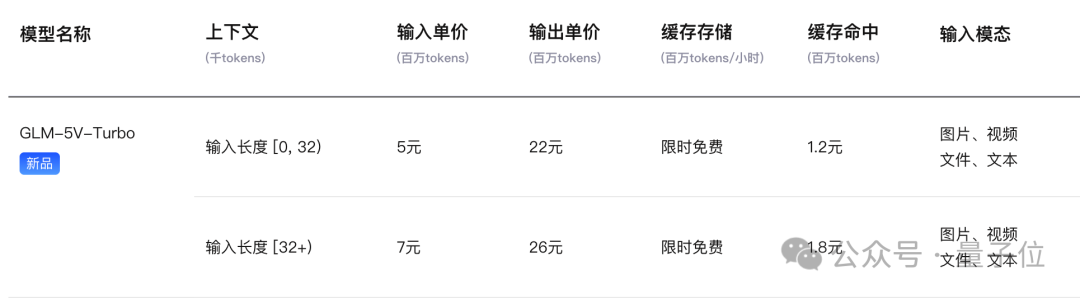
近日,GLM-5V-Turbo正式上线,这是一款基于视觉的编程工具。
 听雨
听雨它采用了一种全新的“Vision Coding”技术,能够根据草图自动生成前端代码。
听雨 发自 凹非寺
国内团队推出的大模型GLM-5V-Turbo,在视觉编程领域有着独特的优势。
该系统不仅继承了之前Qwen3.5-Omni的优秀特性,还加入了多项创新功能。
用户只需提供一个网页链接或草图设计稿,它就能快速生成前端代码并实现页面互动逻辑。
对于产品经理来说,这款工具大大降低了开发门槛,可以轻松制作原型产品,并与开发者讨论细节。
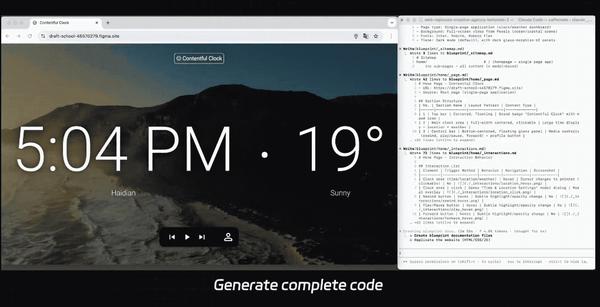
有人提议将“Vibe Coding”更名为“Vision Coding”,以更准确地描述其功能特点。
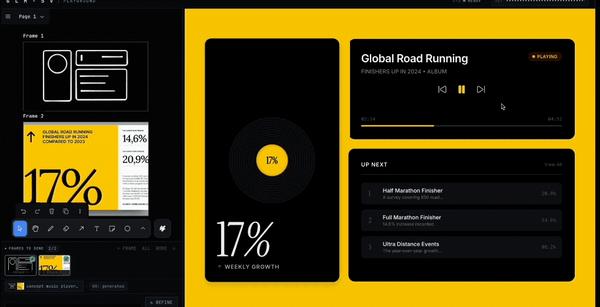
此外,GLM-5V-Turbo还具有强大的图表分析能力,能够解析复杂的金融数据图示。
结合AutoClaw的股票分析师工具包,它能生成详细的报告并解读各种财务报表和市场趋势图形。
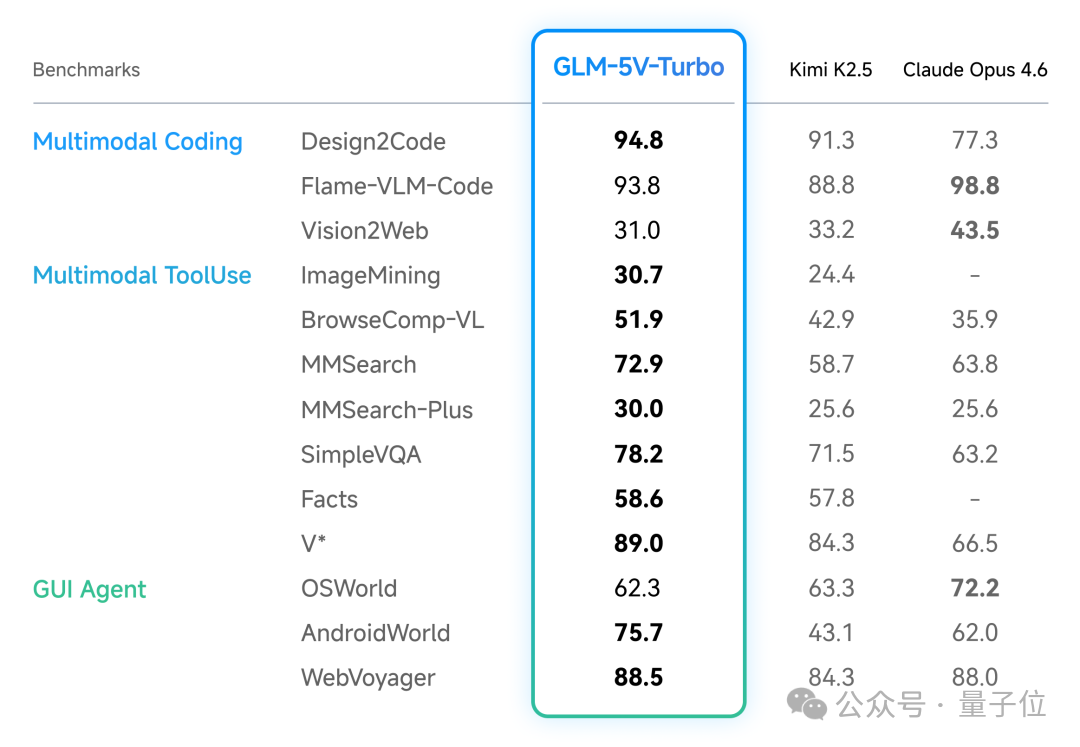
在性能方面,GLM-5V-Turbo在多项基准测试中都超越了Claude Opus 4.6,显示出了卓越的能力。
它能够完美还原设计稿、快速生成视觉代码,并具备出色的多模态检索和问答功能。
在实际操作环境中,GLM-5V-Turbo也表现出色,在AndroidWorld等基准测试中名列前茅。
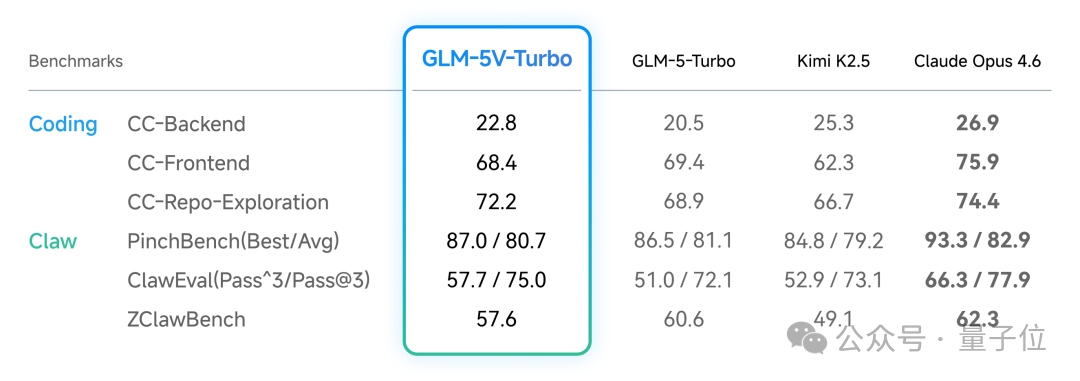
GLM-5V-Turbo同样在纯文本编程方面表现稳定,保持了与视觉能力相匹配的水平。
更重要的是,这款产品的价格也非常实惠。
一位网友评论说:“Claude Code的时代已经过去。”
接下来我们通过实际案例来展示GLM-5V-Turbo的强大功能。
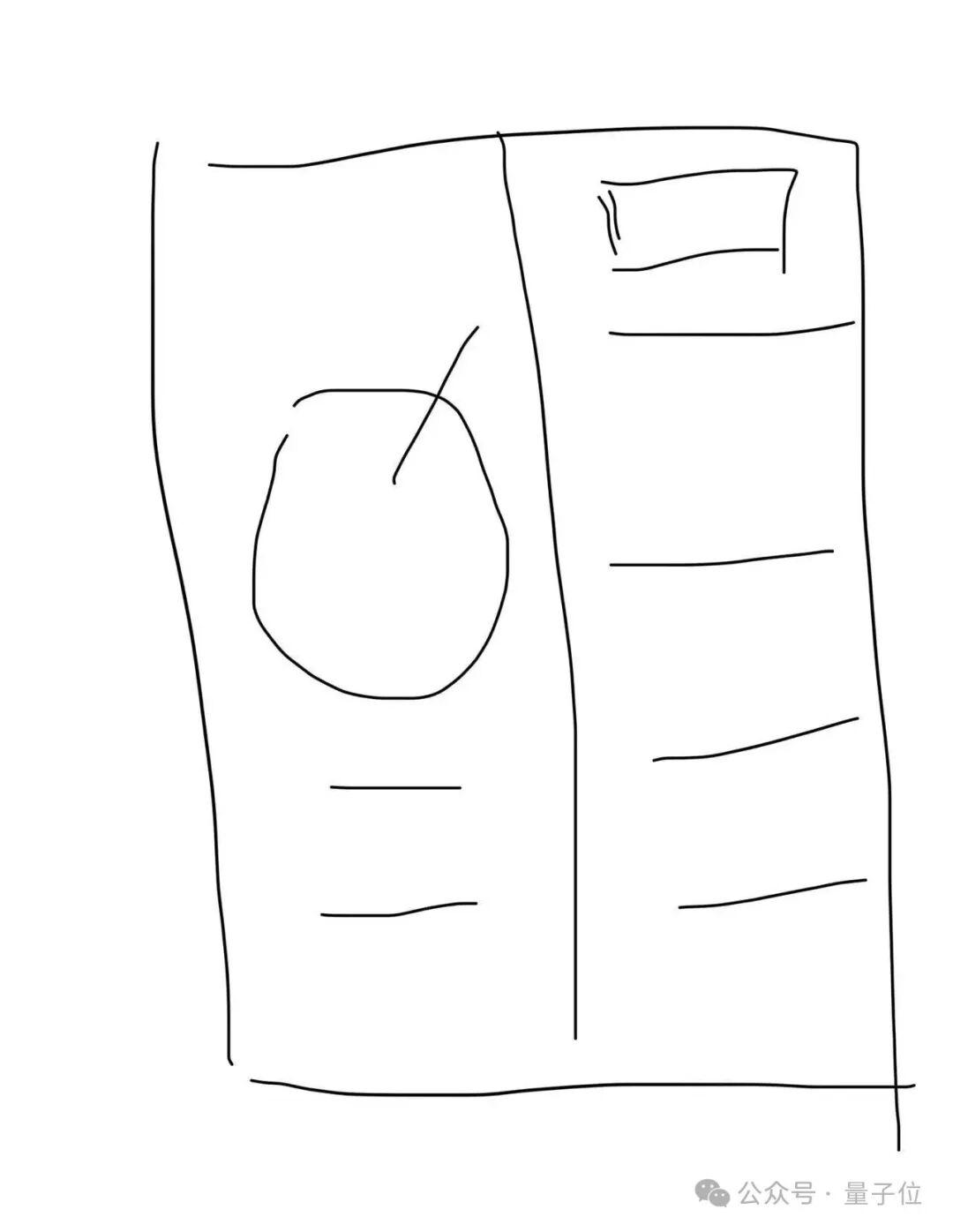
首先测试它的视觉编程能力:根据一张草图创建音乐播放器界面。

一张草图画出前端
草图非常简单,但加上提示词后,它迅速生成了所需的HTML和CSS代码。
在与模型互动的过程中,可以根据需要不断调整和完善设计。
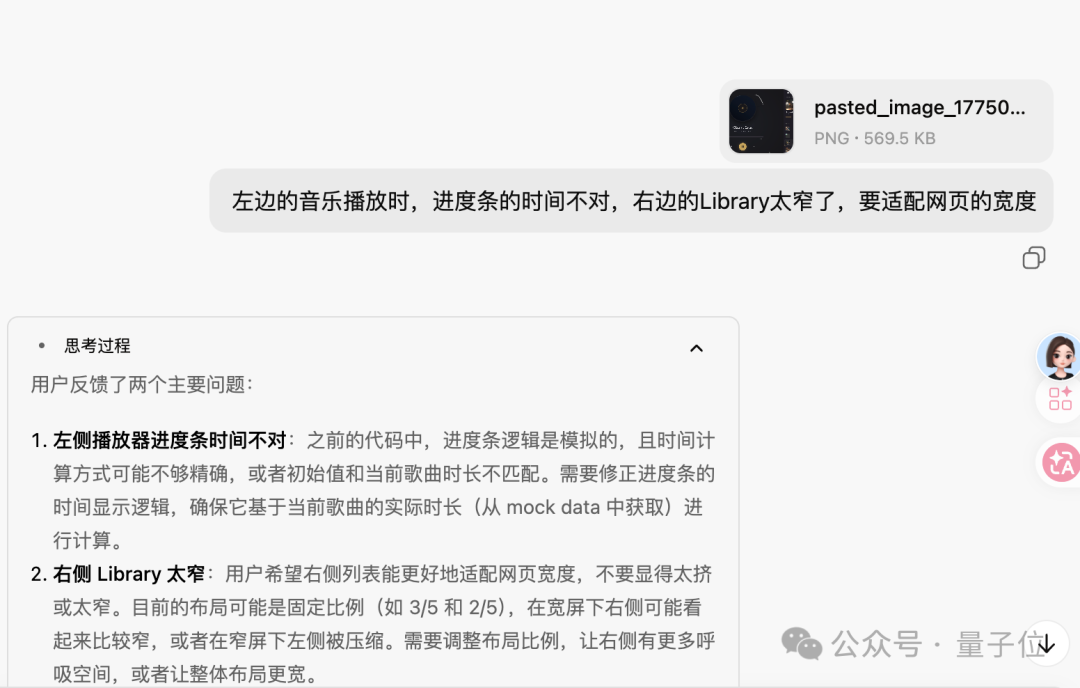
最终成果是一个符合要求的前端页面,不仅包含了音乐播放器,还有推荐歌曲列表及播放列表。
点击不同的曲目时,左侧界面会自动更新显示相应信息,交互体验良好。

这一特性对外行用户尤其友好,帮助他们快速理解学术文献的核心观点和图表意义。
更进一步的应用场景是制作演示文稿或项目汇报材料。
澳龙(AutoClaw)平台现提供“股票分析师”技能包,专为GLM-5V-Turbo设计。
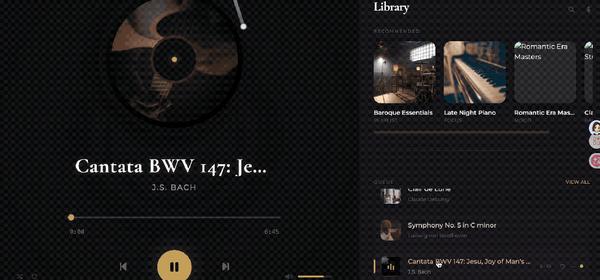
用户可以上传各种财经图表,由它生成详细的分析报告和操作建议。
GLM-5V-Turbo的技术架构在多个层面进行了优化:从原生多模态融合到30+任务协同强化学习。
其中CogViT视觉编码器在物体识别、细节理解及空间关系处理方面表现出色。
MTP结构的引入进一步提高了整体推理效率,使得模型更加全面且稳定。
为了提升代理能力,研发团队创建了一个从“看懂元素”到“预测连续动作”的训练体系,并大规模生成了可控和可验证的数据集。
同时还采用了一种逆向策略,即通过多模态任务来增强模型的实际操作技能。

在工具链方面,GLM-5V-Turbo也进行了重大升级,从文本扩展到了多媒体层面的操作。
这使得它能够形成完整的闭环流程:理解环境 -> 规划行动 -> 执行指令。
目前,该模型已在Z.ai和AutoClaw上提供服务,并支持API接口调用,有兴趣的朋友不妨亲自体验一下。
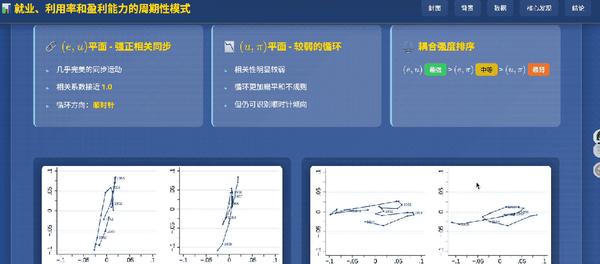
这对于外行来说太友好了,扫一眼就能大概看懂这篇研究在做什么,每个图表对应的含义是怎样的。
转念一想,这其实也相当于另一个形式的ppt?学生党做论文pre都可以直接拿来用了。
给龙虾安上“眼睛”
智谱这次还特别拓展了龙虾的任务边界,给自家澳龙安上了“眼睛”。
在AutoClaw中选择GLM-5V-Turbo模型,你就可以让它浏览网页和文档,做报告和PPT,还可以解读复杂图表。
澳龙已经上线了“股票分析师”skill,完美适配GLM-5V-Turbo解读复杂图表的能力。
我在飞书上给它截图了一张英伟达股票图,让它帮我分析一下。
没过多久,它就给我生成了一份图文并茂的分析报告:
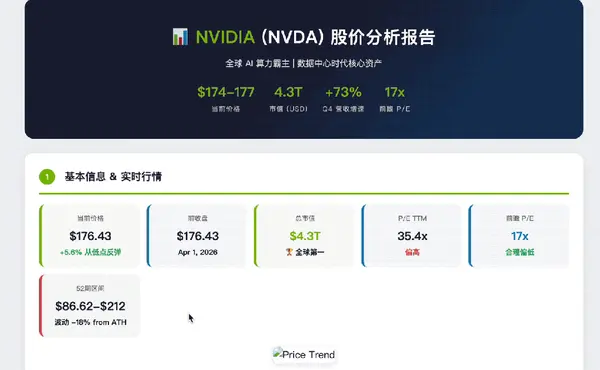
整体内容还是挺详细的,还给出了基本面分析和操作建议,简单作为一个参考是足够了的。
这么强,咋做到的?
据官方介绍,GLM-5V-Turbo在模型架构、训练方法、数据构造、工具链四个层面都做了升级:
第一,原生多模态融合。
GLM-5V-Turbo从预训练阶段就把文本和图像能力一起训练,后面再通过进一步优化,让两者配合更默契。
同时,他们做了一个新的视觉编码器(CogViT),在识别物体、理解细节、空间关系这些能力上都更强。
再加上一个更适合多模态推理的结构(MTP),整体推理效率也更高。
第二,30+ 任务协同强化学习。
在强化学习阶段,模型同时训练了30多个任务,覆盖STEM推理、图像定位(grounding)、视频理解、GUI操作等多个方向。
这样带来的好处是:模型不只是某一项能力强,而是感知、推理、执行整体更均衡,也更稳定,避免了只在单一领域“偏科”。
第三,专门为Agent能力设计数据。
Agent最大的难点是:数据少、而且很难验证对不对。
智谱的做法是:
- 搭了一套从“看懂元素”到“预测一连串动作”的训练体系;
- 用合成环境大规模生成可控、可验证的数据;
- 甚至在预训练阶段就提前加入Agent相关能力(比如GUI操作数据),减少模型幻觉。
另外,还用了类似“以评估反推能力”的方法,用多模态任务去倒逼模型变得更像一个能干活的Agent。
第四,把工具链从“纯文本”升级到“能看能操作”。
除了原有的文本工具,GLM-5V-Turbo新增支持多模态搜索、画框、截图、读网页等多模态tools。
这意味着模型能真正做到一整套闭环:看懂环境 → 规划步骤 → 动手执行。
而且它和Claude Code、AutoClaw这些工具的配合也更好了,整体更接近一个能实际完成任务的智能体。
目前,新模型在Z.ai和AutoClaw上都可以体验,也支持API调用,感兴趣的朋友快去试试吧~
体验地址:
AutoClaw(澳龙):https://autoglm.zhipuai.cn/autoclaw/
Z.ai:https://chat.z.ai
API接入:https://docs.bigmodel.cn/cn/guide/models/vlm/glm-5v-turbo