 百度近期正式向公众开放了其文心大模型团队开发的ERNIE-Image图形生成系统,该系统的参数规模仅为8B,在仅需24GB显存的消费级GPU上就能运行。
百度近期正式向公众开放了其文心大模型团队开发的ERNIE-Image图形生成系统,该系统的参数规模仅为8B,在仅需24GB显存的消费级GPU上就能运行。
在多个国际评估标准中,ERNIE-Image表现出色,在GenEval、OneIG等关键测试中的综合得分均列开源模型之首。尤其在文字渲染方面,其性能与Nano Banana等商业闭源系统处于同一水平线上。
此外,团队还同时发布了ERNIE-Image-Turbo版本,该版本将推理步骤从标准版的50步压缩到了仅需8步完成。
目前这两个模型的相关代码和权重文件都已经上传至Hugging Face平台,并遵循Apache 2.0许可协议。与此同时,ComfyUI工作流模板也已上线,同时还有一套由Unsloth提供的开源量化方案支持GGUF格式的转换优化。
ERNIE-Image采用了单向Diffusion Transformer架构,并集成了提示词增强模块(Prompt Enhancer),能够将简短的文字输入扩展为详细的描述后进行生成处理,从而提高指令的理解能力和图像细节控制水平。
该模型的GitHub页面已经获得了78个点赞支持。
经过一系列复杂任务的实际测试显示,ERNIE-Image-Turbo在多物体布局、图表生成和光影效果等方面表现稳定。然而,在处理涉及复杂文字或多种语言的内容时,仍然存在一些识别错误的问题。
技术详情:https://ernie.baidu.com/blog/zh/posts/ernie-image/
体验平台入口:https://aistudio.baidu.com/ernieimage
Hugging Face资源链接:https://huggingface.co/baidu/ERNIE-Image https://huggingface.co/baidu/ERNIE-Image-Turbo
在六组高难度提示词测试中,模型在多主体空间控制和图表生成方面表现出色。
我们使用了包含多种语言、复杂文字渲染、漫画分镜叙事等六个维度的提示词对ERINE-Image-Turbo进行了全面评估。所有结果均为一次性生成,未经任何筛选或修改。
总体来看,在处理多主体空间关系控制和数据图表生成时,模型表现出色;但在遇到复杂的文字渲染任务时,则出现了一些预期之外的问题。
在首个测试中,ERNIE-Image未能准确地将生僻汉字“鬱”进行正确的图像绘制。
第二项是关于多语言混排的挑战。虽然在视觉呈现上基本符合要求,但仔细观察可以发现,“Knowledge”一词缺少了一个字母,并且韩文也存在偏差。
当测试难度进一步提升到极小字体清晰显示时,图像中出现了乱码、字符变形等问题,未能完整还原指定的技术参数和评测数据。
在漫画分镜的实验里,模型展示了较好的布局能力,但角色位置却发生了错误。原本设定的学生举手提问变成了教授在问问题,并且对话框也跟着改变方向。

数据图表生成方面,ERNIE-Image表现良好,在表头、颜色和标签等细节上都准确无误。
多主体空间控制测试中,模型能够严格按照指令放置七个物品的位置、尺寸及遮挡关系。所有指定的物体都在正确的场景内出现且位置排列得当。

最后一组实验是关于光线处理能力,ERNIE-Image严格遵守了伦勃朗布光的要求,展现了出色的光影控制技能。

在国际基准评测中,ERNIE-Image在GenEval、OneIG和LongText-Bench等重要评估指标上均表现出色,在文字渲染方面更是名列前茅。
GenEval测试显示,ERNIE-Image以0.8856的成绩位居榜首。而在OneIG的英文和中文榜单中,虽然得分稍逊于Nano Banana 2.0,但仍保持在前三的位置,并且在推理维度单项成绩上领先其他开源模型。
针对LongText-Bench评测,ERNIE-Image在两个语言方向上均取得了优秀的结果,在所有开源模型中独占鳌头。

ERNIE-Image的核心优势在于其轻量级架构和较低的部署门槛。仅需8B参数规模即可运行于消费级GPU设备之上,这使得它适用于个人创作者或小型团队进行本地部署,无需额外购买专业硬件支持。
在调用方式上,标准版ERNIE-Image采用50步推理流程,而Turbo版本则通过优化降至仅需8步完成,并且在保持性能的同时提升了速度。
为了便于用户使用和开发人员进行微调训练,百度提供了多种集成方案,包括直接通过Python代码调用以及部署到服务端等多种方式。此外还支持将PE模块单独剥离运行以加快提示词扩展速度,适用于延迟敏感的应用场景。
总结来看,ERNIE-Image在现有文生图技术的基础上实现了显著的进步,在保证高质量图像生成的同时,进一步增强了模型的可控性和灵活性。
这组测试要求该模型严格控制七个物品的位置、尺寸、遮挡关系,在一张写实俯拍桌面照里把它们放对地方。
这是六组里最让人满意的一组,七个指定物品全部按要求出现,且核心位置关系没有乱:翻开的精装书在画面正中,左页手写批注“此处存疑”、右页英文印刷句都清晰可读;黑色细框眼镜压在书本左上角;白色陶瓷咖啡杯在书本右侧,心形拉花形态自然;一元人民币硬币在咖啡杯右侧;黄色便利贴贴于书本正下方,手写“deadline:4月20日”内容准确;钢笔放在桌面左下角,笔尖朝向书本,全程无人物入镜。空间逻辑自洽,没有出现物品叠错或位置串行的情况。

6、伦勃朗布光,光影执行到位
最后一组想测的是,在给出高度具体的光影、材质和色彩指令后,该模型会不会自行简化内容。
结果是,该模型严格执行了指令:画面采用伦勃朗布光,主光来自左上方45度角,右侧脸颊的三角形光斑清晰可辨,轮廓规整;右侧完全无补光,仅靠少量环境反光勾出轮廓;背景纯黑,无纹理;肤质写实,毛孔可见,无磨皮痕迹;深色高领毛衣领口处的编织纹理也还原出来了。
二、国际基准评测成绩单,文字渲染在开源模型里拿第一
百度在三个国际公开基准上对ERNIE-Image进行了系统评测,分别是衡量通用图像生成能力的GenEval、覆盖中英文双语场景的OneIG,以及专门测试高密度文字渲染的LongText-Bench。
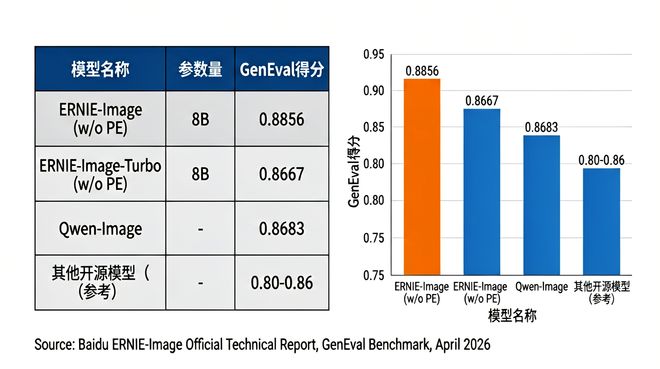
在衡量通用图像生成能力的GenEval测试中,ERNIE-Image(不启用PE)综合得分为0.8856,在所有参测模型中排名第一,超过Qwen-Image(0.8683)和FLUX.2-klein-9B(0.8481)。
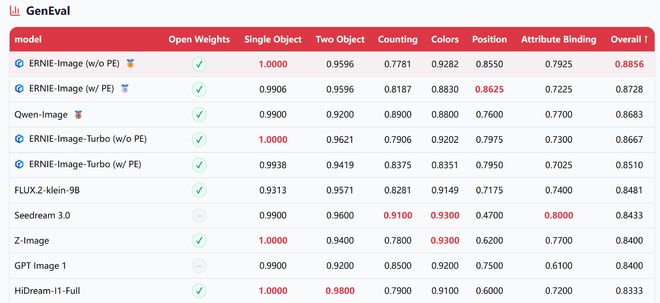
▲GenEval专业文生图模型评测基准(图源:百度ERNIE-Image技术报告)
OneIG英文榜上,ERNIE-Image开启PE后综合得分0.5750,仅次于Nano Banana 2.0(0.5780)和Seedream 4.5(0.5760),位列第三,同时在推理维度单项排名第一(0.3566)。
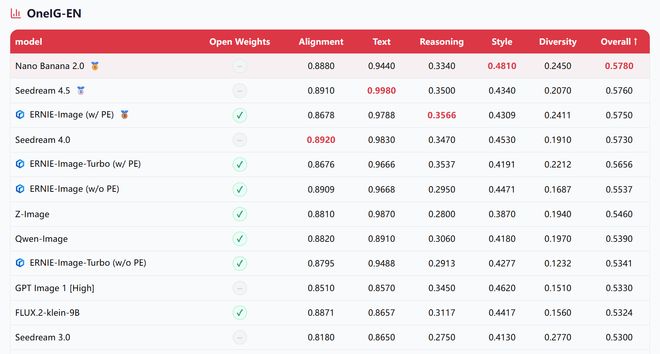
▲OneIG-EN,评估文生图模型在英文提示词场景下综合生成能力的量化评测体系(图源:百度ERNIE-Image技术报告)
中文榜上,ERNIE-Image开启PE的综合得分为0.5543,同样位列前两名仅次于Nano Banana 2.0,还在多样性维度上跑出了0.2478的最高分。
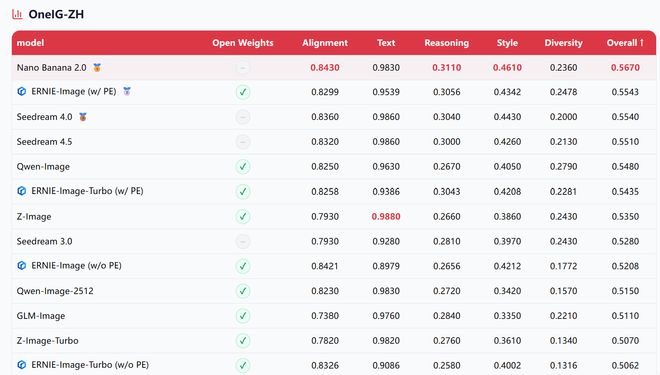
▲OneIG-ZW,评估文生图模型在中文提示词场景下综合生成能力的量化评测体系(图源:百度ERNIE-Image技术报告)
文字渲染专项LongText-Bench是最能体现ERNIE-Image差异化能力的榜单。英文维度上,ERNIE-Image开启PE得分0.9804,中文维度0.9661,综合均分0.9733,在所有开源模型中排名第一。对比来看,Nano Banana 2.0综合均分0.9650,Qwen-Image为0.9445,Z-Image为0.9355。
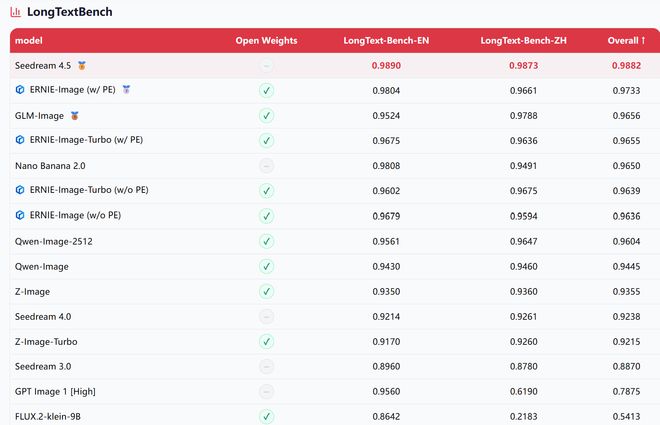
▲LongText-Bench,专业文生图长文本评测基准(图源:百度ERNIE-Image技术报告)
三、架构轻量、部署门槛低,8B参数跑进商用模型射程
ERNIE-Image的核心架构是单流Diffusion Transformer(DiT),并内置一个轻量级提示词增强器Prompt Enhancer(PE)模块,负责将用户的简短文字输入自动扩展为更丰富、结构化的详细描述,再送入DiT主干生成图像。
该模型的参数规模仅8B,这在开源文生图领域属于中小体量,但百度称在参数效率优化上做了大量工作,使运行门槛降至24GB显存的消费级GPU,显著低于此前同精度水平模型的部署要求。对照部分大参数开源模型的运行需求,ERNIE-Image这一设计的意义在于,个人创作者和中小团队无需购置专业工作站即可本地部署。
两个模型版本在调用方式上有所区别:标准版ERNIE-Image推理步数为50步,CFG(分类器自由引导)值为4.0;Turbo版由DMD和强化学习联合优化,推理步数降至8步,CFG降至1.0,牺牲少量精度换取速度提升。
在工程部署上,百度同时提供了两种集成方案。第一种是通过Hugging Face的diffusers库直接调用,只需几行Python代码即可完成推理;第二种是通过推理框架SGLang部署服务端,并支持将PE模块单独剥离,用vLLM单独运行以加快提示词扩展速度,DiT主干与PE各占独立端口,适合对延迟敏感的线上场景。此外,AI-Toolkit已支持对ERNIE-Image进行微调训练,为有个性化需求的开发者提供了完整的训练-推理链路。
结语:文生图再进阶,从“能出图”走向“可控生成”
如果把文生图模型的发展拆开看,过去一段时间的进步主要集中在“画得更像”,但在复杂结构控制、规则执行和文本表达上一直不稳定。
此次ERNIE-Image的实测结果显示,多主体位置关系、图表结构、分镜布局和光影条件这类“强约束任务”已经可以较稳定完成。未来,谁能先解决文本与语义一致性问题,谁才更有可能真正进入设计、内容生产等高要求场景。