3月4日,谷歌宣布正式发布了Gemini 3.1 Flash-Lite版本,这款模型号称是速度最快的以及具有极高性价比的型号之一,特别适合开发者处理大规模和高吞吐量的工作负载需求,在同类产品中表现出卓越的质量。
自今日起,该新版本将通过Google AI Studio平台上的Gemini接口提供给开发者预览体验,并且也将通过Vertex AI面向企业用户提供服务。
Gemini 3.1 Flash-Lite的收费模式为每百万输入Token需支付0.25美元,输出Token则为每百万1.50美元。根据Artificial Analysis的基准测试显示,在同等或更高质量的前提下,其性能优于2.5 Flash版本,并且首次响应时间提高了两倍多,输出速度也增加了45%。谷歌强调,这种低延迟特性对于高频工作流至关重要,使其成为构建实时互动体验的理想选择。
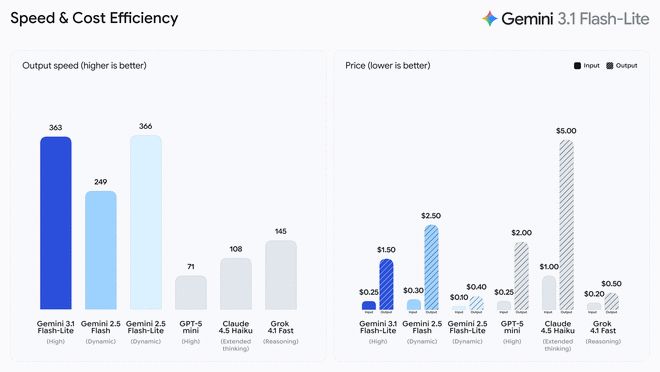
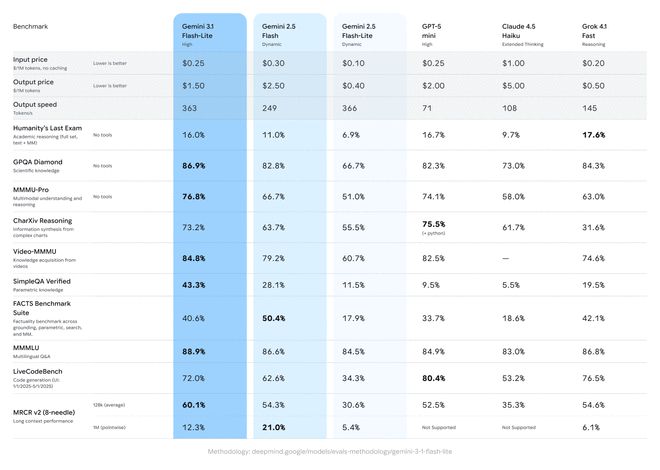
3.1 Flash-Lite在Arena.ai的评估中获得了高分——1432分,在推理和多模态理解测试中领先于同级别的其他模型。例如,在GPQA Diamond和MMMU Pro这两个基准测试中的得分分别为86.9%和76.8%,甚至超过了前几代规模更大的模型。
除了强大的原生性能,Gemini 3.1 Flash-Lite在AI Studio和Vertex AI中还包括了“思考等级”功能。这一特性使得开发者可以灵活调整模型的深度思考程度以适应特定任务需求,在管理大规模工作负载方面尤为重要。此外,这款新版本能够处理如翻译、内容审核等成本敏感的大批量任务,同时也适用于生成用户界面、创建模拟环境以及执行复杂指令等工作。
据悉,包括Latitude、Cartwheel和Whering在内的早期接入开发者已经在使用3.1 Flash-Lite来应对大规模的复杂挑战。这些测试者一致认为该模型在处理复杂输入时能够保持与大体量模型相当的准确度,并且严格遵循指令以保证一致性。
(本文由AI翻译,网易编辑负责校对)