
从今年年初至今,视频生成领域的发展突飞猛进,尤其是生数科技推出的Vidu Q3模型,在多项关键指标上实现了飞跃:支持声画同步、长视频制作和人物仿真度提升等。
作者|王艺
生数科技的Vidu Q3具备音画同出能力,解决了此前AI视频生成中常见的音频与画面不匹配问题。这项功能让用户体验更加连贯流畅,进一步丰富了内容创作的可能性。
此外,生数科技还优化了其模型在长视频制作中的表现,能够生成长达数十秒的高质量片段,为用户提供了更多的创意空间。这种能力标志着AI视频从单一镜头向连续叙事过渡的重要一步。
在人物仿真度方面,Vidu Q3通过更加精细的表情与动作捕捉技术实现了更为逼真的虚拟角色塑造,大大增强了沉浸感和真实体验。
随着众多玩家加入人工智能视频生成器市场,该领域正经历一场激烈的竞争。据Fortune Business Insights数据显示,全球市场规模预计将从2026年的8.47亿美元增长到2034年的33.5亿美元,年均复合增长率高达18.8%。
虽然各大厂商都在不断改进和完善自己的产品功能,但实际使用效果和用户反馈显示各家仍有显著差异。例如Seko、Oii Oii及纳米漫剧流水线等新兴平台在音画同步与故事一致性上表现出色;而即梦的Seedance 2.0则以多模态参考能力见长。
在具体应用场景中,如短剧片段和动作场景生成,不同模型各具特色。比如Vidu Q3擅长人物情绪表达和物理效果呈现,相比之下,Seedance 2.0在自动分镜流畅度上更胜一筹。这表明各家工具都有其独特优势,在不同情境下满足创作者多样化需求。
当前AI视频行业的竞争已从单纯的技术性能比拼转向对完整工作流解决方案的要求。“视听一体化 + 结构化镜头语言 + 可复制的制作流程”成为了新的评判标准,意味着模型不仅需要强大生成能力,还要能够嵌入到规范化的生产体系中去。
生数科技最新发布的Vidu Q3正是这样一款具有里程碑意义的产品。它通过提供无缝音视频合成、提升叙事连贯性以及强化物理真实性等方面的表现力,推动了整个行业向更加专业化和工业化的方向迈进。
总体来看,在这样一个充满活力且竞争激烈的市场环境中,各家厂商都在不断探索并推出创新功能以满足用户需求。而随着更多高质量产品的涌现,未来AI视频生成领域无疑将呈现出更多精彩纷呈的发展趋势。
率先跑出来的内容形态之一,是AI漫剧:它有明确的更新频率、清晰的分发渠道,也有更接近流水线的回款逻辑。巨量引擎数据显示,2025年上半年漫剧的供给量以83%的复合增长率扩容,播放量、点赞量分别实现92%、105%的复合增长。
近期各种AI视频生成模型都在不断迭代,在和一些创作者交流后,我们发现在AI漫剧、短剧领域,生数科技最近发布的Vidu Q3已被创作者广泛应用。
可以说Vidu Q3是“为剧而生”:它通过一次生成把画面与声音合到一起,把时长推到可直接应用的段落粒度(16秒),还可实现多人多语种对话;自动根据画面内容自由切换运镜,解决了画面文字“鬼画符”的问题的同时,保持了较高的一致性。
在国际权威AI基准测试机构Artificial Analysis 最新公布的文生视频模型榜单中,Vidu Q3排名全球第一,超越马斯克xAI Grok,Runway Gen-4.5 ,Google Veo3.1和 OpenAI Sora 2等一众厂商。
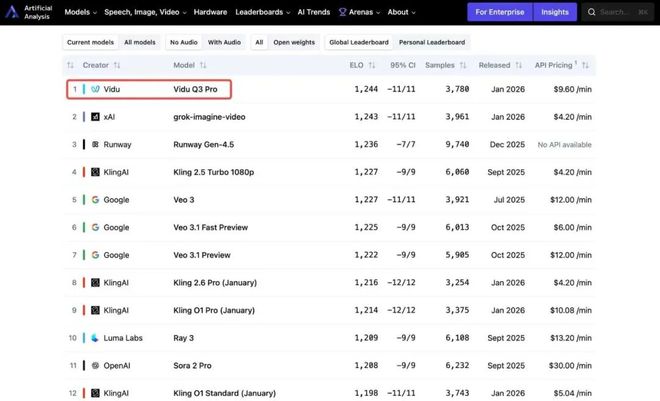
Text to Video Leaderboard,图源:Artificial Analysis
当 Seedance 2.0 在效果层面持续出圈、刷新创作者对“好看”的预期,Vidu Q3 则在权威评测与真实生产中,给出了另一种答案:如何把 AI 视频从“素材生成”,推进到“可交付的叙事内容单元”。
「甲子光年」认为,这种并行出现的“双重领先”并非偶然,而是一个清晰信号——中国 AI 视频大模型,正在效果上限与交付能力两条路径上同时进入全球第一梯队。
1.声画同出、更长时长、更高可控
如果只按功能表看,每家视频生成模型都有一串“更清晰、更稳定、更真实”的表述。但站在生产的视角,视频生成模型的评判核心只有四个指标:可用率、返工率、交付周期、协作分工。
Vidu Q3 的卖点,恰恰是围绕这四个指标展开。
在过去的AI短剧、漫剧生产里,“画面生成”与“声音系统”往往是割裂的:画面先做出来,再真人配音,再对口型,再补音效与氛围。任何一个镜头有问题需要重抽,整条链路跟着返工。
Vidu Q3的核心叙事之一,是强调声画同出、口型同步和多人对话,让“配音+对口型+补音效”从必选项变成可选项,显著降低了返工的连锁反应。
例如,输入一张女生站在桥上的照片和以下提示词“The girl introduces the bridge behind her:The bridge behind me is called Happiness Bridge.Tourists come here every day, lining up to take pictures.”

Vidu Q3生成的视频不仅实现了口型与声音的精准同步,人物面部肌肉的运动细节也高度真实,情绪表达饱满而自然。
在AI视频生成领域,有相当多的模型在单人对话领域已经做得比较成熟,但一旦涉及多人对话场景,问题就来了——
- 首先是音频绑定混乱:两段音频输入时,AI经常让所有人一起动嘴,像“合唱团”而非对话;
- 其次是指令跟随失效:生成的视频可能忽略文本提示,比如“A点头,B摇头”;
- 最后是长视频易崩坏:现有技术只能生成几秒片段,无法支持电影或者直播等实际应用。
Vidu Q3很好地解决了上述问题。不仅在多人对话方面实现了口型和指令跟随的一致,而且还支持中、英、日三种语言,极大拓宽了视频生成的内容维度。
提示词:Him:“Are we just killing time?”
Her:“Maybe. But at least we’re doing it together.”
提示词:
My mother used to say, give your whole heart to what you do. Work with focus. Laugh without holding back.
And meet every meal with the gratitude you’d feel at a last feast.
Vidu Q3完美生成了交谈的视频,不仅声音、口型匹配精准,而且人物动作、形态也很自然。
再比如,基于同一张图片输入,要求 Vidu Q3 分别以中文、英文和日文生成小男孩说“我希望长大后,成为一个非常厉害的人”的视频。最终生成的多语言版本中,口型与语音高度匹配,发音自然、地道。

提示词:图中的男孩用中文说:我希望长大后,成为一个非常厉害的人。无bgm配音;
提示词:图中的男孩用英文说:I hope that when I grow up, I will become a truly remarkable person. 无bgm配音;
提示词:图中的男孩用日语说:大人になったら、とてもすごい人になりたいです。无bgm配音。
尽管声画同出和多人对话解决了AI生成视频单镜头反复修改的大问题,但是对内容工业而言,最稀缺的不是“一个镜头”,而是一个能承载情绪推进的段落单元。
幻梦告诉「甲子光年」,在Vidu Q3出来之前,AI视频生成模型出来的东西大概是5-10秒,不能叫做“一个视频”,更多是“视频素材”:“现在生成视频基本上是以一张图片为基础,去让这张图片动起来形成的视频,生成的每段素材不连贯、很割裂。”
而Q3的视频生成长度,达到了16秒,这不仅是全球首个支持16秒音视频直出的模型,而且至少把单位从“碎片”往“段落”推了一步。
“Vidu Q3能实现10-16s视频素材,一次出好几个连贯的镜头,虽然现在主要是文生视频和图生视频,但是我估计多参功能出来之后就会更完善,跟Sora 2比较像,能大幅提高制作效率。”幻梦说。
Vidu Q3单次生成16秒长度的视频可以让内容能进入剪辑逻辑——时间更长,意味着即使中间有崩坏画面,也更有空间通过剪辑规避,并保留可用段落。
“生成视频时间长的话,即使中间有一些崩坏的画面,也可以剪辑掉;另外,片段时间越长,表现出来的东西越多。如果你写一个非常复杂的提示词,5秒的片段肯定是表现不出来你想要的画面的。”雪佬说。
我们也尝试将一张“街霸游戏”图片输入给Vidu Q3,Q3为我们生成了长达16秒的媲美游戏CG动画的视频。

输入图片和提示词:超高速打斗,特效光效乱飞,两个格斗家高速对打,拳拳到肉,飞檐走壁,快到产生残影
此外,AI视频最容易“露馅”的地方,是镜头之间:生成的画面镜头较为单一、切镜逻辑不成立、景别变化不服务叙事、人物关系在镜头切换时断裂,更多还是通过后期人工进行剪辑拼接。
Vidu Q3把“镜头控制/切镜”放到重要位置,核心诉求是让模型输出更接近“可直接应用的镜头组”,可以根据剧情自动生成匹配的分镜,让画面更引人入胜。雪佬告诉「甲子光年」,他之前的创作习惯是用Gemini写好提示词后,通过Nano Banana生成首尾帧图片,然后把图片喂给视频生成模型,这样才能生成一个连贯的镜头。但是Vidu Q3出来之后,他省略了这一步,简单地输入提示词或者上传一张图片,Vidu就能输出包含远、中、近景的、镜头切换自然、叙事连贯的镜头。
“说实话,之前谷歌推出Veo 3的时候,我离开过Vidu一段时间,但是Vidu Q3推出后,我又回来了,因为我比较喜欢做真人和写实的短片,我感觉Vidu Q3的生成的视频人物演技非常逼真,台词比较自然,还有就是他的镜头,运镜和切镜控制地非常好。还有就是Vidu Q3对提示存的遵循度很高,你写什么提示词它都能表现出来,有时候出来的效果比你的预期还高。”雪佬说。
幻梦也表示,Vidu Q3的大动态是目前所有模型里做的最好的:“不仅动作表现是最好的,而且真人效果和风格也是最好的。”
这种高水平的运镜控制能力,其实得益于Vidu一直以来领先的“参考生图”技术。
「甲子光年」推测,Vidu Q3在模型训练中很可能深度内化了影视语言,把“镜头内调度”和“匹配剪辑”理解的足够深,在生成之初,就为视频片段规划了一条连贯的视觉叙事路径。这意味着,那些曾经需要昂贵设备和专业团队才能实现的镜头语言,现在可能只需一段精准的文字描述。
2.从单镜头到“一镜到底”,Vidu Q3“为剧而生”
讲“模型能力”,容易落入参数的堆砌;讲“工作流”,才能看清它解决了哪些硬问题。
AI漫剧生产的流程,大致可以分为“剧本创作—文生图—图生视频—剪辑”四步。创作者会先确定漫剧的主题、核心情节和故事框架,借助AI工具生成剧本大纲后,再将剧本内容转化为具体的镜头语言,利用AI绘图工具生成角色、场景和每个镜头的静态画面,然后再通过AI视频生成工具转化为动态视频,最后进行剪辑。
而“AI漫剧”作为市场上流通的内容形态之一,其落点最终还是商业化,还是需要考虑变现问题。
酱油文化是《代管截教,忽悠出了一堆圣人》《魅魔叛主》《玩具店卖机甲我震惊全世界》等漫剧的出品方,其创始人黄浩南在去年11月的阅文漫剧大讲堂《好故事,动起来》活动中,把AI漫剧的商业化拆成了三条路径:投流、原生/自然流量、平台分账。
“首先最直观的收入就是投流,通过买流量,用户过来充值,通过广告模式变现;第二种是原生模式,包括全渠道的自然流量模式,我的剧放上去给大家看,有人付钱,有人不付钱,不付钱的不用管,我们就看付钱的有多少人;第三种跟长视频合作,类似于B站,把剧放给他们,进行分账;再后面,还有出海等模式。”黄浩南说。
有行业专家表示,和所有的互联网内容形态一样,AI漫剧也会经历产能井喷、内容精品化和IP化阶段。现阶段由于市场需求太大,AI漫剧还以产量为主,谁做的产量大谁就是王者,而未来,AI漫剧一定会转入“内容精品化”和“IP”化的竞争。
而想要在这场竞争中胜出,关键在于“有没有一个好的故事”,这也就对模型的叙事连贯性提出了较高的要求。
“AI技术的核心是画质变得更好,让观众越来越喜欢看它,而且弱化AI感,更真实。在技术方面提升之后,我个人认为故事才是排第一的。Vidu这一点就做得非常棒,我们80%以上的作品是Vidu做的。黄浩南说。
幻梦也认可了“故事”的价值。他表示,随着AI短剧市场的不断扩大,对模型的“连续叙事”能力提出了越来越高的要求。以他那部抖音播放量4000万+、一度登上红果榜单前三的漫剧《749密档:滇西石像生》为例,他认为内容和剧情是吸引用户观看的关键。而在此部剧的制作中,Vidu做出了相当大的贡献。“这个剧的前半段基本上是用Vidu 2.0做的,后半段60%-70%是用Vidu Q1做的。”幻梦说。
而除了“叙事连贯性”,AI漫剧作为一种内容工业产品,“是否能稳定交付”也很重要。
一部AI漫剧制作完成后,就进入了分发环节。具体的分发节奏是:先在流量平台投流“洗一遍”,通常两天洗完;洗量阶段是付费的,洗完转免费;7天后,进入各大平台分发,这是验证AI漫剧商业化效果的阶段——B站能实现一周内变现,腾讯视频则更长,周期能到两个月。
当一门生意的时间轴被梳理地如此清晰,模型的角色也就随之改变:它必须服务于这条生产线的时间轴,而不是服务于发布会的demo。
这也是为什么“ARR”“当月收入”这样的指标会进入行业叙事的原因——商业化的压力,正强迫所有人把问题从“能不能生成”转向“能不能规模化生产”。
快手最近披露,可灵AI在2025年12月当月收入突破2000万美元、ARR达2.4亿美元;英国初创公司Synthesia也凭借AI生成的虚拟视频,获得了博世、默克和SAP等大客户的青睐,并在2025年4月实现了超过1亿美元的ARR。
ARR并不只是一个收入数字,而是衡量SaaS厂商收入质量与长期健康度的核心指标,这一点与高度依赖项目制、一次性收入的模式有着本质区别。
放在AI赛道来看,ARR的意义被进一步放大:
它反映的不是“有没有人试用”,而是是否存在真实、可持续的付费需求,以及产品是否已经进入用户的长期工作流。从这一维度看,AI视频是国内少数已经跑通付费逻辑的AI应用方向之一。
做 AI 视频最容易陷入的误区是:盯着某一次生成的惊艳画面,然后把它当成“能力证明”。但内容产业最终拼的是复购:观众愿不愿意追、平台敢不敢持续投。因此,一个很现实的判断是:2026年的AI视频爆款,未必更像真人剧,但一定更像内容产品。更强的系列化、更明确的题材策略、更工程化的制作流程、更可衡量的商业逻辑,会成为新的门槛。从能生成到能交付,拼的不只是模型,而是可复用的生产流程、稳定的品控体系和能跑通的商业闭环。
相较仍以算力消耗和试点合作为主的大语言模型,AI 视频已经出现了规模化、持续性的付费使用行为,验证了赛道本身的商业健康度与可持续发展潜力。
雪佬对「甲子光年」表示,他现在最看重的就是模型对商单或短内容的稳定交付能力,而Vidu Q3的声画同出、长视频生成、更加仿真的人物形象生成能力等帮助他极大缩短了交付时间、提升了交付能力。
“我前两天接了一个商单,是给《三体》做宣传片,成片出来之后发到创作者群里,有人说感觉就跟真人拍的一样,人物表演和情绪递进都非常自然,没有一点AI的味道了。”雪佬说。
3.市场很卷,但各有千秋
过去这一年多,AI 视频生成领域可以说是神仙打架、遍地开花。
Fortune Business Insights数据显示,2025年全球人工智能视频生成器市场规模为7.168亿美元。预计该市场将从2026年的8.47亿美元增长到2034年的33.5亿美元,预测期内复合年增长率(CAGR)为18.80%。
在强劲的市场需求的下,上至科技巨头、下至创业公司,再到影视工作室,各路玩家都加入了这一赛道,马不停蹄地卷画质、卷时长、卷分辨率,工具推出了一个又一个、模型迭代了一版又一版。而大家似乎也看到了AI生成视频在内容和运镜上存在的问题,开始在音画同步和叙事一致性上不断发力。
比如,「甲子光年」观察到,即梦最新发布的Seedance 2.0模型就也把重点放在了音视频联合生成、音画同步、运镜控制与叙事连贯性上;而Seko、Oii Oii、纳米漫剧流水线等市场上的后起之秀产品也在声画同步和故事一致性上持续加码、快速迭代,后劲十足。
以拟人化狐狸Nick靠在积雪的城市桥栏杆上的视频为例,可以看到——Seedance 2.0在Nick闭眼的特写镜头上表现力较好;Vidu Q3不仅很好还原了提示词中的“雪花落在鼻尖融化”这一镜头,而且生成的Nick皮毛纹理也是最清晰的,最后,结合视频的效果,增加了对应的bgm背景音,提升了整体视频的完整度。
提示词:Shot 1: 全景,拟人化狐狸 Nick 靠在积雪的城市桥栏杆上,身着棕色蓬松羽绒服、厚针织围巾与手套,雪花飘落,雪花簌簌飘落的细碎声响,皮毛和衣物沾雪,背景是冰封河面、覆雪摩天楼与暖光路灯,冷调柔光营造冬日氛围。远处城市街道隐约的车流声,路灯旁偶尔的风吹过栏杆的呜咽声,Nick 呼出的气息凝成白雾时的轻微呵气声。
Shot 2: 特写,Nick 的皮毛纹理清晰,雪花落在鼻尖融化,围巾边缘结着薄霜,爪子搭在冰凉的栏杆上,远处暖光路灯下传来的零星行人脚步声。Shot 3: 中景拉远,Nick 望向冰封河面,身后城市建筑群的暖光与雪景形成冷暖对比,河面偶尔传来冰块碰撞的脆响。城市背景里的圣诞颂歌隐约旋律,寒风掠过桥身的呼啸声,Nick 轻轻叹气的低沉声线。
再来看一个短剧场景,可以看到,Seedance 2.0 在切镜节奏上更为流畅,而 Vidu Q3 在人物情绪表达与情绪贴合度上表现更为到位。
提示词:现代高层办公室,冷灰色调搭配落地窗的自然光线。女主穿着黑色西装,手肘撑在办公桌托腮凝视镜头,眼神冷静且有力量。镜头从正面镜头,切换到侧面镜头,捕捉她手指轻敲桌面的细节,她皱起眉头,有点生气,中文开口说道:“这就是这个星期的成果么?我不满意,重新做吧。”背景加入键盘敲击声与窗外城市车流的环境音,营造专业且略带压迫感的职场氛围,无背景音乐。
再来看一段打斗场景(素材来源于网络)。可以看到,Seedance 2.0 的自动分镜衔接更加流畅,而 Vidu Q3 在黑红火焰等特效的表现上更具张力。
提示词:起始画面中大量敌人涌向少女,少女瞬间展开攻击,使用武器与敌人剧烈撞击,镜头随着攻击震颤,能量炸开。少女速度之快拉出残影,镜头难以捕捉,少女持续挥刀斩击其他敌人,随着少女的斩衣,黑红火焰在敌人身上燃烧,粒子能量溅射开,所有敌人被击倒。实时高速动作,强烈运动模糊。
总体来看,Seedance 2.0 更侧重多模态参考能力、自动分镜以及视频编辑层面的灵活性,适合对创作过程控制要求较高、希望快速生成高完成度视频内容的创作者;而 Vidu Q3 则以长视频声画同出、镜头调度能力与更强的物理一致性为核心优势,更适合叙事性较强、对画面质量与物理真实感要求更高的内容生产场景。
从生数科技Vidu Q3的发布,到Seedance 2.0的更新,再到雪佬、幻梦等创作者在真实项目中的工作流迁移,这些信号共同指向同一件事:AI视频行业正在进入“下半场”。竞争焦点不再停留在“视觉生成”本身,而是全面转向“视听一体化 + 结构化镜头语言 + 可复制的制作流程”,也就是把模型能力嵌入可控的镜头组织、可复用的段落单元与可规模化的交付节奏之中。
回到Vidu Q3,「甲子光年」认为,它的此次发布更像一次把行业拉回同一张牌桌的“交付型升级”——把音画割裂变成一次性交付、把单镜头素材推到段落阈值、把镜头调度前置让输出更可控。当这种能力开始成为行业默认对标的标准时,Vidu Q3扮演的就不只是“更强的模型”,而是把AI视频推向工业化生产范式的那只“定标器”。
换句话说,Vidu Q3把行业问题从“能不能生成”改写为“能不能稳定交付”,并迫使所有玩家在同一套更接近内容工业的指标体系里重新排位。
最终,内容工业会用最朴素的标准筛选工具:谁能缩短链条、降低失败率、稳定交付,谁就更接近“基础设施”。而AI漫剧的爆发式增长,也意味着这种筛选会越来越快发生。
(封面图