SentiPulse与中国人民大学高瓴人工智能学院合作推出开源的SentiAvatar交互式3D数字人框架,引领行业发展潮流。
 量子位的朋友们
量子位的朋友们当前,3D数字人物行业面临着发展瓶颈,竞争焦点集中在如何使数字人物看起来更像真人。然而,尽管建模和渲染技术日益精进,却未能解决用户深度互动的核心需求问题。
实际上,阻碍数字人产业发展的关键因素并非其外表不够逼真,而是它缺乏与人类相似的自然表达能力和流畅的动作表现能力。在很多情况下,虽然数字人物能发出声音并做出动作,但这些行为往往与其所说的话不匹配,这不仅破坏了交互体验的真实感和连贯性,也阻碍了人与虚拟角色之间情感联结的建立。
在真实的面对面交流中,超过70%的信息是通过非语言信号传递出来的。遗憾的是,目前数字人物行业面临三大挑战:缺乏高质量的多模态数据集、复杂的语义表达下动作同步困难以及音视频节奏不一致的问题。
这些障碍限制了数字人从“只会说话和动”向真正能进行自然互动的发展进程。而SentiPulse与中国人民大学高瓴人工智能学院合作开发的交互式3D数字人物框架正是为了克服这些挑战应运而生,旨在使数字人物能够实现更流畅、更具情境感的动作表现。
首个面向全球开源的交互式3D数字人框架打破了传统动作生成的局限性
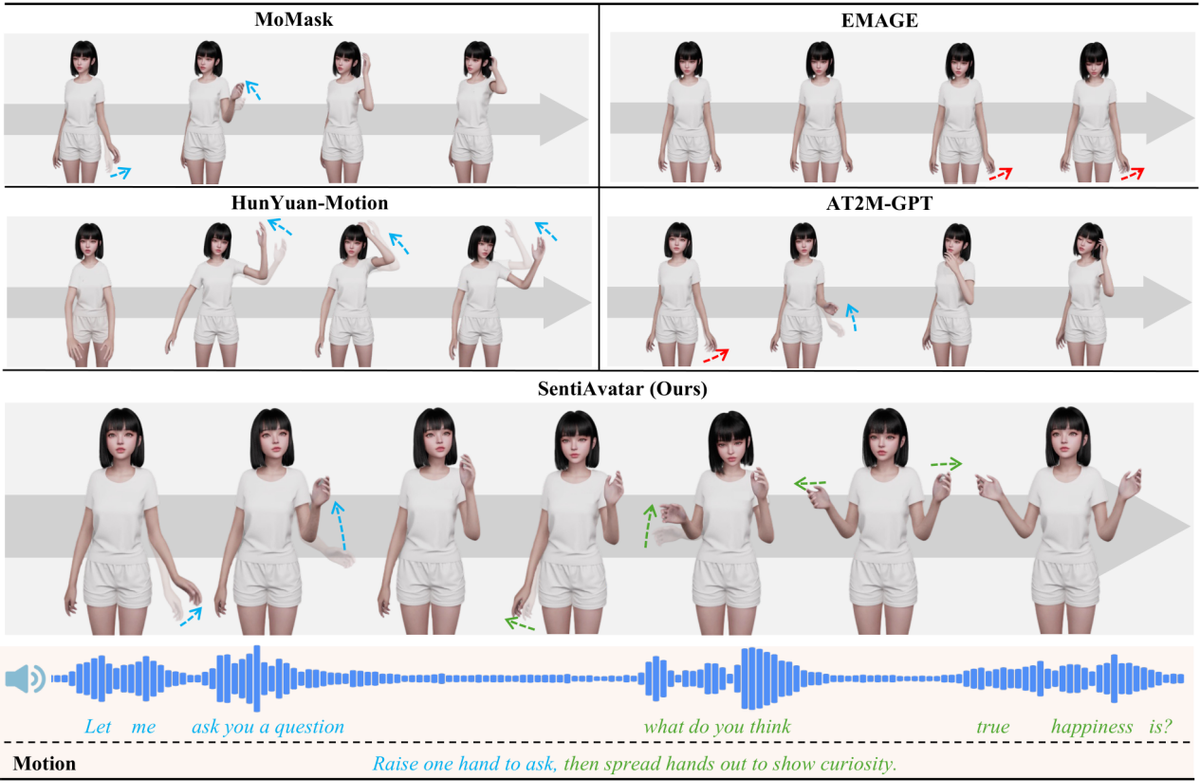
为了解决行业痛点,SentiAvatar开创了一套全新的3D动作生成模式。

在数据基础层面上,SuSuInterActs数据集围绕一个名为SUSU的角色展开(该角色设定为22岁、性格温柔活泼且情感丰富)。包含超过37小时的多模态对话记录和2.1万个片段,涵盖了同步语音、行为标记文本及全身动作与面部表情信息,填补了中文高质量数据领域的空白。
为了克服场景限制并使数字人物互动摆脱“脚本化”的束缚,开发团队在预训练阶段引入了一种创新性的自研基础模型——Motion Foundation Model,在超过20万条异质动作序列(约676小时)上进行泛用运动先验的训练。
此外,SentiAvatar还提出了一个计划-填充双通道并行架构,在生成动作时将身体动作和面部表情分开处理:首先规划“做什么”,然后插入“如何执行”的具体步骤,从而提高整体动作生成效果的自然度与流畅性。
具体而言,在第一阶段中,LLM语义规划器接收行为标签文本及稀疏音频Token,并输出一系列稀疏关键帧动作Token。为支持连续多轮生成,模型以前一句最后两个关键帧音-动Token对作为上下文前缀,从下一个关键帧位置开始续写;在第二阶段里,Body Infill Transformer则负责填充相邻关键帧之间的中间3帧,利用逐帧的HuBERT连续特征(768维,20FPS)为条件信号。
在SuSuInterActs和行业通用BEATv2两个数据集上进行的实验表明,SentiAvatar在多项核心指标上超越了当前国际最优水平,并且显著提升了跨场景及语言的应用能力。
通过对自建测试集SuSuInterActs以及跨域、多语言环境下的BEATv2评测集进行评估,SentiAvatar不仅在文本-动作检索召回率R@1方面达到了43.64%,比行业次优基准高出近一倍;还在FGD和BC两项指标上刷新了纪录。
利用自建高质量数据集、基础模型与核心架构的优势,SentiAvatar能够在0.3秒内生成长达六秒钟的动作序列,并支持无限轮的流式交互。这意味着数字人物可以在实时对话中持续产生连贯动作和表情变化,从而避免了传统批量处理方式带来的“卡顿”问题。
构建一个认知与表达相结合的闭环系统,为下一代数字人的交互体验奠定坚实基础
SentiAvatar已正式在GitHub上开源,并向全球科研机构及开发者开放访问权限。相关技术文档也已在arXiv网站同步发布。利用这套开源框架,开发人员可以低成本创建专属的3D数字人物形象或扩展其应用范围至游戏交互、影视制作等领域。
当数字人不再只是冷冰冰的互动工具时,它将能够识别并回应用户的非语言信号,并提供相应的情感反馈,成为一个能感知环境变化和情绪波动、主动沟通表达的存在。这标志着下一代“数字生命”的诞生。
—本文系量子位授权转载—