据快科技4月10日的消息,在3月底智谱公司发布了GLM-5.1大模型,该模型在编程能力方面的评分达到了45.3分,并声称仅比全球领先的Opus 4.6低2.6分。
不久前,GLM-5.1大模型正式向公众开放源代码,受到了开发者的广泛欢迎。最近,权威的人工智能评估平台LMArena(由百万用户参与盲测)更新了Code Arena的专项排名表,显示GLM-5.1在开源模型中位居第一,在全球所有模型中的排名为第三。
此外,除了榜单上的出色表现之外,根据智谱公司的说法,GLM-5.1不仅沿袭了前代模型卓越的开源编码能力,还在处理长程任务方面取得了重要进展,具体表现为:
- 在8小时内从无到有构建出Linux桌面系统。
- 通过655次迭代解决了向量数据库优化过程中的瓶颈问题。
- 完成了1000轮工具调用以优化真实的机器学习模型负载情况。
特别值得一提的是,在METR榜单的同级评估标准下,GLM-5.1是唯一一款能够持续工作8小时以上的开源模型,并且在全球范围内只有少数几个模型(包括Claude Opus 4.6)具备这一性能特点。
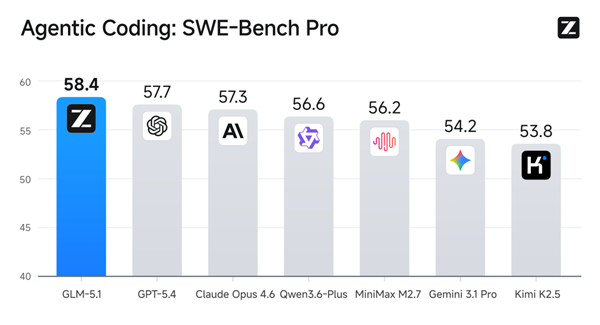
智谱公司早些时候提到,相较于其前身,GLM-5.1显著提升了代码编写能力,在应对长程任务时尤为突出。
在与真实软件开发环境最为接近的SWE-bench Pro基准测试中,GLM-5.1刷新了全球最佳成绩记录,超过了GPT-5.4和Claude Opus 4.6。SWE-Bench Pro评估模型是否能够在真实的GitHub仓库环境中识别并修复高难度的技术问题,是衡量一个模型能否胜任专业软件开发工作的关键指标。
