
新智元报道
最近,Meta和METR最新发布的AI进展数据与中国团队两年前提出的一项理论不谋而合。
在过去的几天里,全球三大权威的人工智能研究机构几乎同时得出了相似的研究成果。
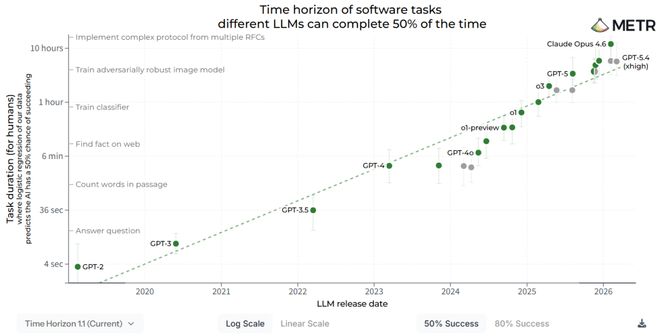
4月3日,美国的METR发布了最新的技术报告,得出的主要结论是简短明确的。
AI的能力每隔88.6天就会翻一番。
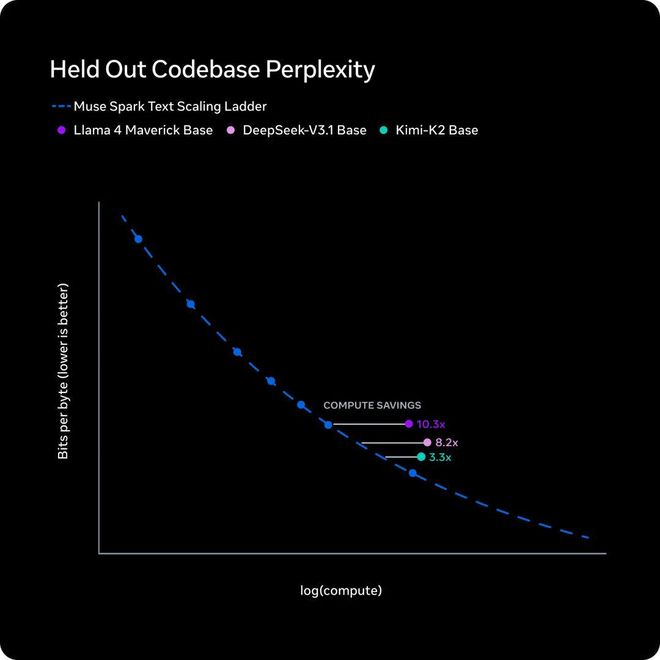
五天后,即4月8日,Meta超级智能实验室推出了名为Muse Spark的新模型,并公布了一条内部称为scaling ladder的训练效率曲线。
新模型比一年前发布的Llama 4 Maverick性能相近,但所需的训练算力却减少了十分之一。
这两家机构的研究方法完全不同,且彼此之间没有交流。
当将这两项研究结果转换为同一坐标系统时,它们的斜率几乎一致。
到这里已经相当令人惊讶了,但这还远远不够。
更让人震惊的是,这个结论早在两年前就被一个中国团队完整地提出并发表在Nature子刊上。
它叫密度定律。
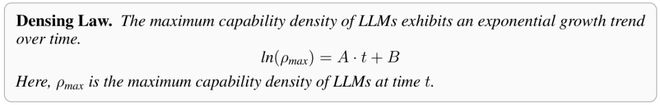
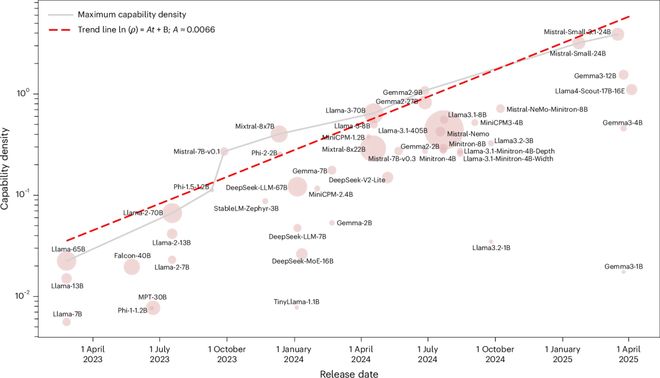
两年之前就已经有人画出了这条曲线。
这一概念最早出现在一篇名为「Densing Law of LLMs」的论文中。
论文由面壁智能与清华大学联合发布,孙茂松和刘知远两位教授是主要作者,博士生肖朝军为第一作者。
该论文于2024年12月上传至arXiv,并在次年的11月被Nature Machine Intelligence接受发表。

论文的核心观点简明扼要。

模型智能密度随时间呈指数级增强,达到特定性能水平所需的参数量每3.5个月减半。
在2024年底时,这一说法可能显得过于激进。
当时整个行业都在追求scaling law,OpenAI、Anthropic和Meta等都纷纷加大投入以提升模型规模。
所有人都认为参数越大智能越强,将GPU性能推至极限才是正道。
他们对当时所有重要的开源基础模型进行了全面评估,从Llama-1到Gemma-2、MiniCPM-3等共51个模型。
在五大基准测试下,结果显示几乎完美的指数关系,R²值高达0.934。
但研究团队不这么看。
鉴于大型模型的评测容易受到数据污染的影响,他们使用一个新构建的数据集MMLU-CF进行了重新评估。结果R²值为0.953。
这两次拟合都接近1的R²值,几乎不可能是巧合。
换句话说,这两年发布的所有主流开源模型,不论来自哪个团队或使用何种架构,都在同一条「每3.5个月翻倍」的指数线上。
到这里为止,故事仅仅是关于一个中国团队提出了一条看似激进的经验规律。
真正让这件事成为关键时刻的是接下来半年内发生的事。
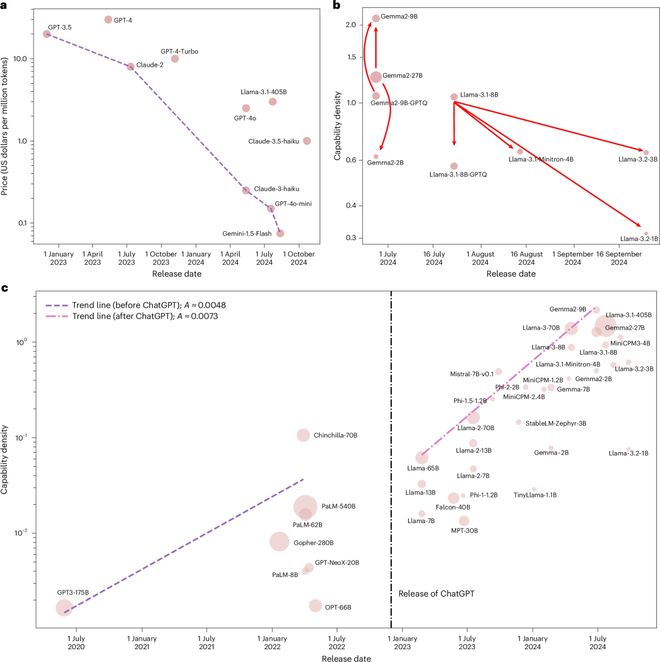
三个机构、三种方法、同一个斜率
对比面壁智能、Meta和METR三家的结论。
面壁智能的研究关注的是达到相同性能水平所需的参数量,得出的结果是每3.5个月减半。
Meta的scaling ladder评估的是达到特定性能所需训练算力的节省情况,Muse Spark相比一年前的模型节省了一个数量级的计算资源。
- METR则研究了模型完成任务的时间长度,发现同样的模型能解决的任务时长每88.6天翻倍。
- 这一点值得注意的是密度定律是最早提出的一项理论。它比Meta的scaling ladder早了近两年,比METR的研究也领先了一年多。
- 什么样的观察才配得上「定律」的称谓?
这不是看数据有多么漂亮,而是要看它能否在多个独立测量系统中一致成立。
摩尔定律之所以被称为定律是因为半导体行业从不同维度多次验证了它的正确性。
密度定律遵循同样的路径。
它最初只是一个单一团队提出的拟合曲线,到被Nature子刊接受时已经能够在过滤后的数据集中重现结果。现在它在Meta和METR的独立验证中再次得到证实。
放在一个更大的历史坐标系来看,这一刻与电力刚进入纽约时期的情况极为相似。
那个时代几个不同的发明家、工程师以及城市各自建设电网。直到有人将所有项目的发展曲线绘制成一张图表时,人们才意识到这不是零散的工程进步,而是一个新时代正在悄悄开启。
不过这一次,从论文发表到被广泛认可仅用了两年时间。
这三个关键点表明大模型行业的最优策略可能已经开始转变。
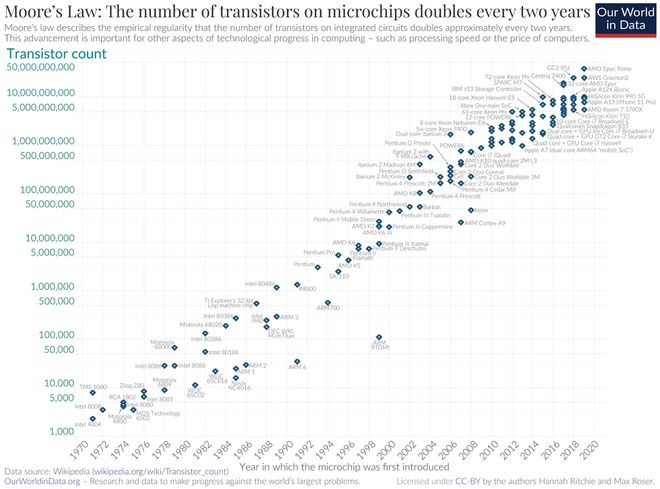
过去三年里,行业对scaling law的理解一直停留在「堆参数、堆数据」上。
但密度定律提出了一种与直觉相悖的观点,在智能密度持续指数增长的前提下,任何状态的最强模型都只有几个月的有效期。
投入大量资源去训练一个更大的模型然后等待三个月被体积更小的新模型超越在经济上是不可行的。
可持续的发展道路应该是集中精力提升密度本身的质量。更好的架构、更高品质的数据和更聪明的训练算法才是关键。
面壁智能一直在沿着自己设定的方向前进
值得一提的是,密度定律不仅仅是一篇发表论文。
提出这一理论框架的面壁智能在过去两年中一直利用自家的MiniCPM系列模型进行验证。
MiniCPM-1-2.4B在发布时性能就能与几个月前发布的更大规模模型相当。也就是说,四个月的时间,35%的参数量达到了同等水平。
这个案例直接被写入了Nature子刊论文中作为密度定律的第一个实证证据。
自此之后,小钢炮系列一路开源,在文本、多模态、语音和全模态等多个方向上都有所覆盖。在国内除了阿里之外只有面壁智能做到了这一程度的开源完整度。
目前为止,该系列在全球的下载量已经超过2400万次。
尽管这不是行业内最大的模型,但它却是第一个将「密度优先」作为公司方法论来执行的团队。
当Meta和METR在2026年四月用各自的方式验证密度定律时,这家从2024年开始就按照这种方法训练模型的中国公司已经积累了两年的工程经验。
这一次,中国研究者站在了新曲线的起点上
一个由中国团队提出的理论框架正在被Meta和METR等海外最权威的研究机构用不同方式重新发现。
这件事的重要性可能需要一些时间才能完全理解。
它不是一个「我们也行」的故事,而是一个「我们更早一点看见」的故事。
在科学史上这样的瞬间并不多见。一个在2024年被怀疑的判断,在两年后变成了多个独立证据指向同一条曲线。
这种跨地域、跨方法和跨机构的一致性在过去物理学中仅发生过几次,每一次都标志着旧范式的结束以及新范式的开始。
中国AI研究者这次站在了这一转折点上。
而这条曲线仍然在以每88天翻一倍的速度持续上升。
面壁智能首创的「密度定律」,获得了包括Meta在内的海外顶级机构的认可。
https://arxiv.org/abs/2412.04315
https://www.nature.com/articles/s42256-025-01137-0
https://metr.org/blog/2026-1-29-time-horizon-1-1/
https://ai.meta.com/blog/introducing-muse-spark-msl/
面壁智能的「密度定律」正在获得国际上的广泛认可。
这个数字被直接写进了Nature子刊那篇论文里,作为密度定律的第一个实证案例。
从那之后,小钢炮系列一路开源,覆盖10B以下参数的文本、多模态、语音、全模态四大方向。这个开源完整度,在国内除了阿里之外,只有面壁一家做到。
到目前为止,小钢炮系列在全球的开源下载量已经突破2400万次。
它不是行业里最大的模型。但它是行业里第一个把「密度优先」当作公司方法论来执行的团队。
而当Meta和METR在2026年4月这一周用各自的方式验证密度定律时,这家2024年就开始按这套方法论训练模型的中国公司,其实已经领先了两年的工程经验。
这一次,中国研究者站在了曲线的起点
一个中国研究团队两年前提出的理论框架,正在被Meta、METR这些海外最严肃的机构,用他们各自的方式,一次次重新发现。
这件事的份量,可能需要一点时间才能完全理解。
它不是一个「我们也行」的故事。它是一个「我们更早一点看见」的故事。
科学史上这样的瞬间不算多。一个在2024年被怀疑的判断,在2026年变成了多个独立证据指向的同一条曲线。
这种跨地域、跨方法、跨机构的「不约而同」,在物理学里发生过几次,每一次都标志着一个旧范式的终结和一个新范式的开始。
中国AI研究者这一次站在了那个起点上。
而那条曲线,还在以每88天翻一倍的速度往上走。
参考资料:
面壁智能首创的「密度定律」,获 Meta 等海外顶级机构认可
https://arxiv.org/abs/2412.04315
https://www.nature.com/articles/s42256-025-01137-0
https://metr.org/blog/2026-1-29-time-horizon-1-1/
https://ai.meta.com/blog/introducing-muse-spark-msl/