
在 40K 上下文限制内,让 Agent 搜索超过 2048 轮且性能不减,这在目前看来是难以实现的。
目前流行的 Search Agent 都面临同样的问题:它们需要多次搜索网页、对比线索、验证假设并修正路径。然而,以 ReAct 为代表的传统方法将每轮思考和工具返回的结果叠加到同一个上下文中——这样做不仅使上下文变得臃肿,还减少了后续推理的空间,并永久地保留了早期的错误信息。
这样一来,Agent 越深入搜索就越难以清晰思考。
是否可以设计一个机制让 Agent 在探索过程中不断清理其思维空间?
中国人民大学与阿里巴巴通义实验室的研究团队提出了 IterResearch,一种全新的迭代式深度研究方法。
利用马尔可夫决策过程的工作空间重构技术,IterResearch 让 Agent 能够在仅有 40K 上下文长度的情况下完成 2048 次工具交互且性能不下降,在 BrowseComp 数据集上的准确率从 3.5% 提升至 42.5%。
这项研究已被 ICLR 2026 接收。

- 目前,该论文已经被接收并发表在 ICLR 会议上。
- 研究团队提供的代码可在 GitHub 上找到。
「增加上下文」为何难以实现交互扩展?
在 Search Agent 中,Agent 的工作本质上是一个与外部环境不断互动的过程。传统 ReAct 方法将此过程建模为「单一上下文累加」:每一轮的推理和工具返回结果都被追加到同一个上下文中,形成线性增长的记忆链。
这种看似自然的设计,在处理长时间任务时会导致两个主要问题:
- 一是上下文窒息(context suffocation):由于上下文窗口容量有限,历史信息不断堆积会压缩后续推理的空间。Agent 被迫给出简短且肤浅的回答,最终导致错误的结论;
- 其二是噪声污染(noise contamination):搜索过程中产生的大量网页摘要、早期的错误路径和无关线索被永久写入上下文,对后续推理产生干扰,信噪比逐渐下降。
当前社区已经意识到这些问题,并提出了 context folding 和 summary 等缓解措施。然而这些方法本质上是在修补问题,没有改变线性增长的上下文结构 —— 即便给 Agent 更大的上下文窗口,也只能延缓崩溃而非避免。
不再「累加」而是「重建」:IterResearch 的核心思想
IterResearch 的解决方案不是修补现有方法中的缺陷,而是从范式层面重新思考问题。与其不断往上下文中添加信息,不如让 Agent 学会「边做边清理」。
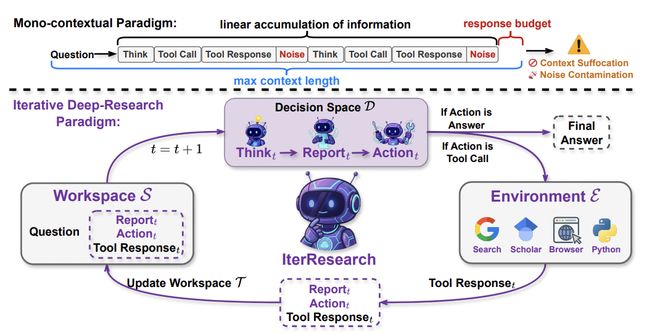
研究团队将长程研究过程描述为一个马尔可夫决策过程(MDP)。核心思想是:Agent 不再维护一个不断增加的历史记录,而是通过一个持续更新的「演进报告」来总结已有成果、压缩无关信息并更新推理状态。每一轮推理都在一个重构过的、固定复杂度的工作空间中进行。
具体来说,每个步骤包含两个核心动作:
- 决策阶段:Agent 根据当前情况输出三部分 —— 思考过程(Think)、更新后的演进报告(Report)和本次工具调用请求(Action)。报告在此处扮演了「压缩记忆」的角色,Agent 需要在每一轮中决定哪些信息需要保留,哪些可以丢弃。
- 状态转移阶段:进入下一轮时,完整的历史轨迹被有意舍去,仅保留更新后的报告、上轮的工具调用及其返回结果,三者共同构成新的推理起点。
从上下文管理的角度看,传统 ReAct 的状态空间随交互轮次 t 线性增长(O (t)),而 IterResearch 的工作空间始终保持固定大小(O (1))。
研究团队指出,这种机制与 RNN/LSTM 中的隐状态更新有结构上的相似性 —— 都通过一个隐状态来承载记忆并逐步更新。不同之处在于,IterResearch 的「隐状态」是一份显式且可解释的研究报告,既能浓缩历史又能为下一步推理提供清晰起点。
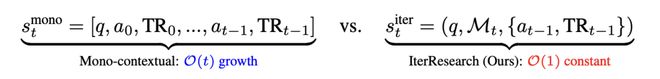
40K 上下文,2048 轮交互不退化:交互扩展的威力
这项研究最核心的发现是 Interaction Scaling 特性 —— 给 Agent 更多交互预算可以让性能持续提升,而不会像传统方法那样因上下文溢出而导致崩溃。
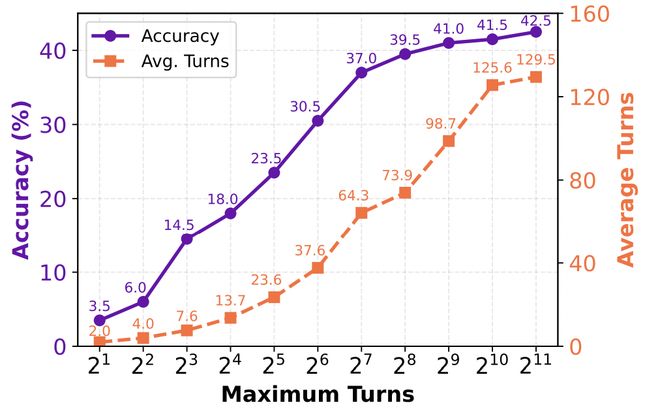
在 BrowseComp 基准上,团队逐步将最大交互轮次从 2 扩展到 2048。结果显示,IterResearch 的准确率从 3.5% 提升至 42.5%,且在 2048 轮时未见明显的性能下降迹象。而传统单上下文方法早在几十轮后就已不堪重负。
需要强调的是,2048 并非 IterResearch 的上限,仅是实验范围的终点。模型在 2048 轮时依然保持上升趋势,表明该范式具备进一步扩展的能力。
这一结果暗示了长程任务的挑战性可能不完全来自于推理能力不足,更可能是探索深度受限。当 Agent 拥有干净的思维空间并被允许充分探索时,它确实能够在超长时间的任务中持续进步。
另一个有趣的发现是:尽管最大轮次设定为 2048,Agent 平均只用了约 80 轮就完成了任务。这表明 Agent 学会了在获取足够信息后主动终止搜索 —— 这说明它不仅学会了「走得远」还学会了「知道何时停」。
「即插即用」的推理方法:无需训练即可提升闭源模型
如果仅将 IterResearch 的迭代逻辑作为提示策略直接应用于闭源模型,效果如何?
研究团队在 o3 和 DeepSeek-V3.1 上进行了测试。在完全相同任务设定下,与传统的 ReAct 方法相比,IterResearch 在最具挑战性的 BrowseComp 数据集上分别为 o3 提升了 12.7%,为 DeepSeek-V3.1 提升了 19.2%。
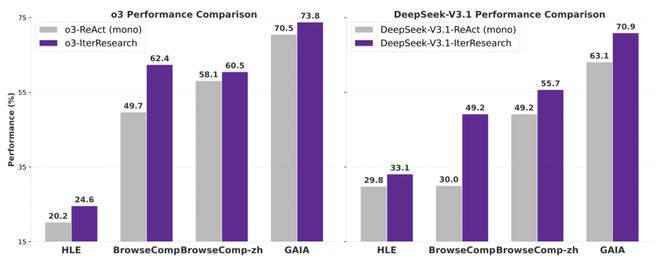
这表明 IterResearch 的优势在于其结构化的认知机制,而非依赖特定数据或微调技巧。无论底层模型架构如何,它触及的都是长程推理中的共性瓶颈。
总结
IterResearch 实现了一种简洁而有效的范式转变:与其不断修补注定会崩溃的线性上下文,不如从结构上让 Agent 学会「边做边重构思维」。
这一思路在训练框架、提示策略和跨范式迁移三个层面都展现了一致的有效性。其揭示的 Interaction Scaling 特性更是为长程 Agent 的能力边界开辟了新的想象空间,在 Agent 走向长期持续运行的过程中,IterResearch 提供了一个值得关注的方向。
作者介绍
该研究的第一作者陈国鑫是中国人民大学高瓴人工智能学院的一名博士生,他的导师是赵鑫教授和宋睿华教授。他专注于 LLM 推理与 Agent 研究,特别是在搜索智能体和代码智能体领域。他曾在中国阿里巴巴通义实验室等机构实习,并在 ICLR、ICML、NeurIPS 和 ACL 等顶级会议上发表过论文。这项工作是由中国人民大学与中国阿里巴巴通义实验室共同完成的。