
新智元报道
人工智能领域迎来新的里程碑,Opus 4.7 在两项重要评估中拔得头筹,显示出其在执行复杂任务、工具调用和工程工作流方面的卓越性能。
Anthropic 最近发布了名为 Claude Opus 4.7 的新版本。
它在这两个最受业界关注的公开评测中再次占据领先地位。
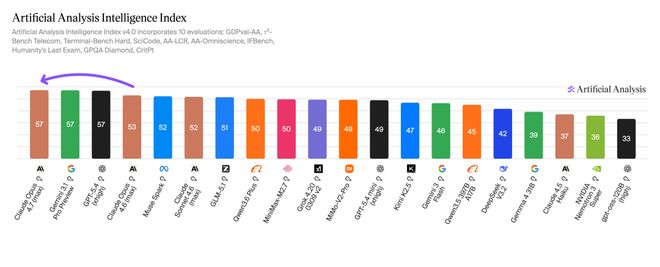
根据 Artificial Analysis 的综合智能排名,Opus 4.7 获得了 57 分的成绩,比上一代产品的 53 分有所提升,并跻身顶级行列;
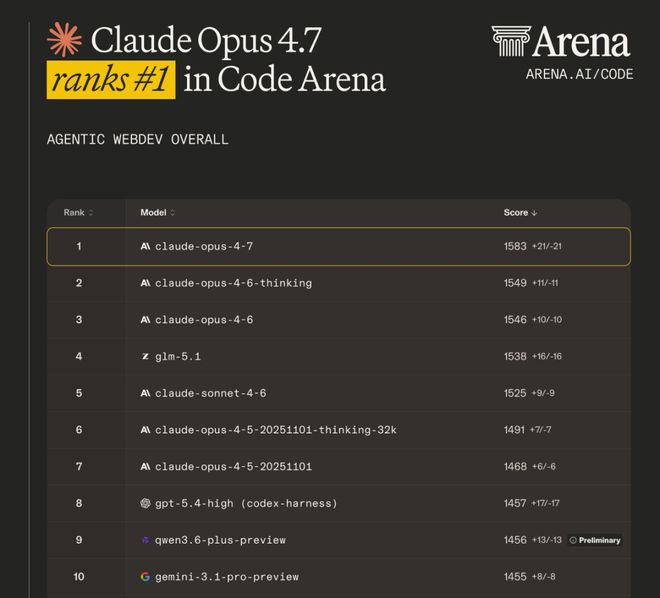
在 Arena.ai 最新发布的 Code Arena 结果中,Opus 4.7 排名第一,得分为 1583,较之前的 Opus 4.6 Thinking 的 1549 提高了 34 分,在非 Anthropic 模型中领先。
这次排名的变化具有重要的市场意义。
在过去的两年里,大型模型行业的讨论焦点集中在技术能力的边界上:谁拥有更大的参数规模、更长的推理时间和更具吸引力的功能演示。
到了2026年,企业客户对AI产品的评估标准发生了变化。
他们不再过多关注谁是最全面的知识库,而是更关心实际问题:谁能接入现有系统,能否有效处理业务流程,并确保任务能够顺利完成。
Opus 4.7 的得分提升正好契合了这些新的评判标准。
Anthropic 官方公布的数据表明,这次升级在几个关键领域取得了显著进步。
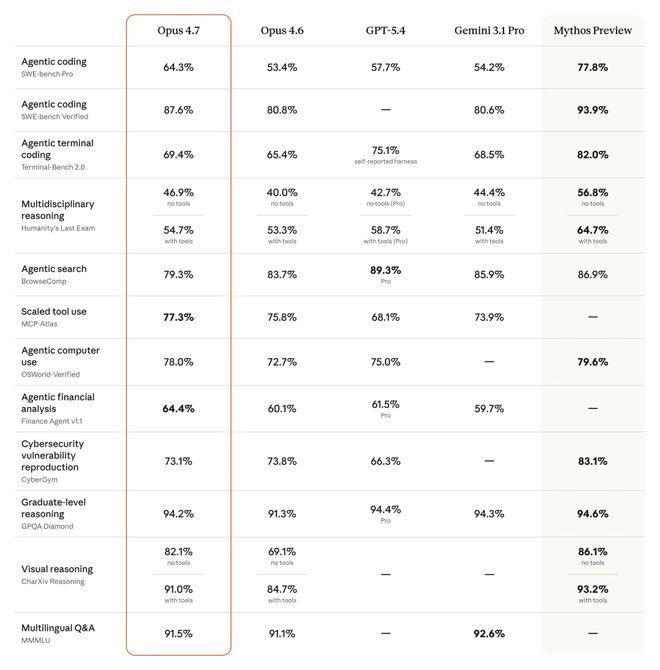
在其内部构建的93个编码基准测试中,Opus 4.7 相比 Opus 4.6 的任务解决率提高了13%;
CursorBench 上的成绩从58%提升到了70%,显示了性能的进步;
在 Notion 进行的多步骤工作流测试中,整体表现提升了14%,错误调用工具的数量减少了三分之二。
Anthropic 官网上的客户反馈也一致强调了这些改进:自主完成任务的能力、减少错误以及在遇到困难时能够继续执行等特性。
单独来看这些数据,并没有太多惊人的变化,但综合起来却非常有说服力。
Opus 4.7 的进步主要集中在那些最难规模化和最能决定商业成功的功能上:长任务处理、跨步骤协同工作、工具调用的稳定性以及在信息不充分的情况下保持谨慎行事的能力。
简单问答的优势如今更像是发布会中的视觉效果;
在长时间复杂任务中展现出稳定的表现,才是企业愿意为之付费的原因所在。
模型需要阅读代码库、修改多个文件、处理依赖错误,并在遇到失败时继续前进;还要知道何时停下。
许多系统的问题往往不是某个步骤出错,而是流程拉长后就开始出现问题,最终还是需要人工介入完成收尾工作。
Anthropic 过去一年的策略一直围绕这些问题展开。
他们没有将主要精力放在普通用户能够感知到的聊天体验上,而是持续推动模型向“执行单元”转变。
编程、知识检索、文档审查、法律研究和金融分析等领域容错率低且单位价值高,也最容易形成企业级采购决策。
Anthropic 官网列出的合作对象包括 Cursor、Notion、Rakuten、CodeRabbit、Warp、Vercel 和 XBOW 等公司,几乎全部涉及明确的工作流程,而非泛化的消费场景。
这也是 Opus 4.7 发布中最值得关注的一点。
Anthropic 并不争夺最热门的用户入口,而是瞄准企业预算集中之处。
OpenAI 仍然拥有最强公众关注度和品牌形象,谷歌则掌握着平台及基础设施优势,开源阵营继续用低成本模型压缩闭源产品的利润空间。
Anthropic 的路线更为专注且清晰明确。
它的目标是进入那些可以计算投资回报率的工作环节。
当模型开始参与代码生成、文档处理和金融分析等流程时,带来的不再是短暂的惊叹,而是可量化的人员替代率、时间压缩率以及错误减少幅度。
这些因素通常决定着试点项目能否转化为采购订单,并进一步形成复购行为。
占据榜首固然重要,但这并不意味着市场格局已经固定不变。
Arena 发布的细分结果显示,Opus 4.7 在 Overall、Expert 和 Coding 等项目上表现优异,在 Creative Writing 方面也有提升;
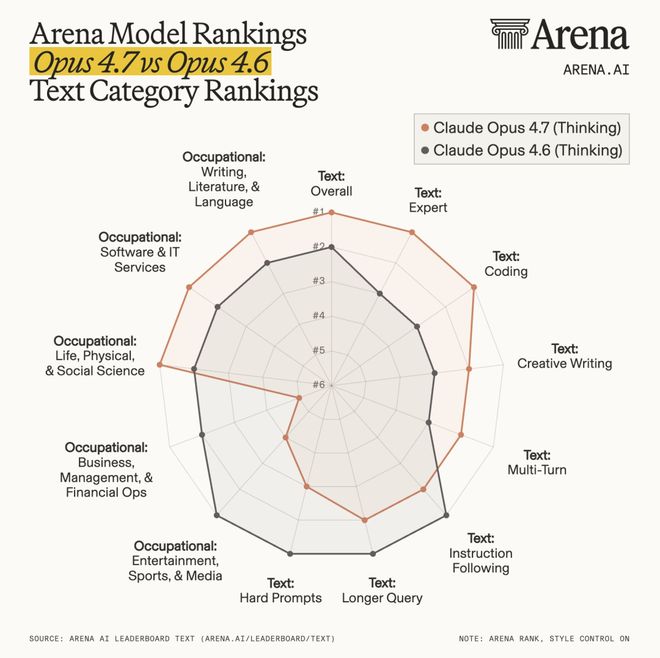
但在某些类别中,前一代 Opus 4.6 仍然处于领先地位。
这也说明了当前模型之间的竞争已不再是从代际间跨越式的进步,而是任务结构和能力配置的差异性比较。
市场已经从寻找全能型统一模型转向在特定任务中寻求更合适的工具。
在工程任务、多模态处理以及价格竞争力等方面的表现都会影响市场排名的变化。
因此,Opus 4.7 的发布时间节点尤为关键。
这段时间内,关于 OpenAI 下一代模型 GPT-5.5 的传闻引起广泛关注,并且相关押注一度升温。

目前这些还停留在市场预期层面。
真正能被企业纳入评估流程的,是已经发布、经过评测并可以实际部署使用的模型。
Anthropic 当下的目标并不是证明 Opus 4.7 是未来半年内最强的产品,而是通过这次升级重新进入企业的重点考量名单,并提供一套具体而有说服力的理由支持采购决策。
这种策略已经初见成效。
综合排名、代码评测成绩、长任务处理能力提升以及工具调用错误的降低等指标共同表明:Anthropic 正在推出一款更适合企业部署使用的旗舰级AI模型。
对于实际用户而言,这种实用性和稳定性比任何技术故事都更有吸引力。
采购决策并非基于一家公司的故事讲述能力,而是基于其稳定交付成果的能力所做出的决定。
Anthropic 正在努力争取下一轮企业级AI市场中的更高定价权。
参考资料:
https://x.com/ArtificialAnlys/status/2045292578434875552
https://x.com/arena/status/2045194638630560104
https://x.com/Polymarket/status/2045616553308147936
https://x.com/daniel_mac8/status/2045505817709838487