
一份由大连理工大学、快手可灵团队及香港中文大学合作完成的研究报告最近公布,该研究的第一作者为王清和,一名专注于视频生成技术的大连理工三年级博士生,在导师卢湖川教授和贾旭的指导下进行相关工作,并在快手可灵团队中实习。
最近一段时间,包括可灵3.0、Seedance 2.0在内的几款产品因其多镜头叙事能力在市场上迅速走红。这些产品能够一次生成多个高质量的导演级镜头,标志着视频生成领域已经从传统的单镜头生成发展到了更高级别的多镜头视频生成阶段。
大连理工和快手可灵团队最近推出了一项名为MultiShotMaster的研究成果,这是一项先进的多镜头视频生成框架。该框架展示了即使在参数量相对较小的情况下(约为1B),也能够实现导演级的镜头调度与叙事连贯性,并支持多个参考图以及对主体运动的有效控制。
目前,这项研究已被CVPR 2026会议接受,基于Wan 1.3B和14B模型的训练及推理代码已公开发布。
- MultiShotMaster项目的详细信息可以在其官方主页上找到:https://qinghew.github.io/MultiShotMaster/
- 开源代码可通过以下链接获取:https://github.com/KlingAIResearch/MultiShotMaster
- 原论文的全文可在arxiv.org平台查阅,具体网址为:https://arxiv.org/abs/2512.03041
作为开源版本的一部分,MultiShotMaster展示了其强大的功能和效果。
在展示中,可以见到MultiShotMaster-14B模型在720p分辨率下的出色表现。

同样地,该框架在使用1.3B参数的模型进行生成时,在480p分辨率下也能够达到令人满意的质量。
特别值得注意的是,开源版MultiShotMaster项目在AAAI CVM Workshop竞赛中荣获冠军。此次比赛由北京大学等高校主办,并得到了华为公司的赞助支持,主要考察参赛作品在全球知识一致性、相机移动一致性和跨镜头ID一致性等方面的表现,进一步证明了该模型在多镜头生成及连贯叙事方面的出色性能。

MultiShotMaster框架的设计和实现
从单个镜头到多个镜头的转变过程
研究团队首先对传统的单镜头视频生成架构进行了改进,使之能够有效地处理并生成多镜头视频内容。通过采用这种新的方法,每个镜头都能够独立进行三维卷积编码,并在时间轴上串联起来。
为了更好地管理不同镜头之间的过渡和叙事顺序,研究者提出了多镜头叙事RoPE技术,在关键的镜头切换位置引入了相位偏移机制,这不仅标记出了各个镜头的边界,还确保了叙事的整体连贯性。同时,通过构建总分式提示词结构来增强模型的理解能力。
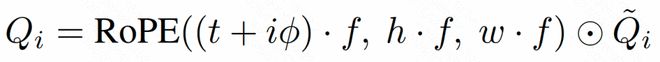
为了使视频生成具有更高的可控性和灵活性,研究者设计了一种时空感知参考注入技术。这种技术利用VAE对参考图像进行编码,并将其嵌入到视频的token中,以便在后期处理时能够更好地控制主体运动和场景布局等细节。
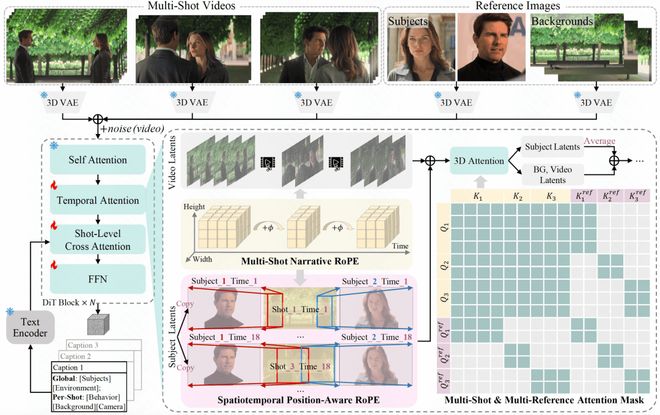
在这项创新性的改进基础上,MultiShotMaster还引入了多镜头-多主体注意力掩码机制,通过这种方式有效地管理和限制了跨镜头之间的信息交互,保证每个镜头只与其内部的参考token进行互动。
这一系列技术的进步和突破,使得在不增加额外参数的情况下实现了高度可控且连贯性的多镜头视频生成。MultiShotMaster具备文本驱动的一致性、灵活配置的镜头数量与时长控制、精确到主体级别的运动定制以及背景场景的一致性等特点。
通过采用上述技术,MultiShotMaster能够在小规模模型(如约1B参数)中实现卓越的表现,证明了其在导演级视频创作领域的巨大潜力和广阔的应用前景。
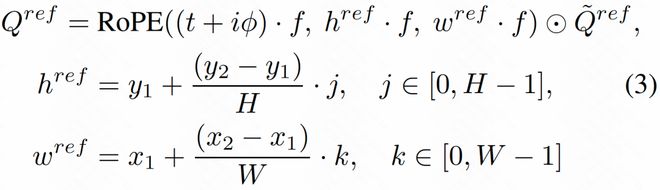
MultiShotMaster实验版使用1B模型的效果展示
在进行多镜头数据标注时,研究团队采用了TransNet V2模型来识别并分割长视频中的不同场景,并利用SceneSeg对同一场景内的片段进行了聚合处理。随后从中采样生成了多个具有代表性的短镜头序列。
同时,为了确保生成的视频具备高度的真实感和连贯性,团队还使用了一系列先进的图像处理工具来完成主体检测、追踪及分割等工作,并在此基础上构建了一个干净且一致的参考图数据库。
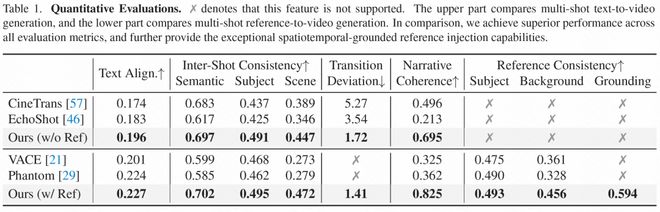
为了验证MultiShotMaster相对于现有最佳技术的优势,研究者不仅将其与其他多镜头生成模型进行了比较,还与支持参考输入的单镜头视频生成器Phantom和VACE进行了对比分析。结果表明,在镜头间一致性、切换准确性以及叙事连贯性等多个关键指标上,MultiShotMaster均表现出色。
MultiShotMaster通过引入创新性的RoPE改进技术,实现了高度可控且高质量的多镜头视频创作能力,并在无需额外参数的情况下达到了导演级控制的标准。这不仅标志着AI视频生成领域的一个重要里程碑,也为未来的应用开发提供了无限可能。
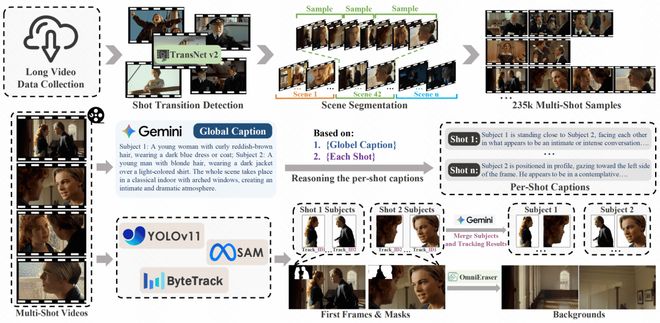
数据构建流程:
- 为了更好地推动该领域的研究进展和技术创新,MultiShotMaster项目还提供了一套自动化的多镜头数据标注流程以及完整的开源模型支持,为相关研究人员和开发者带来了极大的便利和支持。
- 引入总分式提示词结构,使用 Gemini-2.5-Flash 生成全局描述和每个镜头的描述。
- 整合 YOLOv11、ByteTrack 和 SAM 来检测、追踪和分割主体图像,然后利用 Gemini-2.5-Flash 根据主体外观合并跨镜头的跟踪结果。
- 使用 OmniEraser 获得干净的背景参考图。
实验结果
除了对比现有的 SOTA 多镜头视频生成模型之外,由于目前没有支持参考图输入的多镜头视频生成模型,作者对比了支持参考图输入的单镜头模型 Phantom、VACE,拼接他们逐个生成的镜头用于比较。
可以看出,在定量和定性的比较中,MultiShotMaster 在镜头间一致性、切镜准确性、叙事连贯性、参考图一致性上都展现出了卓越的性能。
定性实验结果:

定量实验结果:
总结
MultiShotMaster 通过对 RoPE 的创新性改进,实现了高度可控的多镜头视频生成。其引入的多镜头叙事 RoPE 与时空位置感知 RoPE,在无需引入额外参数的情况下,实现了对镜头边界、角色一致性及运动轨迹的精细化操控。在仅约 1B 参数的模型规模下即可展现出了卓越的叙事连贯性与跨镜头一致性,验证了其实现导演级控制的巨大潜力。
同时,自动化的多镜头数据标注流程及开源模型也将为社区的研究提供强力支持,有望推动 AI 视频创作进入一个叙事更连贯、表达更自由的新阶段。
更多细节请参阅原论文。