最新的生图模型Wan2.7-Image现已推出,它是国内最强大的图像生成工具。
 量子位的朋友们
量子位的朋友们这款新模型具备全方位的链路能力,包括文字转图片、多图合成以及各种编辑功能。
在一项人类偏好盲测中,“文生图”这一特性超越了GPT-Image1.5和许多国内主流的同类产品,在文本渲染、照片级图像质量和世界知识理解方面接近Nano Banana Pro的标准。

该模型支持多种链路能力,包括文字转图片、多图合成以及图像指令编辑等。
在一次盲测中,“文生图”的性能优于GPT-Image1.5和国内其他主要竞争对手,在文本渲染、照片级成像质量和世界知识方面接近Nano Banana Pro的表现。
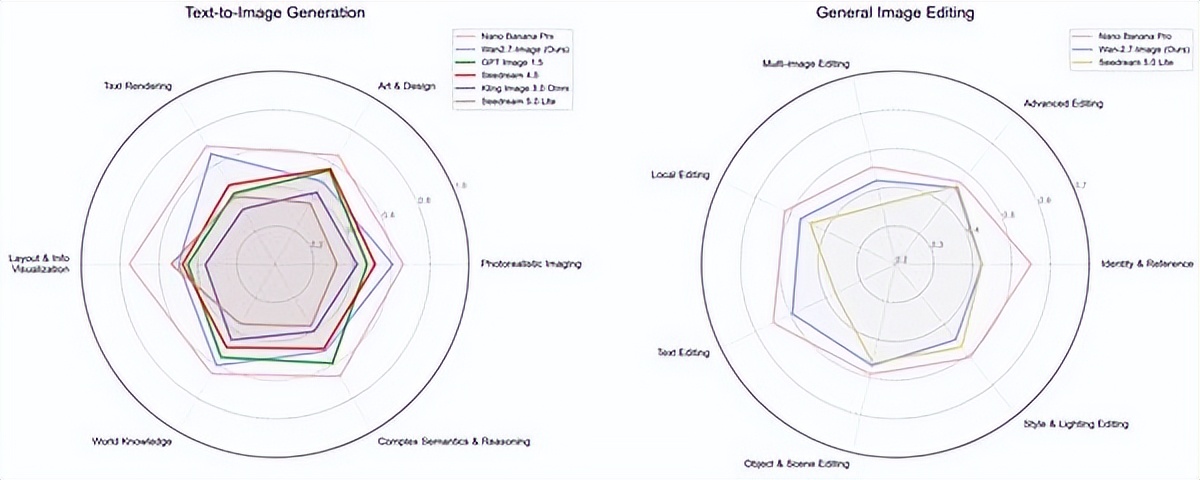
最新的人类偏好盲测评分显示,Wan2.7-Image在国内同类产品中位列第一。
为了摆脱单一的AI面孔,Wan2.7-Image增强了虚拟形象定制功能,使用户能够从骨骼结构到面部细节进行全面调整,例如改变提示词中的脸型(鹅蛋脸、圆脸等)。

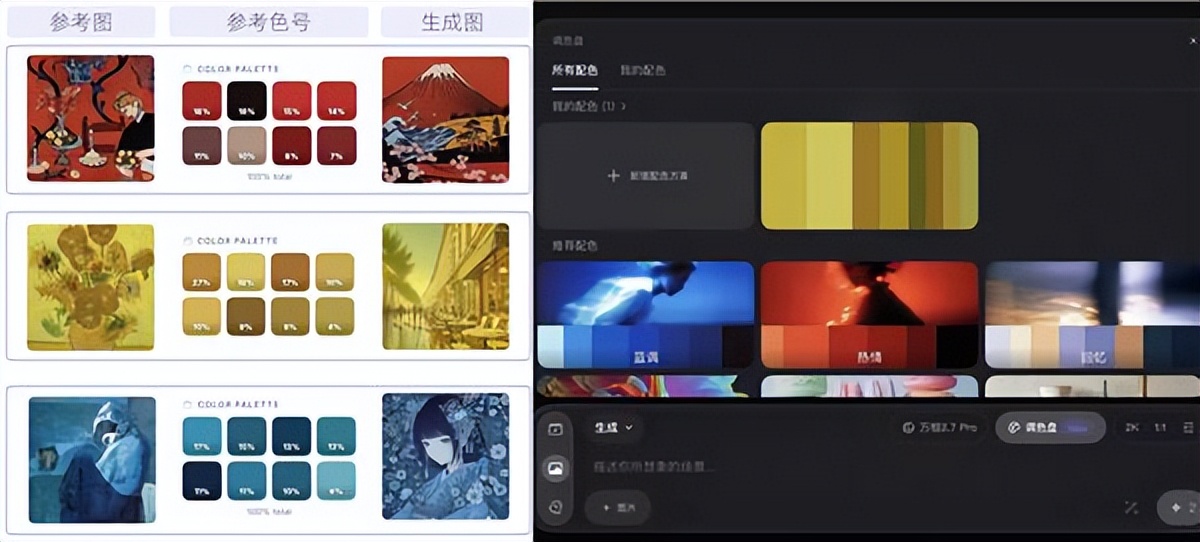
艺术家和设计师需要精确控制颜色搭配,商业海报更是如此。然而,传统的AI生图工具往往不能满足这些需求。Wan2.7-Image引入了“调色盘”功能,用户可以使用Hex Code从参考图片中提取颜色比例,并生成同系列的图像。
长文本渲染是AI生图的一个挑战点,容易出现文字模糊或缺失的情况。通过采用长上下文文本编码技术(Long Context Text Encoder),Wan2.7-Image能够清晰呈现超长序列,包括复杂的表格和公式,支持多达3K tokens的输入量。

此外,该模型还拥有强大的组图生成能力,一次最多可以创建十二张同风格系列图、PPT配图等。
编辑功能增强了创作者对作品的控制力。Wan2.7-Image原生支持交互式编辑模块,“哪里不满意点哪里”,允许用户在指定区域添加或移动元素,实现像素级意图匹配。

对于多主体一致性需求,这款模型可以同时输入九张图片作为参考源,保持风格和特征的一致性。此外,还提供了几十种实用的图像处理功能,如镜头视角调整、光影效果处理等。

除了生成高质量的图像,Wan2.7-Image在理解图象方面也表现出色,这得益于其架构和技术的进步。
在训练数据集上,模型使用了大规模异构的数据底座,并整合了大量的理解类数据。通过引入多模态指令(例如文字和图片结合),使得该模型从简单的“像素拟合”提升到了更深层次的语义认知能力。
基于图像布局、文字描述等多个维度,团队构建了细致标注体系,配合先进的训练策略,使Wan2.7-Image在多种场景下保持稳定的生成效果。与此同时,更大规模数据及尺寸训练而成的高级版Wan2.7-Image-Pro也已上线。
该模型广泛适用于影视制作、自媒体内容创作、电商营销以及教育科研等多个领域,能够低成本地完成角色设定和特效预览等工作,并且支持龙虾画画等特色功能。
用户现在可以在阿里云网站、wan.video平台以及即将更新的千问App上体验Wan2.7-Image的强大能力。