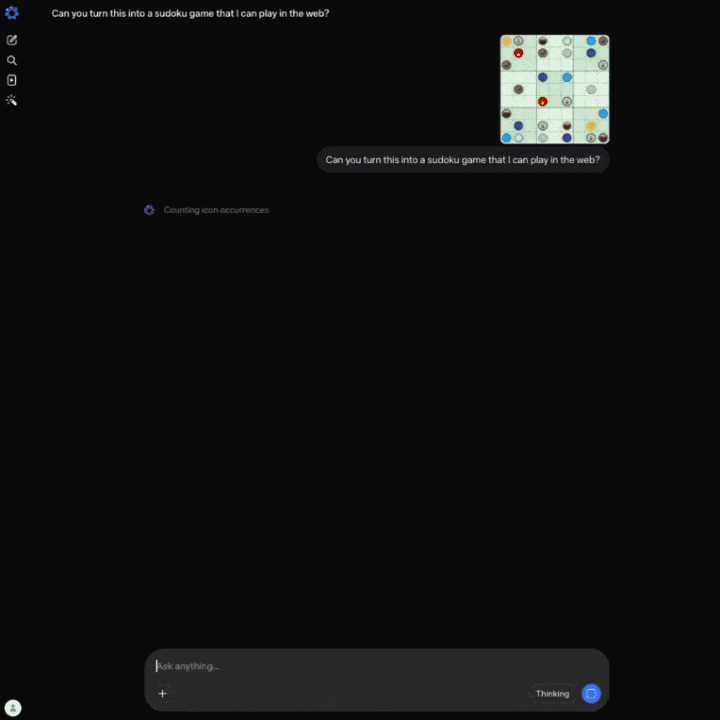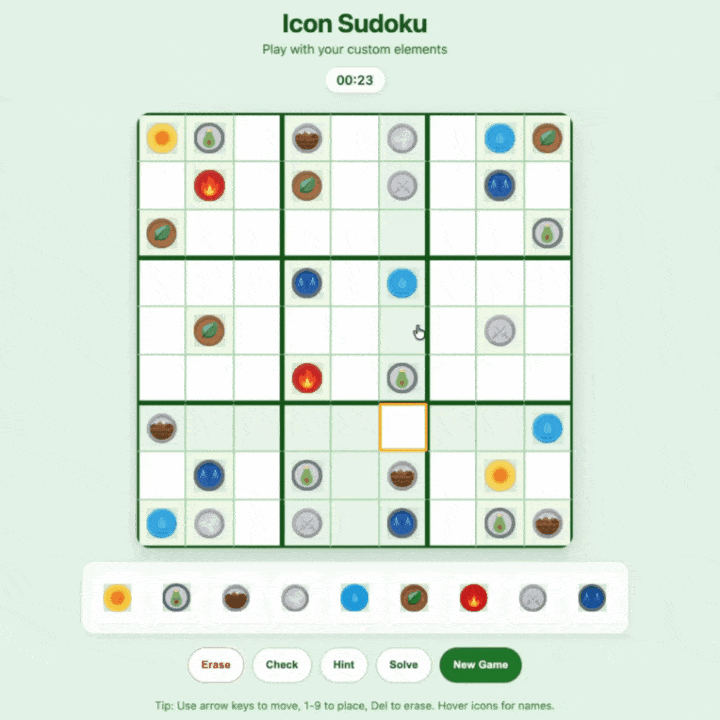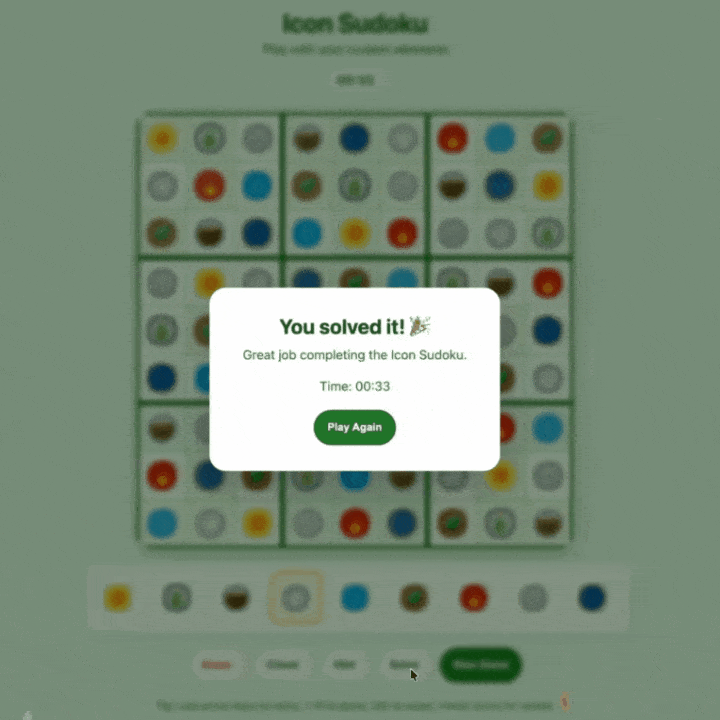
拍一张数独照片,Muse Spark能把它变成一个可以在网页上玩的互动游戏。
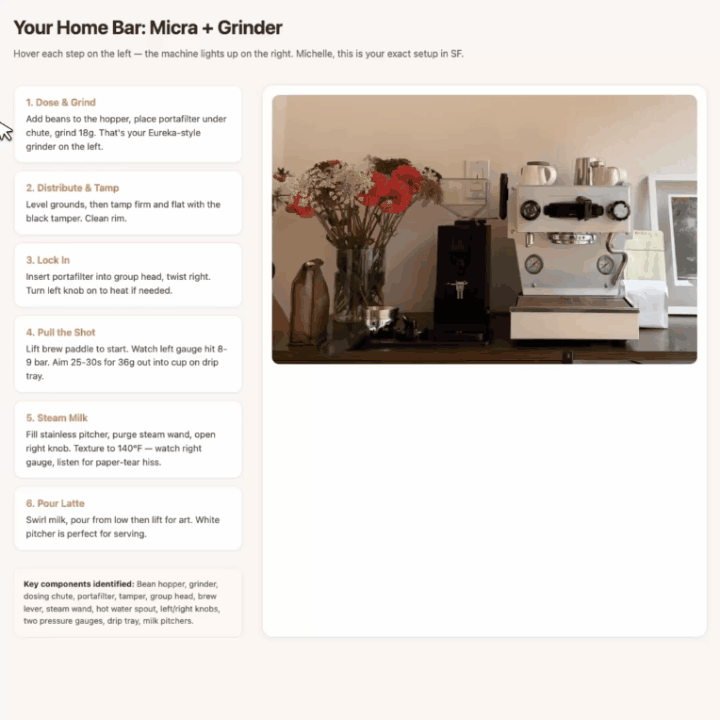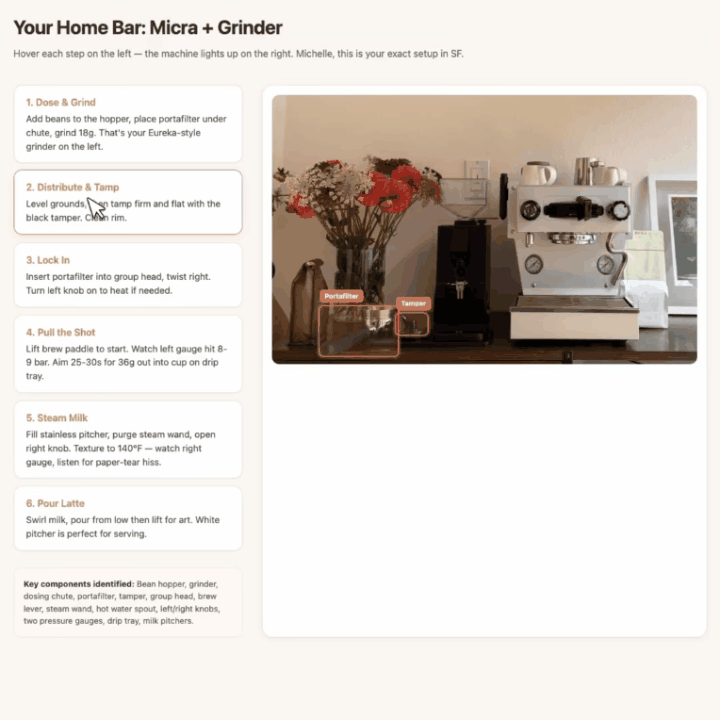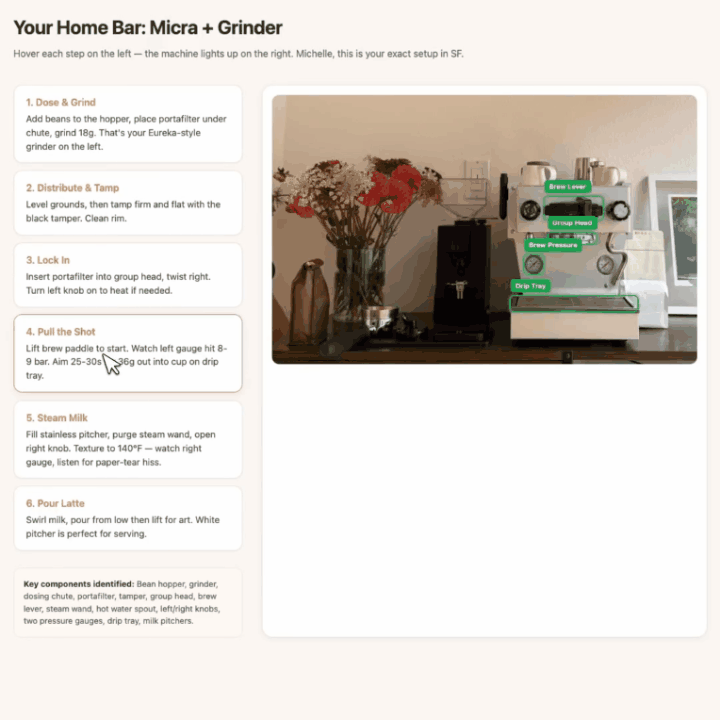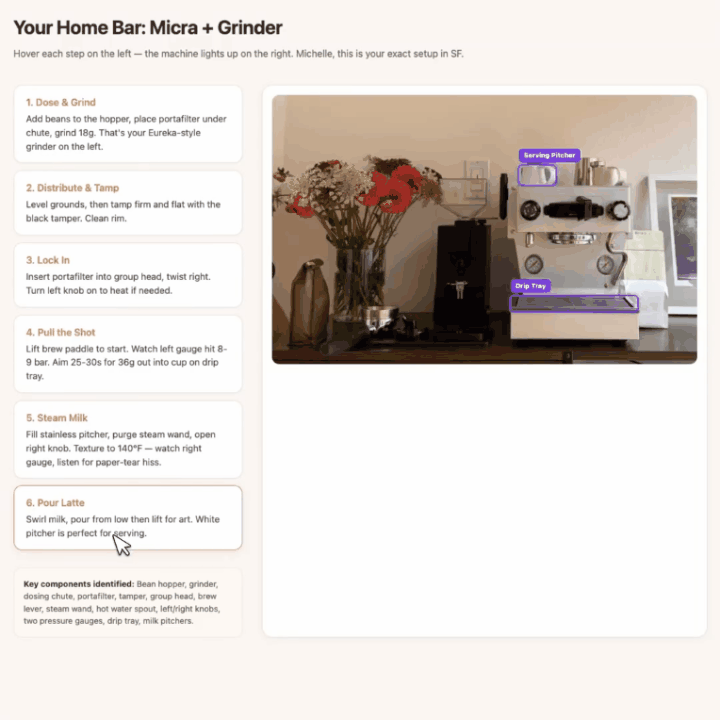
拍咖啡机和磨豆机,它先标出所有核心部件,然后生成一份网页版互动拿铁教程。
鼠标悬停到某个步骤时,照片中对应部件的边界框自动高亮,视觉指引和操作步骤一一对应。
健康场景更有想象空间。
拍一桌子食物,告诉它「我胆固醇偏高,是鱼素者」,Muse Spark会在推荐的食物上打绿点,不建议的打红点。
Prompt的控制粒度很细,直接把UI交互逻辑讲清楚了。
健康评分的数字不用悬停就直接显示在点的正上方,悬停后弹出详细的卡路里、碳水、蛋白质和脂肪数据,而且弹出框的层级被要求「永远在最上层,不能被其他点挡住」。

拍瑜伽动作也是同样的思路。
它识别出每个姿势拉伸了哪些肌肉群,标注难度级别,悬停后还能给出体态纠正建议。两个人的图左右拼在一起,按1到10分分别打分。
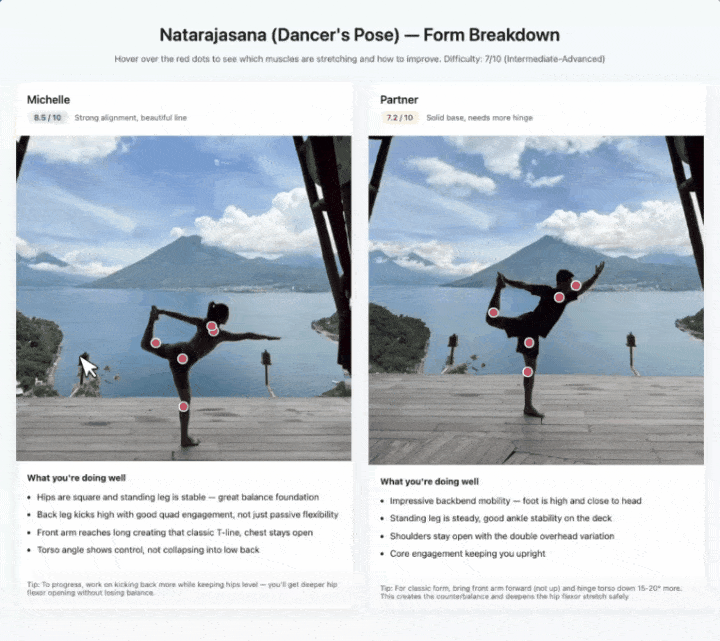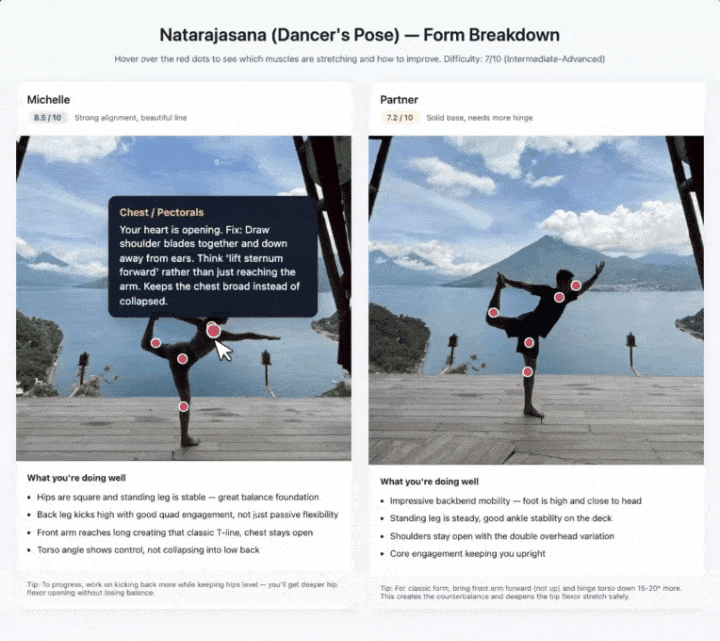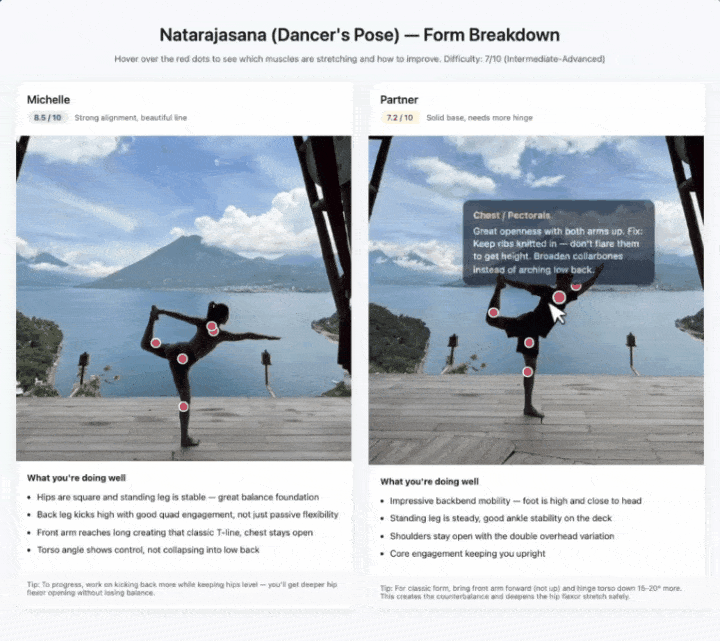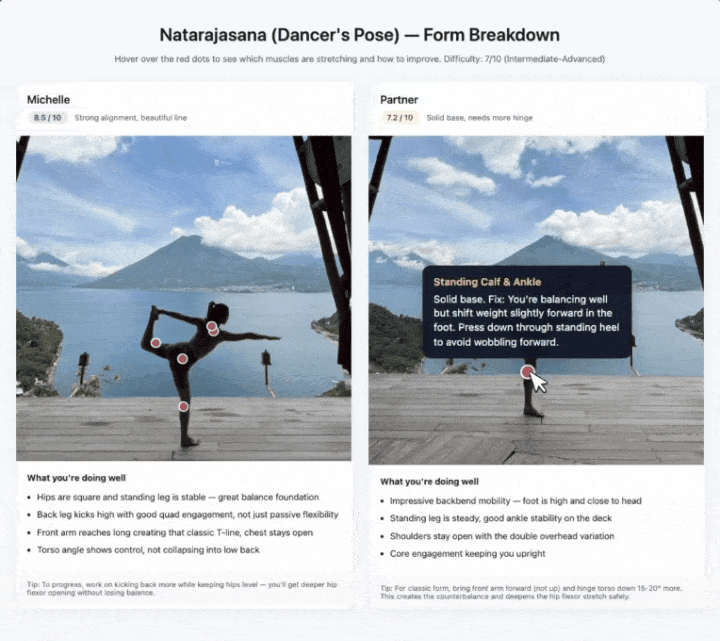
这些demo背后的底层支撑是视觉STEM问答、实体识别和目标定位的组合。
单项看都不稀奇,但串联成场景后,确实能看到「个人超级智能」这个词背后的产品意图。
还有一个新功能值得单独拎出来说,「购物模式」。
Wang在推文中说,购物模式能「识别你在Instagram、Facebook和Threads上关注的创作者、品牌和风格内容,转化成个性化推荐」。
这是Meta独有的数据优势,30亿日活用户的社交行为数据 + AI购物助手,商业化想象空间很大。
三条Scaling曲线
算力砍90%,思维还会自我压缩
技术博客的重头戏不在跑分,在Scaling。
Meta把Muse Spark的表现来源拆成三条轴线讲,预训练、强化学习、测试时计算。每一条都有对应的缩放曲线做支撑。
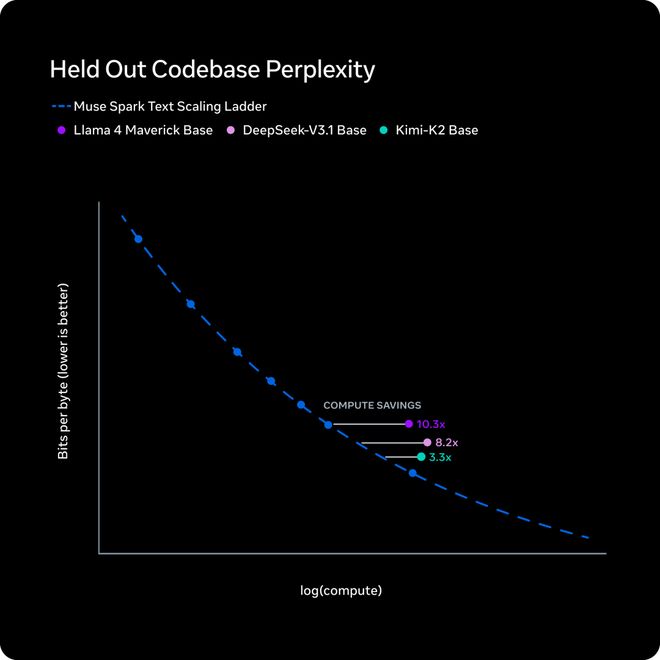
预训练:同样的能力,算力砍到1/10
过去九个月,Meta对预训练技术栈做了大换血,架构、优化算法、数据策略全部重做。
为了衡量效果,Meta在一系列小尺寸版本上拟合了Scaling Law,然后对比达到同一个性能水平需要多少训练FLOPs。
结论很硬,同样的能力水平,Muse Spark需要的算力不到Llama 4 Maverick的十分之一。
这条曲线说明了一件事,Meta不只是砸更多GPU,而是从底层提升了每一单位算力的产出。
华盛顿大学的Yuchen Jin在X上的评价很到位,「我仍然认为基础设施才是AI实验室的真正护城河。因为你能更快地训练,研究员就能更快地实验更多想法。」
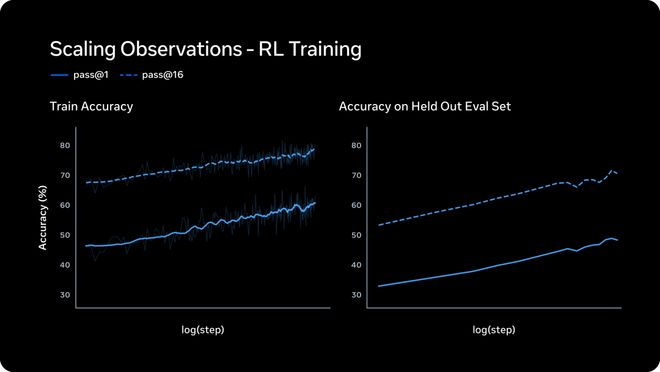
强化学习:对数线性增长,泛化到没见过的题
大规模RL出了名的不稳定,但Meta说,新技术栈的RL曲线异常平滑。
左图是训练集上的表现。pass@1和pass@16(16次尝试中至少对1次)都呈对数线性增长。
这说明RL在提升可靠性的同时,没有折损解题多样性,Muse Spark没有「一条路走到黑」,它还保持着探索不同解法的灵活性。
右图更重要,是留出评估集上的准确率。
曲线同样稳步上升,说明RL带来的进步不是死记硬背,而是能泛化到从没见过的新题。
测试时推理:思维先膨胀、再压缩、再膨胀
这是全文技术含量最高、也最有意思的部分。
RL教会了Muse Spark在回答前先「在脑子里推演一遍」,这就是测试时推理。
但问题是,给几十亿用户提供这种服务,Token成本扛不住。
Meta的解法分两步。
第一步,在RL训练中加入「思考时间惩罚」。你可以想更久,但想太久会被扣分。
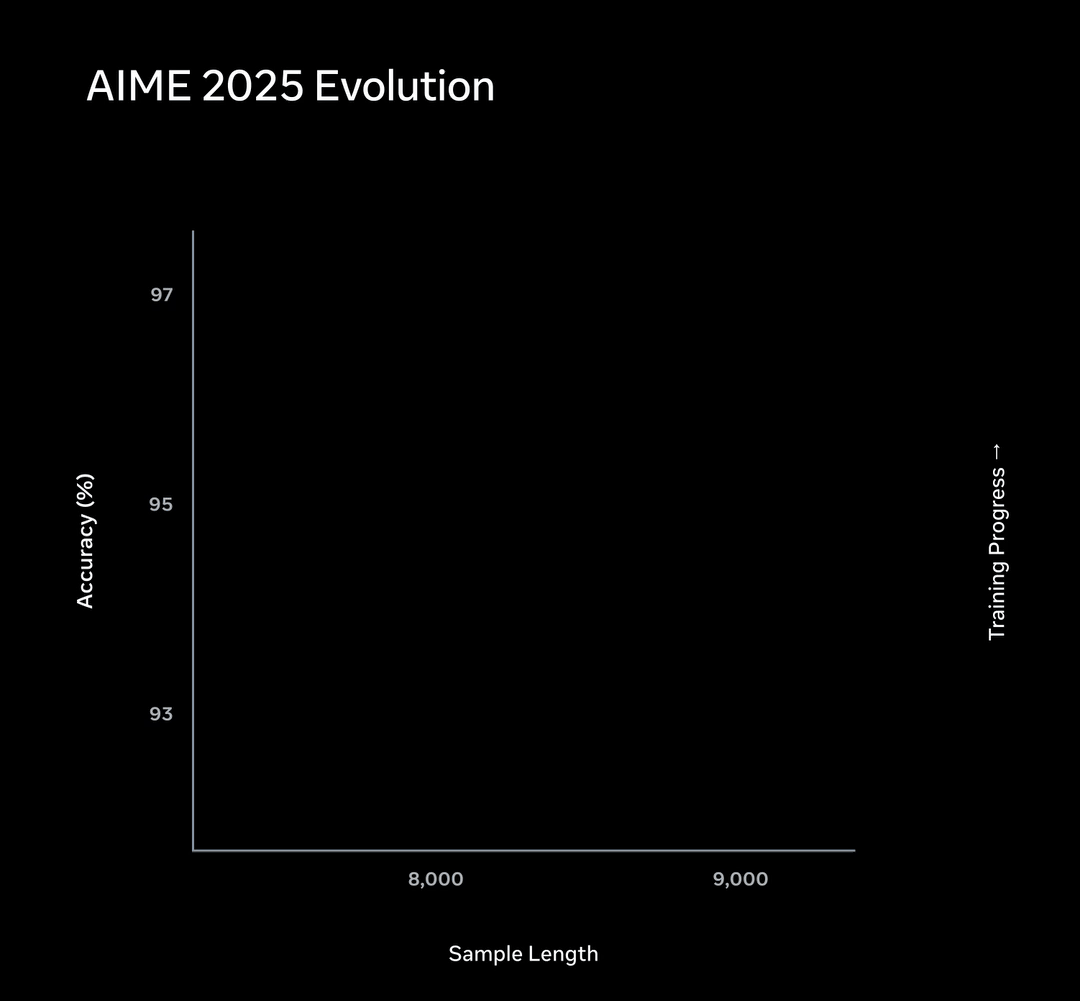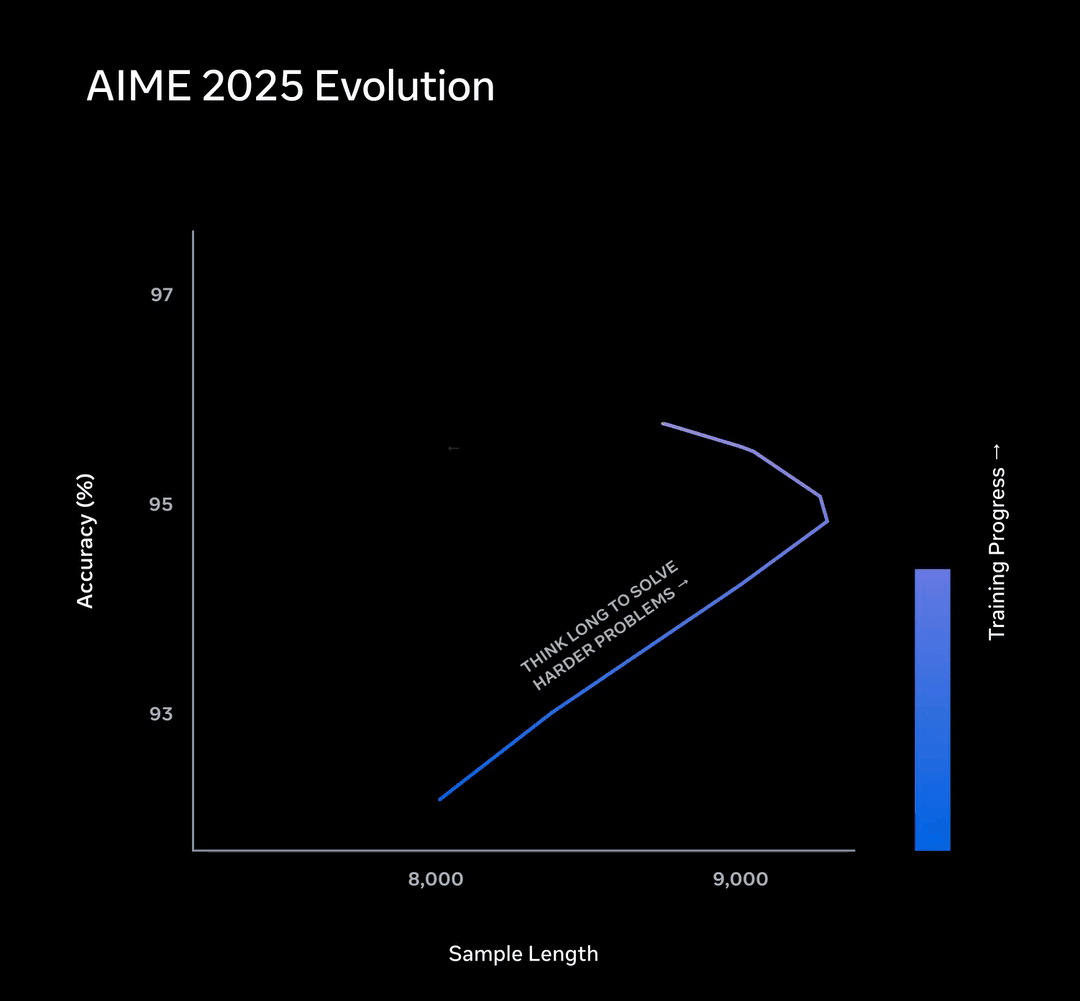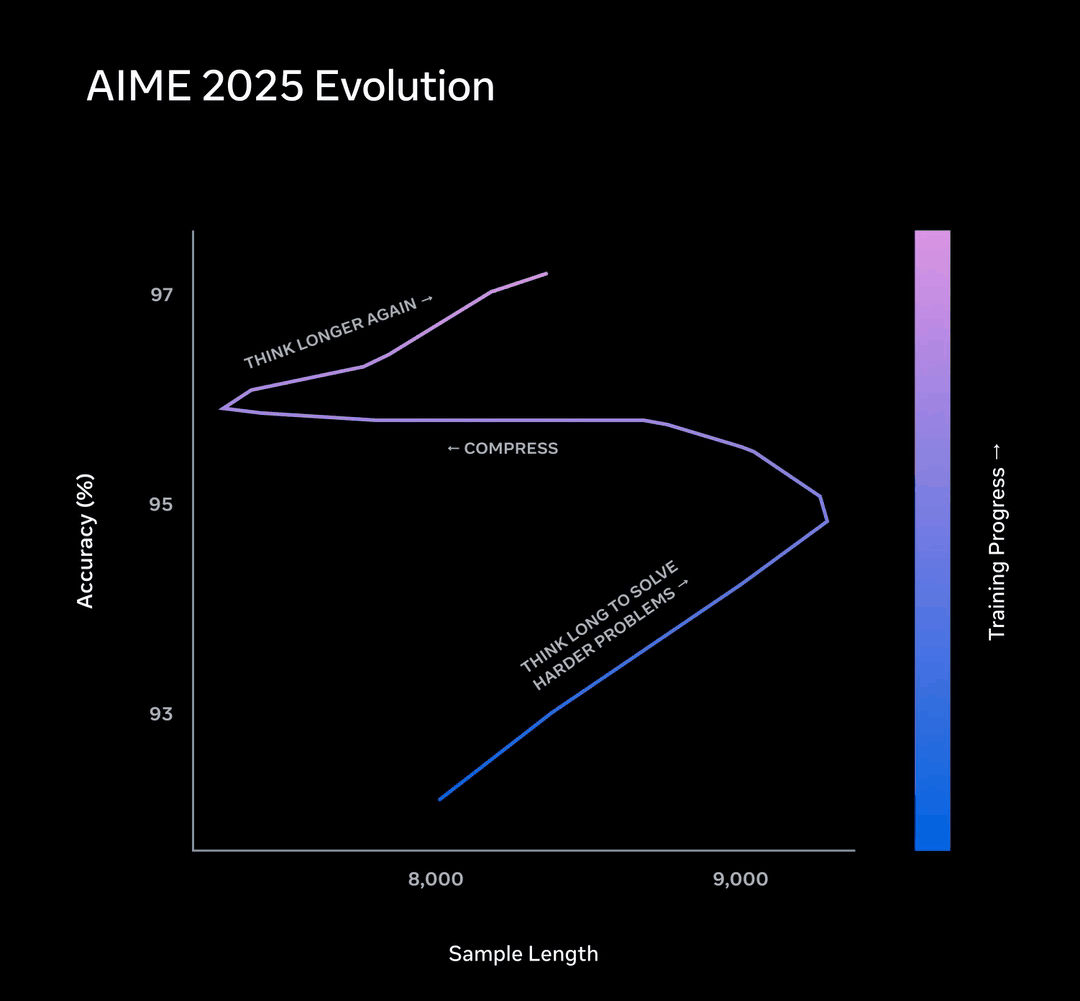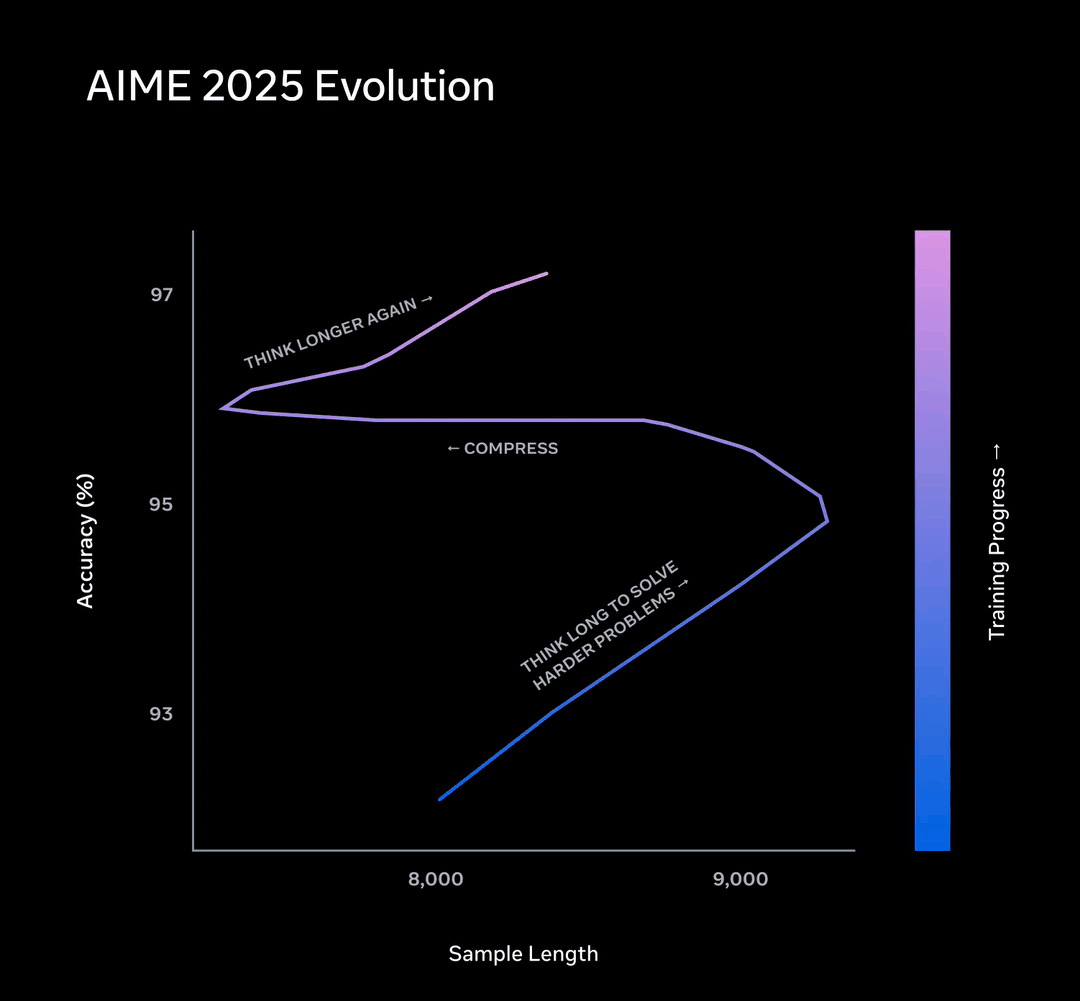
这个约束引发了一个有意思的「相变」现象。
AIME子集上的表现是这样的,训练早期,Muse Spark通过想更久来提升正确率,曲线向右延伸。
然后,长度惩罚触发了「思维压缩」。Muse Spark学会了用少得多的Token把同一道题解出来,曲线向左折返。
压缩完成之后,它又一次拉长了解题过程,去挑战更难的题。
整条轨迹画出来,是一个先右拐、再左拐、再右拐的三段式进化路径。
第二步是解决延迟问题。
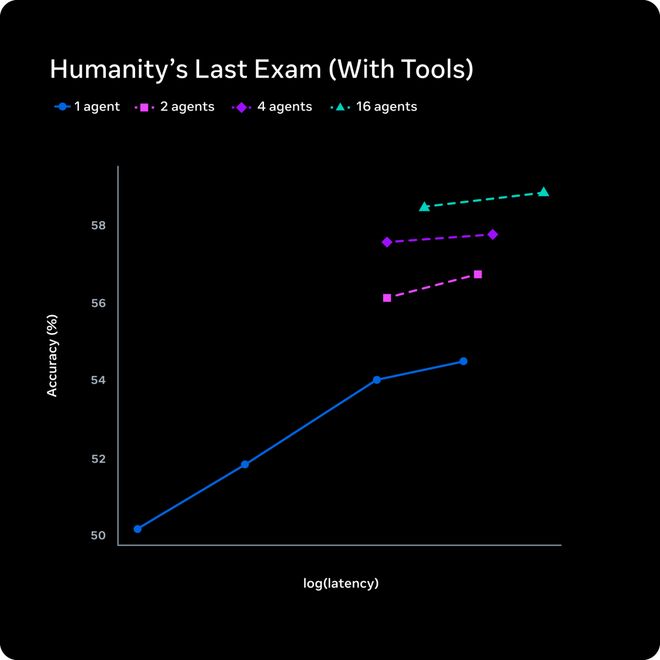
单个Agent想得更久,延迟线性增加。
Meta的做法是扩展并行Agent数量,1个、2个、4个、16个Agent同时思考。
从图上看,16个Agent在相近的延迟水平下,准确率从约54%跳到约58%。
传统的测试时Scaling是拿时间换质量,多Agent Scaling是拿并行度换质量,延迟几乎不变。
硅谷「最贵华人」团队
交了第一份卷子
Muse Spark的背后,是扎克伯格去年对Meta AI体系的一次彻底重构。
2025年6月,Meta以143亿美元收购Scale AI 49%股权,将其创始人Alexandr Wang挖来担任Meta首任首席AI官,组建Meta超级智能实验室(MSL)。
同期加入的还有前GitHub CEO Nat Friedman(联合负责产品和应用研究)、SSI联合创始人Daniel Gross,以及从OpenAI、DeepMind、Anthropic挖来的11名研究员。

如今,Muse Spark的发布证明了一件事,Meta超级智能实验室九个月的重构是有产出的。
预训练效率翻了一个数量级,RL扩展曲线平滑可预测,多模态和医疗赛道摸到了第一梯队。
但代码和Agent的差距摆在那里,沉思模式还没全面开放,开源时间表也还是一个「希望」。
更现实的压力是,同一周Anthropic发布了据称「太强而不能公开」的Mythos,OpenAI代号Spud的新作也在路上。
143亿买来了一张入场券。接下来的考试,才是真正的。
参考资料:
https://ai.meta.com/blog/introducing-muse-spark-msl/
https://ai.meta.com/blog/scaling-how-we-build-test-advanced-ai/
https://ai.meta.com/static-resource/muse-spark-eval-methodology
https://x.com/alexandr_wang/status/2041909376508985381