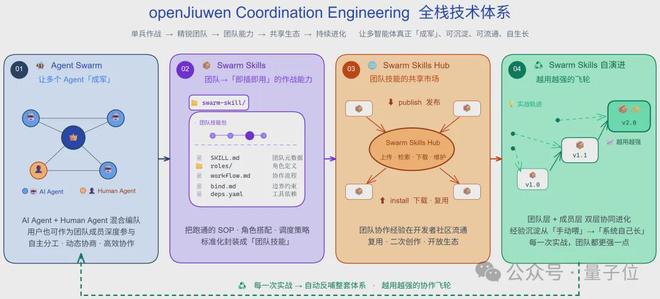
openJiuwen社区开源新招:发布JiuwenSwarm,拉开群体智能序幕
允中 发自 凹非寺量子位 | 公众号 QbitAI刚刚,华为支持的开源AI Agent平台社区openJiuwen发布并开源了蜂群智能体JiuwenSwarm从“一只龙虾”到“一群蜂”。变的不只是名字,而是底层范式。让多个AI智能体像蜂群一样高效协作、自主演进,正式按下“群体智能”的加速键,开启AI时代的“养蜂”序幕。这背后,是openJiuwen提出的下一跳范式主张——Coordination
科技4 阅读
共找到 738 篇相关文章
允中 发自 凹非寺量子位 | 公众号 QbitAI刚刚,华为支持的开源AI Agent平台社区openJiuwen发布并开源了蜂群智能体JiuwenSwarm从“一只龙虾”到“一群蜂”。变的不只是名字,而是底层范式。让多个AI智能体像蜂群一样高效协作、自主演进,正式按下“群体智能”的加速键,开启AI时代的“养蜂”序幕。这背后,是openJiuwen提出的下一跳范式主张——Coordination
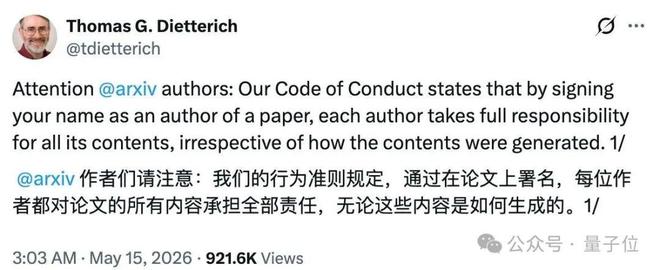
听雨 发自 凹非寺量子位 | 公众号 QbitAI上传AI水论文,被查实者封禁一年后续投稿须先通过同行评审,才有资格重新踏入arXiv。这是arXiv计算机科学版块主席Thomas Dietterich在X上刚刚公开的新规,语气干脆,不带商量。若论文中存在作者未核查LLM生成内容的确凿证据,所有署名作者一并受罚,没有例外。消息一出,陶哲轩也亲自下场评论。这位数学界最活跃的AI拥抱者,专门在Math

30万奖金池,这道汉语方言对话题等你来解丨第十一届信也科技杯全球AI算法大赛 思邈 2026-05-18 13:08:22 量子位

LeCun炮轰Hinton:他认可LLM就是想摆烂退休了! Jay 2026-05-18 13:59:37 量子位 Lecun这次

黄仁勋北京必吃榜我们都尝了!后海酒吧老板:他答应以后每年来一次 Jay 2026-05-18 14:03:53 量子位 老黄严选北

信通院&清华提出FedRE:用「纠缠」搞定联邦学习三难困境 | CVPR 26 听雨 2026-05-18 14:44:04 量子位

8B模型做生物实验:实验步骤顺序不乱、剂量无幻觉|ICLR 2026 听雨 2026-05-18 14:52:11 量子位 超越G

上交x创智x瑞金联合发布CX-Mind:胸片诊断进入“可验证推理”时代 听雨 2026-05-18 14:57:10 量子位 五项


openJiuwen社区开源新招:重磅发布JiuwenSwarm,拉开群体智能“养蜂”序幕 思邈 2026-05-18 18:26:46 量子位

AI水论文封一年,署名连坐!arXiv最严新规来了,陶哲轩附议 听雨 2026-05-18 20:18:30 量子位 生成论文远比

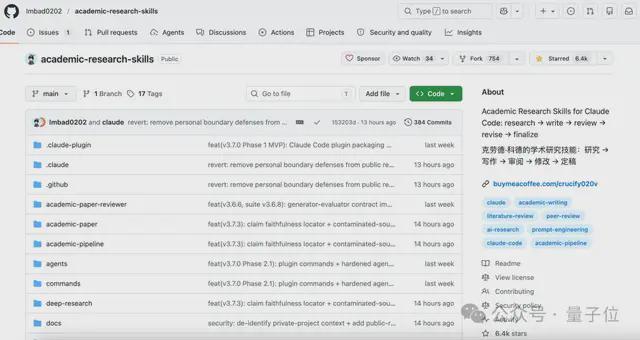
听雨 发自 凹非寺量子位 | 公众号 QbitAI用Claude Code写论文的一整套流水线,有人打包开源出来了。完全戳中了学生党的痛点,github星标直达6.4k。项目名叫academic-research-skills(以下简称ARS),是一套Claude Code技能包。里面涵盖4个skill,分别对应论文的研究、写作、审稿、定稿。只需两行命令安装,直接一条龙串起整套学术研究流水线。只能

PRISM团队 投稿量子位 | 公众号 QbitAISFT之后,直接上强化学习就够了吗?小心,你做的可能不是“训练”,而是“还债”。在多模态大模型(MLLM)的后训练中,行业内长期遵循着一个看似天经地义的范式:先SFT,再RL,两步到位。从DeepSeek到Qwen,从GRPO到DAPO,大家拼命优化RL算法的稳定性、采样效率、奖励设计……却几乎没人回头看一眼:SFT到RL之间,是不是少了点什么?
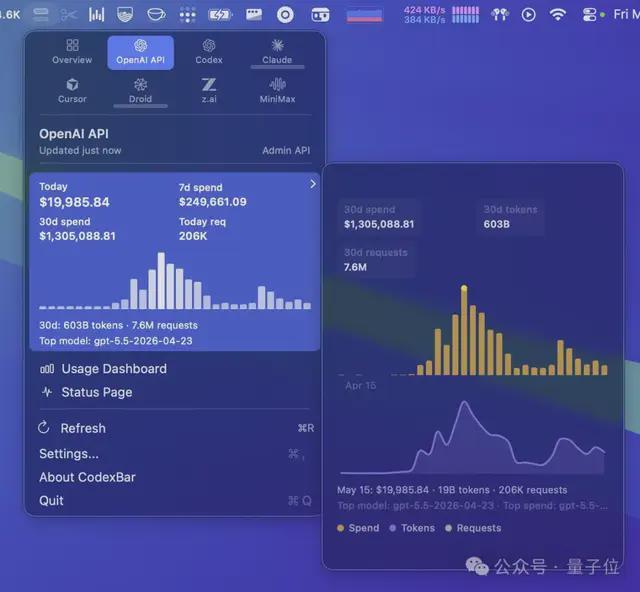
衡宇 发自 凹非寺量子位 | 公众号 QbitAI龙虾之父Peter Steinberger,今天在上晒出了一张自己的CodexBar后台截图。一张相当离谱的截图——上面透露出的信息和数字让我眼睛都瞪大了:过去30天,他调用的OpenAI API总费用达到1305088美元,约合人民币940万元;同时消耗6030亿token,发起760万次请求;最常用的模型是GPT-5.5。以上所有费用,由Ope

组委会 发自 凹非寺量子位 | 公众号 QbitAI进入2026,AI愈发狂飙突进。围观体验之余,人人不免在心中自问:朋友圈刷屏的“龙虾”、Harness等AI新事物,跟我到底有什么关系?真的有必要跟吗?AI创业、AI融资如火如荼,属于我的机会又在哪里?别人已经在用AI做视频、写代码、跑项目,我是不是已经慢了一拍?……到最后,几乎所有问题都会汇成同一个问题:我,到底该如何用AI?如果你对这些问题还

田晏林 发自 凹非寺量子位 | 公众号 QbitAI消费级机器人行业,可能要出现一次真正意义上的代际切换了。过去几年,大家见过太多机器狗:能跑、能跳、能翻跟头。但问题一直没变。它们很多时候其实看不清、听不清,也想不明白。行业主流方案,还是200万像素摄像头、16线激光雷达、单芯片算力架构。机器人能动,但距离真正理解世界,始终差一口气。直到刚才,我看到一组「离谱」数据——6600万像素、HDR140

允中 整理自 凹非寺量子位 | 公众号 QbitAI生成模型的偏好对齐,可能正在进入一个新的阶段。过去几年,大模型post-training最主流的方法是让模型从“成对偏好”中学习。但无论是RLHF还是DPO,都存在同一个问题:反馈必须成对出现。但在真实场景中,反馈大多都是单个样本的标量分数。为此,新加坡国立大学团队提出了一个更为直接的解法:Threshold-Guided Optimizatio

6.4k Stars!用Claude Code写论文的全套流水线,有人打包开源了 衡宇 2026-05-17 11:37:07 量子位

SFT别急着接RL!你的多模态大模型可能一直在“带伤训练” 衡宇 2026-05-17 11:42:11 量子位 先把SFT挖的坑