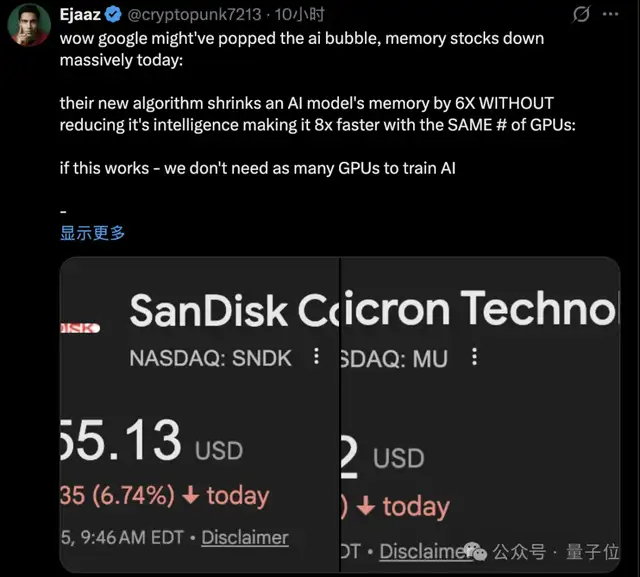
最近,谷歌的一项研究导致内存相关股票大跌,其KV cache压缩技术将内存使用量减少了6倍。
 梦晨
梦晨内存啥时候降价
据报道,此次市场波动与即将在2026年召开的ICLR会议上谷歌展示的一篇论文有关。
这一消息让市场反应强烈,认为这对内存股来说是个负面消息,因为未来的AI推理可能不需要这么多内存。
很多网友对此表示惊讶,称其为美剧《硅谷》中虚构创业公司Pied Piper的现实版。
在这部电视剧中,Pied Piper开发了一种“近乎无损的极限压缩算法”,这在当时被认为是科幻。
现在,类似的算法正在现实中取得突破。

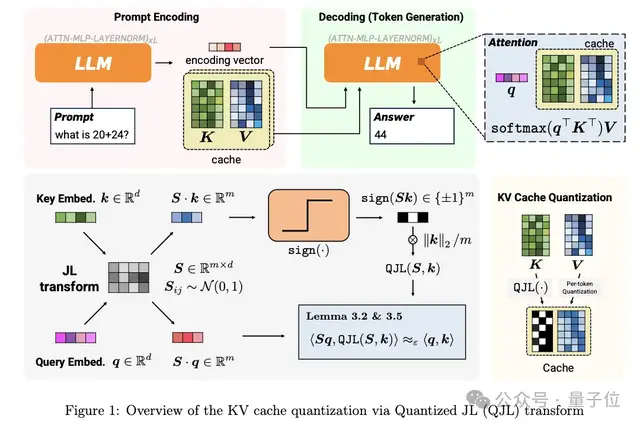
KV cache的量化到3 bit是这一算法的关键。
为了理解TurboQuant的重要性,我们需要先了解它解决的问题。
在AI大模型推理过程中,处理过的数据会暂时存储在KV cache中,以便后续快速调用。
然而,随着上下文窗口的增加,内存消耗会急剧增加,KV cache成为了推理过程中的一个重要瓶颈。
传统的解决方案是通过向量量化来减少内存使用,但这通常需要额外存储量化常数,增加了内存开销。
TurboQuant通过创新性的设计,彻底解决了这个问题。
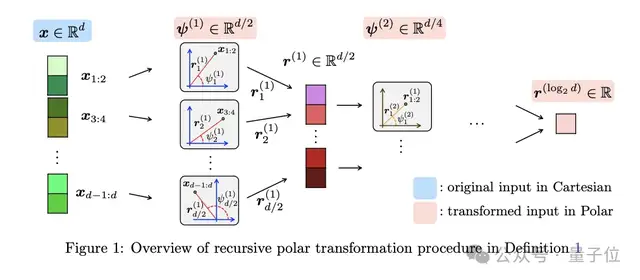
其中一项创新是PolarQuant,它使用极坐标而非传统的XYZ坐标来描述数据。
实验显示,转换后的角度分布十分集中,因此可以省去存储归一化常数的步骤。
例如,将“向东走3个路口,向北走4个路口”简化为“朝37度方向走5个路口”,信息量不变,但描述更为紧凑。
另一项技术是QJL,它将高维数据投影后压缩成+1或-1的符号位,无需额外内存。
TurboQuant结合这两项技术,实现了3-bit量化,同时保持了零精度损失。
在一系列基准测试中,TurboQuant不仅减少了KV cache的内存占用,还在性能上超越了现有方法。
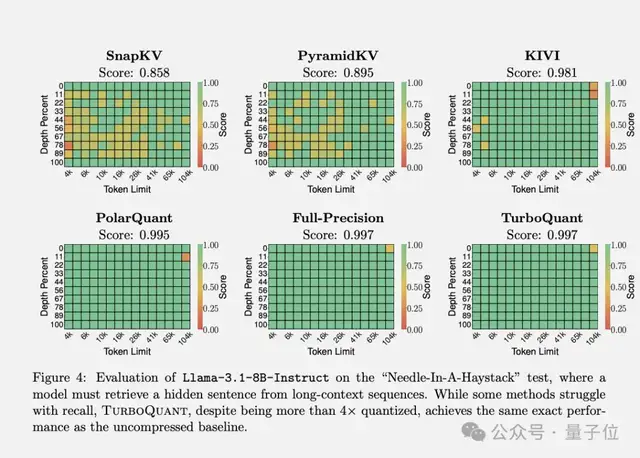
在“大海捞针”任务中,TurboQuant在所有测试中均获得了满分,内存占用减少了至少6倍。
单独使用PolarQuant时,精度几乎不受影响。
而且,TurboQuant在速度上也有显著提升,在英伟达H100 GPU上,4-bit TurboQuant比32-bit未量化版本快了8倍。
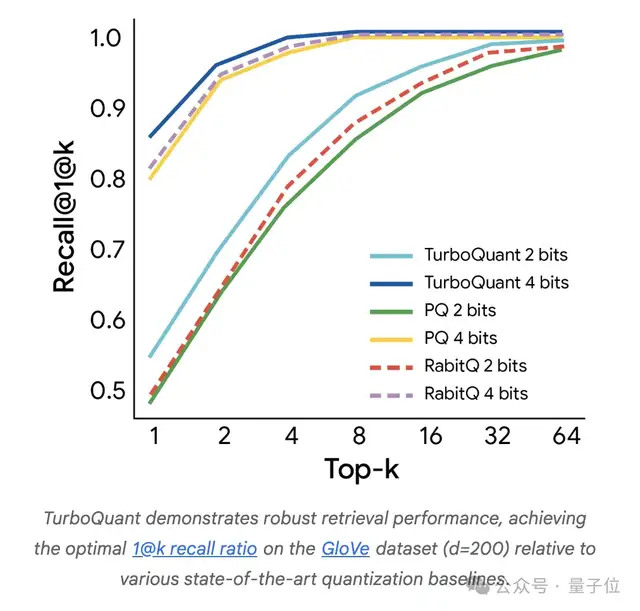
在向量搜索领域,TurboQuant也超过了现有最佳量化方法,并且不需要特定的数据集优化或依赖低效的大码本。
Cloudflare CEO认为这是谷歌的DeepSeek时刻,意味着用更少资源可以训练出顶尖模型。
TurboQuant的方向与此类似,即用更少的内存实现同样质量的推理。
谷歌表示,除了Gemini等大模型,TurboQuant还能显著提高语义搜索的效率,使大规模的向量索引查询更快速且成本更低。
尽管如此,TurboQuant目前仍处于实验室阶段,尚未大规模部署。
此外,该技术仅解决了推理阶段的内存问题,对AI训练阶段没有影响。
在“大海捞针”任务上,TurboQuant在所有测试中拿下完美分数,同时KV cache内存占用缩小了至少6倍。
PolarQuant单独使用,精度也几乎无损。
速度提升同样显著。在英伟达H100 GPU上,4-bit TurboQuant计算注意力分数的速度,比32-bit未量化版本快了8倍。
不只是省内存,还更快了。
在向量搜索领域,TurboQuant同样超越了现有最优量化方法的召回率,而且不需要针对具体数据集做调优,也不依赖低效的大码本。
AI内存的DeepSeek时刻?
Cloudflare CEO评价“这是谷歌的DeepSeek时刻”。
他认为DeepSeek证明了用更少的资源也能训出顶尖模型。
TurboQuant的方向类似,用更少的内存,也能跑同样质量的推理。
谷歌表示,TurboQuant除了可以用在Gemini等大模型上,同时还能大幅提升语义搜索的效率,让谷歌级别的万亿级向量索引查询更快、成本更低。
不过TurboQuant目前还只是一个实验室成果,尚未大规模部署。
更关键的是,它只解决推理阶段的内存问题。而AI训练环节完全不受影响。
论文地址:
https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/
参考链接:
[1]https://x.com/eastdakota/status/2036827179150168182?s=20