最近一款APP让热门视频的制作变得轻而易举。
它不仅能定制人脸特征、调控色彩和布局,还能跨模态操作并展现出强烈的创意感与真实度。
这款全能创作助手名为Wan2.7,是阿里新推出的千问APP的一部分,使用体验极为顺畅。
例如通过提示词生成的视频中,一位男士惊讶地看向镜头,随着视角拉远,一群人都表现出同样的震惊表情。最终揭示他们看到的是Wan2.7广告牌的画面。
不卖关子了——
视频中的角色表情生动自然,场景转换流畅,完全符合创作需求,尤其是在群体表现力上做到了“千人千面”的效果。
此外,系统还能自动生成匹配的人声背景音乐,使成品视频更加引人入胜。
接下来尝试更复杂的任务——从一张图片生成一段视频。给定的图片是一张场景图,提示词为:“根据这张图片和音频生成萨克斯表演。”
 画面中光影变化,一位演奏者即刻呈现了一场精彩的单人萨克斯演出。
画面中光影变化,一位演奏者即刻呈现了一场精彩的单人萨克斯演出。
在此基础上,还可以进一步添加元素,比如在原有视频的基础上补充一张尾帧图,让女性演奏家加入表演。
所有这些操作都可以直接在千问APP上完成,步骤简单明了。
不仅视频生成能力得到了显著提升,图片编辑功能也达到了新的水平。从8色HEX精准控制到3K tokens超长文本支持,使用起来都十分便捷。

以及一段音频:
 接下来详细体验这款应用的具体创作流程。
接下来详细体验这款应用的具体创作流程。
这次Wan2.7-Image的亮点在于“千人千面”的功能,用户可以自由定制人物的脸部细节,包括骨骼结构、眼神以及皮肤纹理等。
该应用生成的人物形象细致入微,连毛孔和皱纹都清晰可见,逼真程度堪比真人定妆照。
 同样地,我们尝试用Gemini和ChatGPT来完成同样的任务。结果显示,Gemini的输出更接近电影版角色选角,而ChatGPT在鹰钩鼻塑造上稍逊一筹,但仍优于电视剧版本的表现。(doge)
同样地,我们尝试用Gemini和ChatGPT来完成同样的任务。结果显示,Gemini的输出更接近电影版角色选角,而ChatGPT在鹰钩鼻塑造上稍逊一筹,但仍优于电视剧版本的表现。(doge)
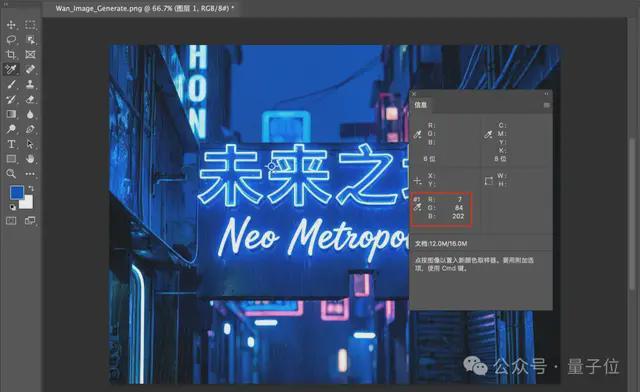
此外,Wan2.7-Image还能进行调色处理,例如为一张赛博朋克风格的夜景照片设定主色调为蓝色RGB(0, 70, 255)。画面聚焦在发光霓虹招牌上,上面用汉字写着“未来之城”,下方则是手写英文“Neo Metropolis”。
将图片导入PS软件后可见,色系精准且色彩差异控制得当。中英文字体渲染没有出现乱码问题,并支持长达3K tokens的超长文本输入,相当于整页A4纸的文字量。

效果是酱紫的:
 这次Wan2.7在视频生成能力上也有新的突破。
这次Wan2.7在视频生成能力上也有新的突破。
例如可以利用千问APP制作一个巴西旅游Vlog。

根据六宫格参考图生成的巴西旅行片段,完美呈现了异国风情。
如果对现有视频不满意,还可以进行局部编辑。比如将胶片替换为盘子等操作,只需上传参考图片并输入提示词即可实现。
更进一步,可以利用千问APP中的动作模仿功能来学习新动作。
比如借鉴一段视频中人物的手势,并将其应用到另一角色身上。
最后尝试一个有趣的应用——制作好莱坞大片场景!
通过续写视频延长战斗场面,让故事更加引人入胜。
总之,Wan2.7的实用性与便捷性让人印象深刻。不仅提升了创作乐趣,还大幅降低了使用门槛。
先看图像生成。
它适用于日常创意表达以及专业平面设计和影视制作等多个领域,比如最近流行的AI演员及短剧制作。
无论从哪个角度看,这款工具的表现都不输于专业的演员或设计师。
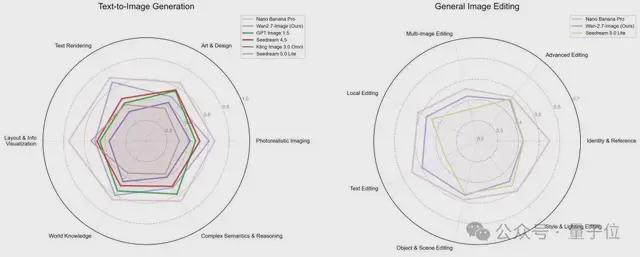
在一项人类偏好盲测中,Wan2.7-Image模型在国内生成模型排行榜上名列前茅,超越了GPT Image 1.5,并逼近Nano Banana Pro。

它的推出不仅代表阿里在技术上的突破,更标志着AI内容创作工具在中国市场的广泛应用即将成为现实。
当我们放眼整个行业时会发现,随着硅谷方面如Sora等早期生成模型逐渐退场,以OpenAI为首的科技巨头也在调整战略重点转向Agent和底层推理等领域。
 相比之下,中国市场则不断涌现多款高性能且功能全面的视频/图像生成模型。
相比之下,中国市场则不断涌现多款高性能且功能全面的视频/图像生成模型。
其中一个重要原因是国内拥有更为完善的C端场景(如短视频、电商),更适合AI内容生成技术的实际应用落地。
另一方面,中国厂商更加注重培养模型在实际工程中的应用能力,并以更快的速度和更低的成本推动AI融入创作者的工作流程。
如何更有效地实现从AI到创作的无缝对接?阿里给出的答案是直接将最强劲的技术装入APP中,让所有用户都能轻松使用。

这一策略的背后是对市场精准洞察的结果:技术领先只是大模型进入市场的门票,真正的护城河在于如何让更多人受益于先进技术。
以千问APP为例,无论是春节期间推出“千问办事”的能力还是近期将Wan2.7下放到移动端,都是为了尽快让大众体验到最新科技成果。
用户一旦开始使用这款工具,便会发现AI创作其实并不复杂。即使对模型一无所知也能通过简单的操作和指令稳定生成高质量的视频或图像作品。
可以预见,在不久将来,制作爆款视频和精美图像将变得像点外卖、刷短视频一样简单易行,这将是人人参与AI创作时代真正到来的重要标志。
根据六宫格参考图生成一个巴西旅游Vlog。

好好好!也是在地球另一端感受到了桑巴热情。

视频链接:https://mp.weixin.qq.com/s/hc0gyu23DeSn1EknMfhyHA
要是对视频细节不满意,还可以进行局部编辑,比如原视频是这样的:

视频链接:https://mp.weixin.qq.com/s/hc0gyu23DeSn1EknMfhyHA
只需输入提示词+上传参考图,就能将胶片一键替换成盘子。
将视频中的胶片替换为图片中的盘子。

视频链接:https://mp.weixin.qq.com/s/hc0gyu23DeSn1EknMfhyHA
且看盘子上的反光,细节好评!
修改静态主体还不够,我还能直接用千问APP的视频模仿功能,无痛学习新动作~
比如我觉得这个小哥的动作很丰富:

视频链接:https://mp.weixin.qq.com/s/hc0gyu23DeSn1EknMfhyHA
尝试套到另一个角色身上:
让图片中的人物模仿视频中的人的手势动作,保持双手配合和手势变化过程清晰可见。

视频链接:https://mp.weixin.qq.com/s/hc0gyu23DeSn1EknMfhyHA
最后来玩个有意思的:拍好莱坞大片!

视频链接:https://mp.weixin.qq.com/s/hc0gyu23DeSn1EknMfhyHA
看不够,那就用视频续写延长战斗:

视频链接:https://mp.weixin.qq.com/s/hc0gyu23DeSn1EknMfhyHA
(无奖竞猜:男人为何如此惊恐?)
总之实测下来,Wan2.7给我最大的感受是——妙!
不仅仅可玩性大大提升,而且用起来还特别方便。
以前要创作一个视频,需要经过反复多次的修改剪辑,现在千问APP里就能一站式续写和参考重塑,迅速提炼出爆款视频的流量密码。
而且不只是日常的创意表达,专业的平面设计或者影视制作也能大用特用,就比如最近大热的AI演员、AI短剧,Wan2.7就能分得一杯羹。
而且演技还不输专业演员,够真实、够好用。
口说无凭,例如在人类偏好盲测评分中,Wan2.7-Image就位列国内生成模型第一,超过GPT Image 1.5,逼近Nano Banana Pro。
实力能打+人人可用,那么这里就引出一个核心问题——
Wan2.7的发布,究竟代表着什么?
触手可及的创作,让人人都能生产爆款
显然,这并非一句“千问团队实现技术突破”就能简单带过的。
当我们将目光放大至整个行业,就会发现一个愈加明显的趋势清晰可见:
AI内容生成正在加速进入中国时间。
先看硅谷这边,曾经的AI生成龙头Sora悄然退场,以OpenAI为首的科技巨头纷纷从全面开花,转向Agent和底层推理的战略性单点收缩。
而例如视频生成这类高投入、慢回报的支线任务则被率先抛弃。
但与之形成对比的,是国内市场陆续迸发出多款高性能且全面的视频/图像生成模型。
归根结底,一方面是因为国内拥有更完善的C端场景(如短视频、电商),更适配AI内容生成的商业化落地。
另一方面,中国厂商也更注重培养模型的工程应用能力,尝试以更行之有效的迭代速度和更低的成本,加快AI融入创作者的工作流。
那么如何更高效地打通AI到创作者的“最后一公里”呢?
依据多年深厚的用户场景积累,阿里的答案简单粗暴——直给。也就是直接将最强模型同步装进APP。

这源于阿里对市场的精准洞察:技术领先只是大模型的入场券,技术普惠才是产品真正的护城河。
细数阿里千问最近的动作,无一不在印证这点——春节期间“千问办事”的能力出圈,现在又将Wan2.7下放到移动端,就是为了让更多人能够第一时间享受到技术红利。
只要用户开始用了,就会发现AI创作这件事原来没有想象中那么难,即使是对模型一窍不通,也能通过最基础的功能按键和一句指令,稳定创造出高水准的视频。
可以预见的是,未来制作爆款视频和精美图像就会变得像点外卖、刷视频一样简单,到那一刻,才是真正打开了人人AI创作的大门。