在使用OpenClaw挂机的过程中,用户常常会遇到烦人的bug导致网页抓取失败的问题,而现在这些问题终于有了有效的解决方案。
最近出现的一个叫做Scrapling的数据采集工具,在很短的时间内就成为了广受欢迎的辅助插件,帮助解决了困扰已久的难题。
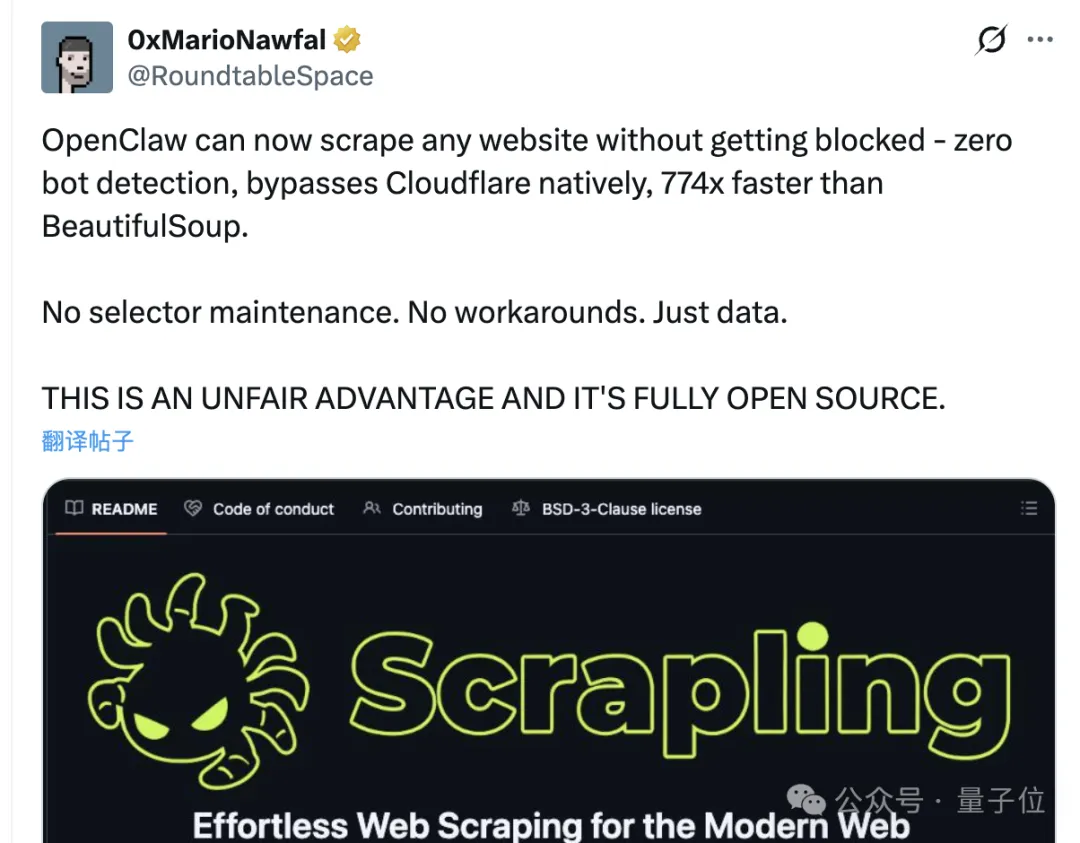
这款软件不仅能突破各种网站反爬机制,还能将杂乱无章的网页源代码转换为清晰有序的数据结构。
自从这款已经发布了超过一年时间的项目重新焕发生机后,它的人气急剧上升,短短时间内就获得了2.3万个星标,并且在GitHub的日趋势排名中名列榜首。
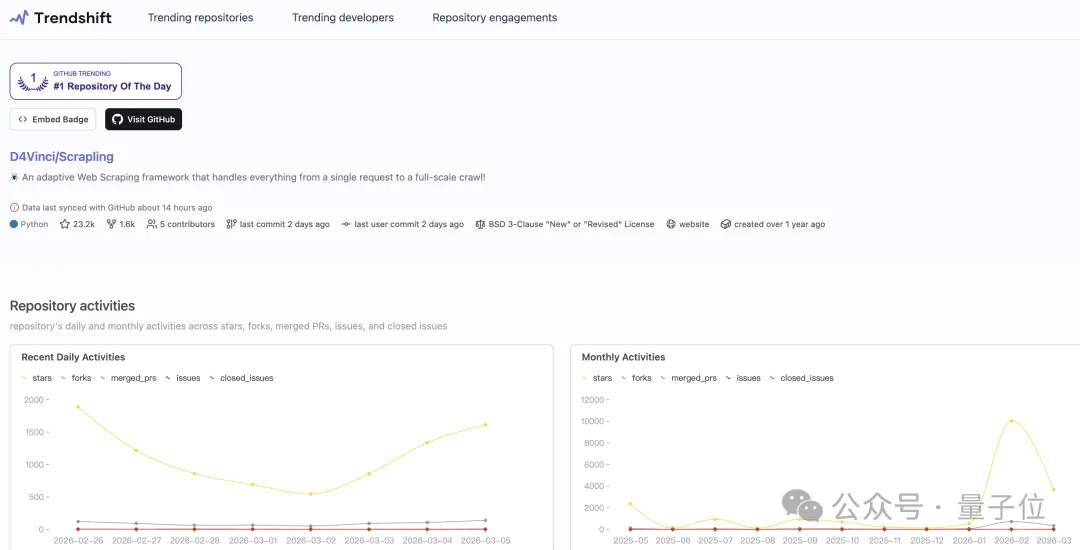
随着该工具热度飙升,原作者明确表示正在将其整合为OpenClaw的功能之一,这无疑让人们对未来的改进充满了期待。
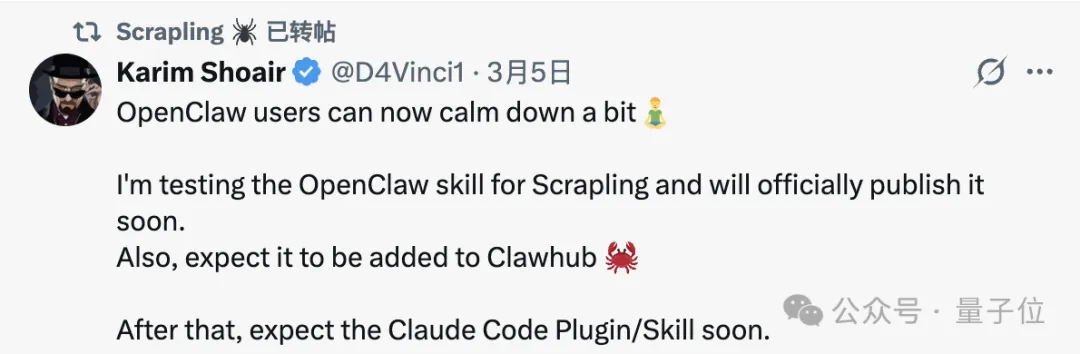
数据爬虫成为AI挂机的得力助手
当智能体需要从网页抓取数据时,通常会遇到让人头疼的人工验证页面,稍有不慎就会被封锁访问权限。
Scrapling自带的StealthyFetcher模块就是专门用来处理这些烦人的拦截措施的工具。
它可以模拟最新浏览器的行为模式和指纹信息,使得OpenClaw能够轻松绕过网站设置的各种障碍。

网站的频繁更新同样给爬虫带来了挑战。
传统的数据采集软件往往局限于固定的路径规则,一旦网页结构发生变化,自动化任务就会停止工作并引发错误。
这种情况会导致AI的工作流程中断,并且需要手动修改代码才能继续运行。
Scrapling的一个显著特点是它具备一套智能化的自适应算法。
即便网站进行了彻底的结构调整或更新,它的解析器也能通过对比相似度来识别数据所在位置并重新定位关键信息。
拥有这种无需人工干预的智能追踪能力后,用户可以实现全天候无间断的数据抓取,再也不用担心因网页突然变化而导致挂机任务中断的问题了。
轻松上手,还能省钱
既然AI已经能够像家用机器人一样自如地绕过网站拦截并处理页面更新,接下来的重点就是如何更加高效地利用获取的信息。
这个过程可以通过启用Scrapling内置的MCP模式来实现。
在将数据输入大型模型之前,该工具会先剔除网页中的冗余信息、广告和无用代码,只保留核心内容。
由于传输给AI的数据量减少,API调用的成本也随之降低,从而达到了节省资源的效果。
此外,它对硬件的要求也非常低。
这款框架占用的内存非常少,即使使用老旧笔记本或入门级服务器也能顺畅运行。

更值得一提的是,它还具备断点恢复功能,对于长时间挂机任务来说是一个非常实用的功能。
在网络中断或电源故障的情况下,爬取进度会被保存下来,当条件恢复正常后,它可以自动继续之前的工作而无需重新启动任务。
这个插件不仅兼容各种设备,并且对用户的技术要求不高。
它提供了一套易于使用的命令行工具,只要按照教程输入简单的指令就能调用其所有功能。
作者还表示正在将这款插件整合进OpenClaw的Skill中,这意味着每个普通用户都将能够轻松为自己的AI挂机系统增添一双洞察一切、精准抓取数据的眼睛。
项目地址:
https://github.com/D4Vinci/Scrapling