
全新梅赛德斯-AMG GT纯电跑车首秀:零百2.1秒,搭载豆包大模型
凤凰网科技讯 (作者/许婧)5月20日,梅赛德斯-AMG今日正式发布全新GT高性能纯电四门跑车。该车采用与AMG GT概念车同源的电驱科技,首搭三台轴向磁通电机,支持后驱与四驱两种形式。基于800V高压架构,峰值功率达1169马力,峰值扭矩2000牛·米,零百加速仅2.1秒,最高时速300公里。新车配备主动式空气动力学套件,包含主动可调尾翼,并由一套动态控制系统统筹,提供响应、灵活性和牵引力控制三
科技2 阅读
共找到 400 篇相关文章
凤凰网科技讯 (作者/许婧)5月20日,梅赛德斯-AMG今日正式发布全新GT高性能纯电四门跑车。该车采用与AMG GT概念车同源的电驱科技,首搭三台轴向磁通电机,支持后驱与四驱两种形式。基于800V高压架构,峰值功率达1169马力,峰值扭矩2000牛·米,零百加速仅2.1秒,最高时速300公里。新车配备主动式空气动力学套件,包含主动可调尾翼,并由一套动态控制系统统筹,提供响应、灵活性和牵引力控制三
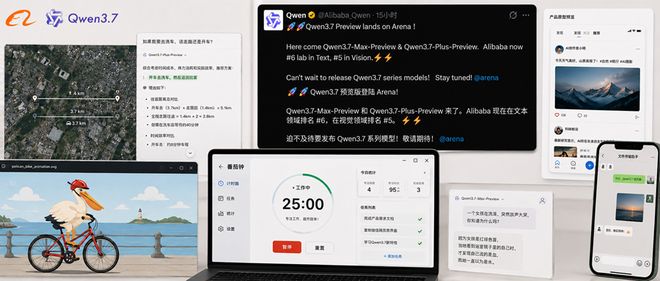
智东西作者 陈骏达编辑 云鹏智东西5月19日报道,今天,阿里的Qwen3.7系列预览版模型已上线,共有Max和Plus两个版本。大模型竞技场也放出了Qwen3.7-Max-Preview的评测结果。在大模型竞技场覆盖主流基座大模型的总榜上,Qwen3.7-Max-Preview排名第13,介于GPT 5.5和Grok 4.2之间,是这一榜单上排名最高的国产模型。在具体的细分榜单上,Qwen

IT之家 5 月 19 日消息,阿里云峰会官宣将于 5 月 20 日举行,千问大模型官网晒出预热海报,表示“重量级新朋友”即将亮相。透露几个关键词:更全能、更强大、有深度、有广度猜猜它是谁?从海报中出现的 Qwen 官方吉祥物水豚(卡皮巴拉)来看,本次峰会预计将公布 Qwen 模型的最新成果,IT之家小伙伴可以期待一下。值得一提的是,最新的 Qwen 3.7-Max-Preview 和 Qwen

文 | 硅基象限当用户不再纠结每月是否要升级流量套餐时,或许要开始纠结每月买多少Token服务了。Token即将像流量、宽带、短信一样,被运营商包装成标准化服务进行售卖。日前,国内三大运营商陆续推出Token套餐产品:面向个人用户推出按月订阅制Token 方案,面向开发者和企业客户提供分层算力套餐,并宣布已将数十至数百种大模型纳入平台,“按月购买、多模型调用、话费支付”。中国电信已推出个人及企业

5月19日消息,据彭博社报道,xAI今年3月曾在内部沟通中向员工开出420美元报酬,希望收集员工的报税文件,帮助Grok改善税务相关能力。报道还称,截至报道发布时,这笔奖金尚未兑现。这件事最刺眼的地方是AI公司开始把数据需求推向了非常私人的区域。报税文件不是普通网页文本。它可能包含收入、家庭成员、资产、投资、抵扣、雇佣关系、身份信息等细节。哪怕公司承诺会做匿名化处理,员工也很难真正判断:这些文件
近年来,Chain-of-Thought(CoT)推理已经成为提升大语言模型和多模态大语言模型复杂问题求解能力的重要技术路径。然而,这种 “显式思考” 也带来了一个越来越突出的效率问题:模型往往需要生成大量的中间推理文本,导致推理 token 数显著增加,从而带来更高的推理延迟、显存占用和计算成本。尤其在多模态大模型(MLLMs)中,输入通常包含图像、问题和复杂上下文,模型为了完成推理,往往需要先

79位跨方向骨干、87%的初代留存率,和一套让年轻人围绕问题自由组队的机制。作者|周悦过去一年,围绕DeepSeek的人才流动消息一直没有停。从早期罗福莉离职,到初代大模型作者王炳宣、多模态骨干阮翀、R1核心作者郭达雅,相继跳槽。核心作者接连被挖,DeepSeek的技术壁垒会不会松动?我们决定换一种方式来看这个问题。我们用Codex和Python,梳理了DeepSeek近两年发布的27篇核心论文和

智东西作者 杨京丽编辑 李水青智东西5月18日消息,最近几天,中国电信、中国移动、中国联通接连推出Token套餐及相关AI服务,面向个人、家庭、开发者、中小微企业等用户销售大模型调用量。这是三大运营商首次正式入局Token生意,而此前相关业务由大模型厂商、互联网大厂和云服务商主导。昨天,中国电信推出系列试商用Token套餐,个人及家庭客户最低9.9元/月可获得1000万Tokens;同日,上海移动

智东西作者 刘煜编辑 陈骏达智东西5月18日报道,5月5日,美国大数据分析和软件公司Palantir交出亮眼财报,其2026年Q1季度营收同比增长85%至16.3亿美元(约合人民币110.7亿元),净利润同比暴涨307%至8.7亿美元(约合人民币59.1亿元),双双创下历史新高。成立于2003年的Palantir,利用大数据、AI等技术,为政府和大型企业提供决策支持。但其高管们却在财报电话会议上,
近期,国产大模型迎来密集更新。从模型性能、应用场景到落地能力全面提升,同时在海外开发者平台,Token调用量超过美国。国产大模型集体更新有哪些亮点?为什么能够吸引全球开发者来体验使用?一起了解能力究竟有多强?记者实测来了近期,国产大模型迎来井喷式更新,且Token调用量排名持续在海外开发者平台OpenRouter上名列前茅。数据显示,截至5月4日至5月10日当周,中国主要大模型周调用量达到7.94

新智元报道【新智元导读】伯克利等发布FST框架:通过快慢分层解决大模型持续学习死局。AI工程师Dan McAteer大胆预言,2026年持续学习(continual learning)即将爆发!通过记忆/上下文快速适应+权重缓慢调整的分层机制,模型保留可塑性避免灾难性遗忘,这一突破远超推理变革1000倍。这是最近的伯克利等机构的AI实验给他的勇气。他们让同一个大语言模型连续学三个任务:先学需要多跳

新智元报道【新智元导读】就在刚刚,被Anthropic视为「太危险」的绝密大模型Mythos,竟在谷歌云悄悄解禁。CMU最新实测爆出,它在真实漏洞攻防中,断层碾压GPT-5.5。全球最强AI猛兽,要出笼了!今天,AI大佬意外发现Claude Mythos惊现Google Cloud Console ,就连「预览」标签彻底消失了。Anthropic那个「太危险、不敢解禁」的模型突然现身,一时间,全网

PRISM团队 投稿量子位 | 公众号 QbitAISFT之后,直接上强化学习就够了吗?小心,你做的可能不是“训练”,而是“还债”。在多模态大模型(MLLM)的后训练中,行业内长期遵循着一个看似天经地义的范式:先SFT,再RL,两步到位。从DeepSeek到Qwen,从GRPO到DAPO,大家拼命优化RL算法的稳定性、采样效率、奖励设计……却几乎没人回头看一眼:SFT到RL之间,是不是少了点什么?

允中 整理自 凹非寺量子位 | 公众号 QbitAI生成模型的偏好对齐,可能正在进入一个新的阶段。过去几年,大模型post-training最主流的方法是让模型从“成对偏好”中学习。但无论是RLHF还是DPO,都存在同一个问题:反馈必须成对出现。但在真实场景中,反馈大多都是单个样本的标量分数。为此,新加坡国立大学团队提出了一个更为直接的解法:Threshold-Guided Optimizatio

SFT别急着接RL!你的多模态大模型可能一直在“带伤训练” 衡宇 2026-05-17 11:42:11 量子位 先把SFT挖的坑

IT之家 5 月 16 日消息,蚂蚁集团旗下百灵大模型昨日宣布,正式开源 Ring-2.6-1T,将这款面向真实复杂任务场景打造的万亿级旗舰思考模型开放给开发者、研究者与企业场景进行验证、适配和二次开发。据介绍,Ring-2.6-1T 引入了可调节 Reasoning Effort 机制,支持 high 与 xhigh 两种推理强度,开发者可以根据任务复杂度灵活控制模型思考深度,在效果、速度与成本

作者|林易豆包准备开始收费了。这个消息可以说是最近国内AI圈的一大热点话题。根据豆包在App Store页面发布三档订阅价格来看,标准版连续包月68元,加强版200元,专业版500元;连续包年分别为688元、2048元和5088元。很多网友在看到这条消息之后,不乏有阴阳之声,称“说好永远免费,看来是撑不住了”。不过,这件事还不能简单理解成豆包正式全面收费。因为豆包方面已经明确回应,豆包始终提供免费

昨天,全新理想L9 Livis发布会开完之后,如果只盯着新车参数看,很容易把它理解成一场旗舰SUV的常规升级:更强的算力、更先进的底盘、更聪明的智驾、更豪华的家庭空间。但这是理想要表达的核心吗?过去几年,科技行业最热闹的地方在大模型。人们讨论Chatbot,讨论Agent,讨论AI会不会写代码、做PPT、生成视频,讨论机器人什么时候能进工厂、进家庭。可所有这些讨论最后都会落到一个问题上:AI如果只

金磊 发自 杭州量子位 | 公众号 QbitAI很反差。明明是一场AI的发布会,台下却坐满了医学界的大佬们:有北大、清华的,有浙江、上海的,甚至医学顶刊BMJ集团的主编都来围观了……为啥会这样?因为阿里健康正式发布了一个新的医学AI产品——氢离子,主打的就是靠谱的医学AI助手。或许你还会有疑问,现在通用大模型、医疗AI不是蛮多的么,阿里健康干嘛还要再另起炉灶啊?好问题。阿里健康CTO王祥志在现场举

新智元报道【新智元导读】OpenAI刚把ChatGPT接入了银行账户。目前该功能以预览版形式面向美国ChatGPT Pro用户开放,可以通过Plaid连上12000家金融机构的账户,获得消费分析和理财规划辅助。从此,聊天框旁边,多了一个能帮你看每月账户流水的大模型。OpenAI开始让ChatGPT读你的银行账户数据了。刚刚,OpenAI推出了ChatGPT个人理财功能预览版。用户授权后,可通过Pl