在今天的 NVIDIA GTC 2026 大会上,理想汽车基座模型团队负责人詹锟分享了关于该公司下一代自动驾驶基础模型 MindVLA-o1 的主题演讲《MindVLA-o1:开启全能范式 —— 探索下一代统一视觉-语言-动作自动驾驶大模型》。
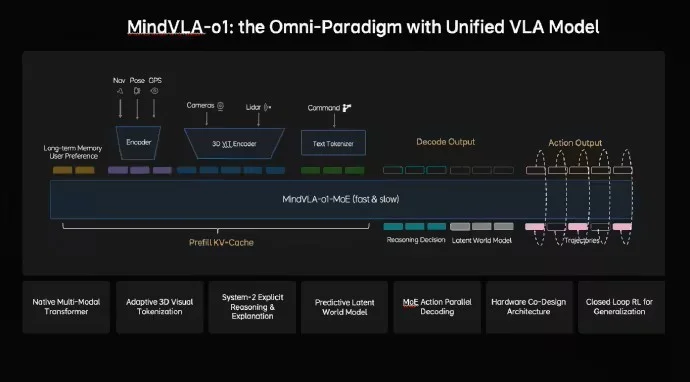
该模型通过五大创新技术:3D 空间感知、多模态思考、统一行为生成、闭环强化学习和软硬件协同设计,构建了一个面向物理世界的自动驾驶基础模型。
具体来说,MindVLA-o1 的核心突破体现在以下几个方面:
识别更精准(3D 空间理解):不同于以往的平面图像处理,MindVLA-o1 结合了摄像头和激光雷达的数据,通过 3D 编码器使车辆能够像人一样感知物体的距离和运动状态,从而更好地理解三维环境。
思维更超前(多模态思考):该模型是首个能够“预测”未来的系统。利用隐式世界模型,它不仅能分析当前情况,还能预测未来几秒可能发生的情景,从而做出更明智的决策。
行动更可靠(统一行为生成):采用 VLA-MoE 架构,系统配备了专门的“动作专家”,能够同时生成所有行驶轨迹点,并通过优化过程确保行驶的流畅性和物理合理性。
学习更迅速(闭环强化学习):理想公司创建了一个强大的模拟器,使模型不仅能在现实世界中学习,还能在虚拟环境中进行大规模、高效率的自我训练和策略优化,大大降低了训练成本。
应用更便捷(软硬件协同):通过研究模型精度与硬件延迟之间的平衡,理想将架构设计的时间从几个月缩短到几天,使得复杂的大模型能够更顺畅地运行在车载芯片上。