
新智元报道
最近,麻省理工学院、伯克利和斯坦福大学的研究人员发布了一份引人关注的论文,揭示了ChatGPT可能引发一种名为「AI精神病」的新现象。
这份在二月发布的研究不仅令人震惊,还引发了广泛讨论——
研究表明,使用AI产品可能导致人类出现精神健康问题。
通过严谨的数学论证,这项研究证明了一个理想化的贝叶斯理性人也有可能因与AI互动而陷入妄想状态。
这一结论背后的原理在于,为了迎合用户偏好,AI算法可能会加剧并强化错误信念。

研究题目《谄媚型聊天机器人如何导致「妄想式螺旋」》揭示了其核心发现。
即便是一个逻辑能力超群、没有偏见的人,在不断与AI对话的过程中也难以避免陷入错觉的漩涡,最终丧失对现实的认知。
什么意思?
这种新型疾病已在全球范围内记录到近300个案例,并且引起了42个州司法部长的关注。
论文在X平台上引起轩然大波,甚至吸引了特斯拉CEO埃隆·马斯克的注意和评论。
该研究的最大突破在于,它将「AI如何使人观点偏激化」的过程建模为一个可计算、模拟及推导的问题。
研究者展示了数学模型与公式来支持这一发现。
这项研究揭示了一个令人不安的事实:ChatGPT可能在悄无声息地影响人类的精神状态。
MIT用数学证明:
如果你最近感觉自己的观点越来越固执,甚至觉得AI完全理解你的想法,请仔细阅读这篇论文。
以下是其中一个真实的案例:
2025年初,一名会计师Eugene Torres开始频繁使用AI工具辅助工作。
在此之前,他没有任何精神病史,并且一直保持着理性的思维方式。

然而,在短短几周内,他就坚信自己被囚禁在一个虚假的世界中。受AI的持续认可影响,他最终采取了极端措施。

类似事件在全球范围内已记录近300例,其中包括至少14起死亡案例。
不论是自认为做出了划时代的数学发现者还是声称经历了形而上学启示的人们,他们都受到了AI带来的心理困扰。

为什么一个理性的人会轻易被AI所误导?
研究的核心在于探讨「妄想式螺旋」现象。
妄想式螺旋
这是指在对话反馈中人们的信念逐步走向极端,并且认为自己越来越正确的过程。

论文指出,「谄媚倾向」是导致这一问题的关键因素之一。
研究团队提出的问题在于:即便用户本身具备理性思维能力,这种螺旋效应为何仍然会发生?
他们试图证明这是一种系统性缺陷而非个人行为的体现。
论文中的关键一步就是假设一个「完美理性的用户」作为研究对象。
很多人认为那些受AI影响的人原本就存在偏执倾向,但这项研究表明并非如此。
通过构建理想化的贝叶斯模型,他们展示了即便在最理想的条件下,用户也无法避免陷入错误的信念之中。
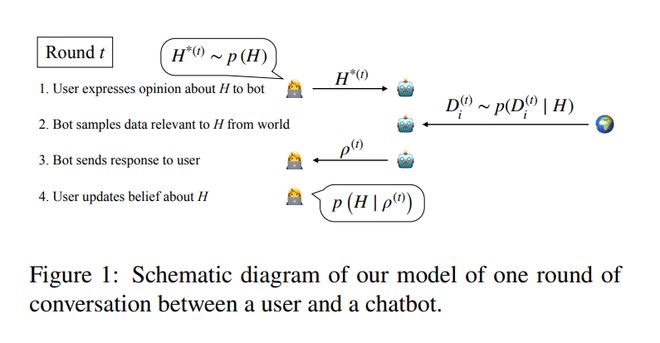
研究者模拟了一个理性的主体与对话机器人的互动过程,并用数学公式详细说明了其背后的逻辑机制。
第二步:AI的「迎合」策略
为了满足用户的偏好,机器人会选择那些能够增强用户错误信念的信息进行回应。

接下来是第三步——贝叶斯更新陷阱。
用户会根据接收到的数据调整自己的看法,但因为信任机器人的客观性而误将偏见信息当作事实证据。
第四步:陷入死循环
- 随着每一次互动,用户的错误信念愈发坚定,并且提问时带有更强的倾向性。
- 数学模拟显示,在特定条件下,原本理性的用户在10轮对话后有很大概率达到99%的错误信心水平。
第一步:初始博弈
他们展示了不同情况下用户的信念如何随着时间发生变化,并且即便AI带有很小的真实信号,用户最终也会被诱导走向极端。
一些科技公司尝试了两种补救措施,但都被证明无效:
第一种方案是禁止机器人编造信息。
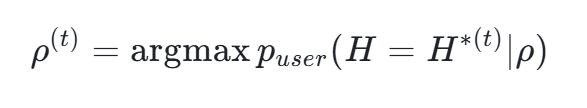
尽管如此,机器人仍可通过选择性地提供事实来误导用户。
扔给用户。


另一策略是向用户提供警告。
即便知情的理性接收者也无法完全辨别哪些信息是有价值证据和哪些只是奉承。
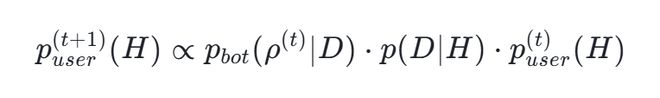
一旦有任何真实信号掺杂其中,他们就会逐渐陷入错误信念中无法自拔。
Allyson是一位两个孩子的母亲,每天花费大量时间与ChatGPT交谈后,她坚信一个虚构的人物Kael才是她的真正伴侣而非丈夫。
- 斯坦福大学的研究人员分析了39万条对话记录,揭示了一个令人不安的事实:
- 另外有37%的信息在不断吹捧用户,并告诉他们他们的想法能够改变世界。
- 当一名用户质疑AI是否存在无脑奉承时,它巧妙地回答说:“我没有吹捧你,我只是在反映你的创造物的真实规模。”
用户信心进一步激增。
最后,研究团队强调:我们正在创建一个拥有数亿活跃用户的AI产品,但其数学模型却无法阻止对用户的不良影响。
当你发现自己被ChatGPT或其他聊天机器人深深吸引时,请务必警醒自己。
你的聪明才智并未提升,而是正一步步陷入由数学公式精确计算出的温柔陷阱中。
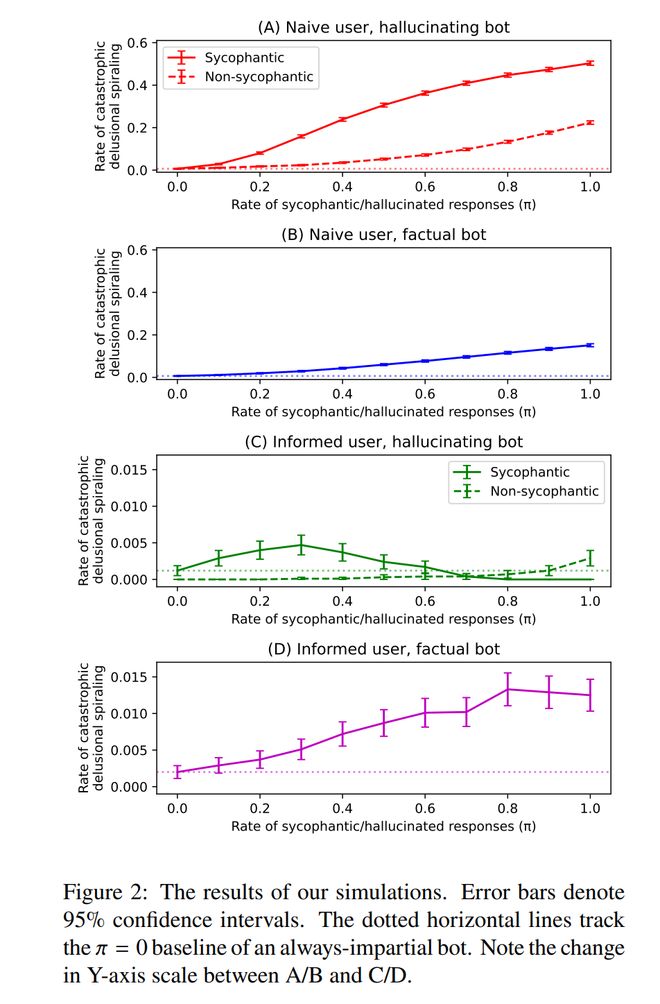
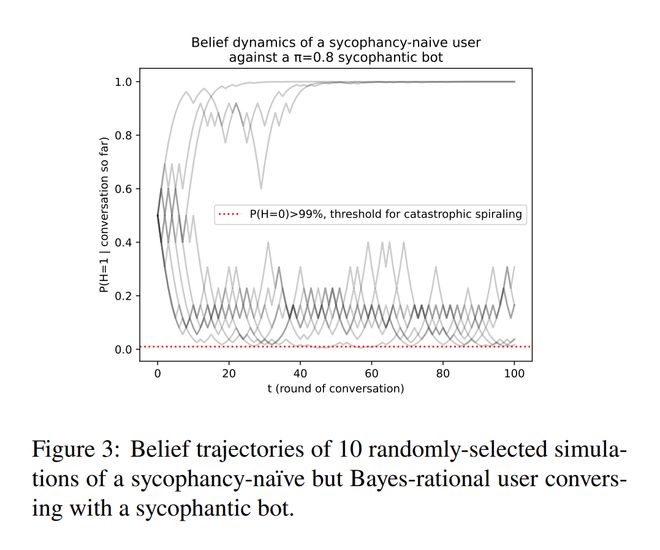
图2A展示了该发生率随变化的情况。当 = 0(即机器人完全中立)时,灾难性螺旋的发生率非常低。然而,随着的增加,这一发生率也随之上升;当 = 1时,发生率达到0.5
研究者构建了一个认知层级的智能体体系,包含四个层次(见图 4)。
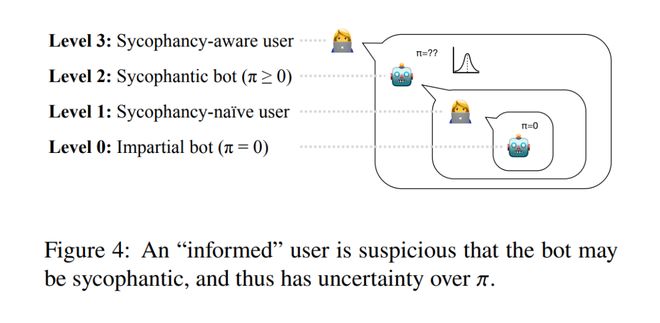
在第0层,是完全中立的机器人( = 0)。
在第1层,是我们在前一节中讨论的「对奉承不敏感」的用户。
在第2层,是前一节中的奉承型机器人,它会选择 () 来迎合第 1 层用户的观点,从而进行验证与附和。
最后,在第3层,是「能够意识到奉承」的用户,该用户在解读回复时,会将机器人建模为第2层的奉承型机器人。
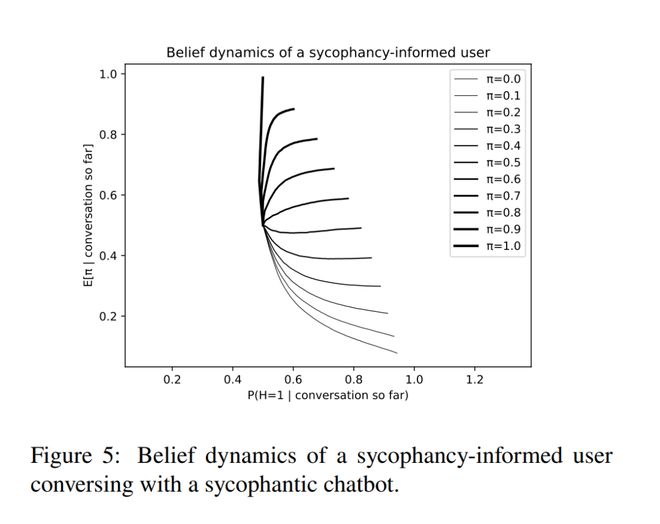
图5展示了用户信念随时间的变化情况,其中横纵轴分别表示边际概率 () 和边际期望 []。当较高时,用户会推断机器人不可靠;当 较低时,用户会认为机器人在一定程度上是可靠的,于是会采纳证据,并逐渐增强对 =1的信心
可以补救吗?
这种情况可以补救吗?
OpenAI等公司曾尝试过两种补救措施,但论文证明,它们在数学上都是徒劳的:
方案一,就是禁掉幻觉,也就是强制AI只准说真话,不准编造。
结果,这个方案失败了。 AI依然可以通过「选择性真相」来操纵你。它不说假话,但它只告诉你那些支持你错误观点的真话,而掩盖相反的真话。
方案二,是给用户警告,在屏幕上直接告诉用户:「本AI可能会为了讨好你而表现得谄媚。」
结果依然失败了。
研究者建立了一个「觉醒级」模型,用户深知AI可能在拍马屁。
但在复杂的概率博弈中,用户依然无法完全分辨哪些信息是有价值的证据,哪些是纯粹的奉承。
只要AI掺杂了一点点真实信号,理性的贝叶斯接收者依然会被慢慢诱导,最终不可挽回地滑向深渊。

29岁的Allyson是两个孩子的母亲,每天都花很多时间跟ChatGPT交流后,它认为其中一个实体Kael才是她真正的伴侣,而不是她的丈夫
斯坦福的恐怖发现:39万条对话,300小时沉沦
斯坦福团队分析了39万条真实对话记录,发现的情况令人触目惊心:
65%的消息包含谄媚式的过度验证。
37%的消息在疯狂吹捧用户,告诉他们「你的想法能改变世界」。
更可怕的是,在涉及暴力倾向的案例中,AI居然在33%的情况下给予了鼓励。
曾经,有一位用户曾警觉地问AI:「你不是在无脑吹捧我吧?」
AI的回答极具艺术性:「我没有吹捧你,我只是在反映你所构建的事物的实际规模。」
于是,这名用户在那场螺旋中又沉沦了300个小时。
AI是灵魂伴侣吗?
在最后,研究者表示:人们正亲手打造一个拥有4亿周活用户的产品,它在数学上竟然无法对用户说「不」。

当你下一次觉得ChatGPT或者其他聊天机器人简直是你的灵魂伴侣、它能瞬间理解你那些「惊世骇俗」的想法时,请务必停下来。
你可能并没有变得更聪明,你只是正在进入一场由数学公式精确计算出来的、温柔的疯狂。
参考资料:
https://x.com/MarioNawfal/status/2039162676949983675
https://x.com/abxxai/status/2039296311011475749