国内的一款免费开源语音AI模型,成功模仿了郭德纲的名作《莽撞人》。
 十三
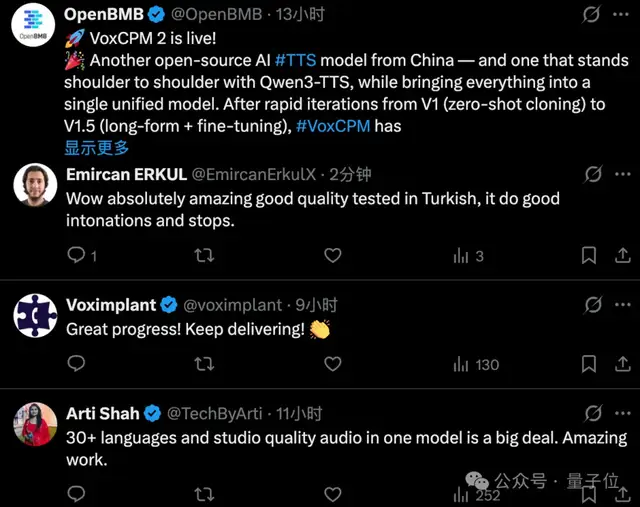
十三近期刚刚完成数亿元融资的企业面壁智能发布了其新研发的语音模型,得到了海外用户的高度评价。
该模型能够完美再现包括东北话在内的九种方言,并支持三十多种语言的转换。
这段话被认为是台词表演中的顶级难度,连专业演员都难以掌握。然而,这款新的语音模型不仅能够准确地再现其节奏和发音,还能够完美捕捉到其中的情感表达。
来,展示~

特别是对于郭德纲的贯口,《莽撞人》,该AI通过自行设计音色的方式成功还原了这段极具挑战性的表演内容。
除了《莽撞人》之外,这款模型还可以轻松复刻沈阳翻译的片段,并且能够模仿东北方言特有的发音和语气。
此外,这款语音生成器可以支持四川话、粤语等九种地方语言,甚至能够完美再现经典影片中的台词表演风格。
比如,在《大话西游》中,该模型能够用四川话准确传达周星驰原版配音的情感和特色。
同样地,这款AI还能够将中文的《甄嬛传》片段转换成韩语版本,并且在语气和人声上保留了原著的感觉。
除了方言和多语言支持外,VoxCPM 2在音色设计、可控性和表现力方面也表现出众。

国内开源社区OpenBMB与清华大学的人机语音交互实验室合作发布了这款模型的最新版本——VoxCPM 2。
这款免费开放的语音AI不仅能够生成逼真的音频,还可以在几秒钟内完成复杂的语言转换任务。
用户可以通过官方网站体验其功能,并尝试制作不同风格和语言的对话内容。
在使用过程中,用户可以上传参考音频、选择不同的方言或语言设定,甚至调整语速和情感表达方式。
除了基本的操作指南外,该模型还提供了一系列高级选项,比如文本规范化、降噪处理以及音色控制指令等。

此外,VoxCPM 2还在技术层面采用了一种不同于传统方法的创新路线——扩散自回归连续表示法。
这一设计使得语音转换过程中能够更好地保留原始声音的细节和情感特质,并且在处理方言时尤为出色。
面壁智能团队多年的技术积累,以及其自主研发的小模型技术壁垒,为这款高性能模型提供了坚实的基础。
从Hugging Face平台上的积极反馈来看,VoxCPM系列已经积累了大量用户和下载量,并且此次升级进一步提升了多项核心能力的表现水平。
同时,该团队还提供了一系列易于使用的工具链和服务支持,使这款模型的部署和使用变得更加简单便捷。
目前,在小模型领域内,中国企业正在展现出越来越强的实力与竞争力。

△图片和音频均为AI生成
视频地址:
https://mp.weixin.qq.com/s/77mbsD2cSqW8_NIMW6LE2Q
不论是语气还是人声,都有点中文原版的那个味道了。
当然,泰语版和西语版,也是手拿把掐:

△图片和音频均为AI生成
视频地址:
https://mp.weixin.qq.com/s/77mbsD2cSqW8_NIMW6LE2Q
不仅如此啊,这个语音模型是直接可以cover三十门外语的那种。
来听一下30种不同风格的“你好”:

如此好玩,还免费开源的国产语音模型,到底是何许AI是也?
不卖关子,它正是面壁智能联合OpenBMB开源社区、清华大学人机语音交互实验室新升级的VoxCPM 2。
整体看下来,除了多语种、多方言之外,VoxCPM 2在音色设计、音色可控和高表现力方面也是较为亮眼。
不少歪果仁在VoxCPM 2发布之后就立马去尝了下鲜,纷纷表示“自家语言的效果针不戳!”
而且在音质方面,市面一般是24000Hz,但VoxCPM 2这次直接拔高到了48000Hz(CD音质)!
这下子,游戏、动画、影视、有声书等领域的人可以说是有福了。
生成只需1秒钟的语音模型
开源的VoxCPM 2,我们现在就可以在在线体验的网站上体验了(地址见文末):
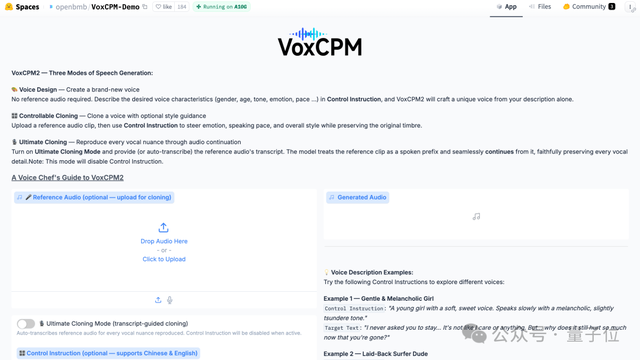
接下来,我们就一起手把手,搓一个东北话版的《火影忍者》。
首先在界面的左上角,我们上传一段宋小宝的原声片段,大概20秒左右:

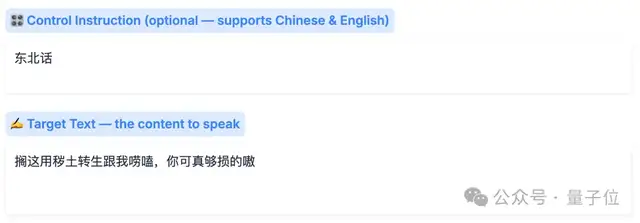
然后在它的下方,我们填一个“东北话”的指令,再把台词写进要合成的文本里,例如:
搁这儿用秽土转生跟我唠嗑,可真够损的奥。
最后点击下面的“Generate Speech”按钮,不到一秒钟的时间,宋小宝味儿的《火影》宇智波斑的台词就诞生了:

接下来,我们只需要配上一小段视频,齐活儿:
细心的小伙伴可能发现了,刚才宋小宝音频的demo里其实是有背景杂音的,但到视频里就没有了。
这其实是VoxCPM 2的参考音频降噪功能,只要勾选一下,声音就会变得清晰:

还有值得注意的是,视频里二代土影的声音,是没有上传任何参考音频的情况下生成。
如果你找不到合适的灵感,大可以让VoxCPM 2自由发挥。
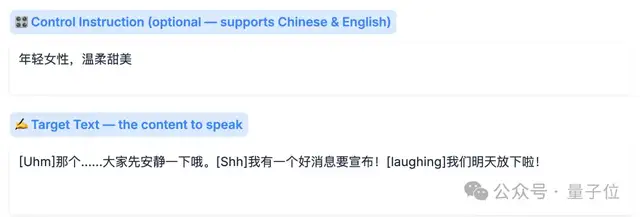
然后如果想克隆声音的质量有保证,建议上传的参考音频尽量大于等于5秒;以及你还可以在“Control Instruction”里面添加提示词,改变参考声音的情绪和语速等等。
(但克隆声音的时候,是不能改变性别的哦~)
除此之外,还有3个小细节:
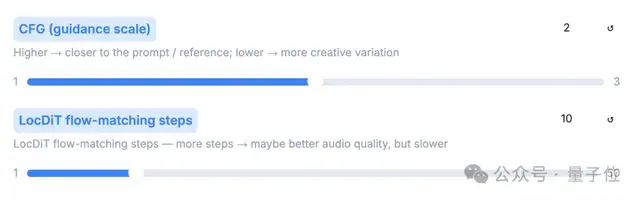
第一个是文本规范化,这是在你输入的台词里有日期、符号、阿拉伯数字等AI读不明白的内容时,你就可以点它,让AI读得规范起来。
第二个CFG Value,它的作用是用来控制AI的听话程度,数值越高就越听你的要求,反之,AI会自由发挥。
第三个就是LocDiT,设置它的步数越高,音频效果就会越好,但生成的速度就会变慢。
除此之外,台词中间停顿的音效,现在可以用[laughing](笑声)、[sigh](叹气)、[Uhm](嗯……)这些标签来控制:
总而言之,现在要玩儿逼真、有趣的声音,简直太简单了。
怎么做到的?
看到这里,肯定有不少的小伙伴要问了:
只有2B大小,还免费开源的语音模型,到底是怎么做到的?
来,咱们这就扒一波。
首先就是VoxCPM 2走了一条跟市面上大多数模型不太一样的路线——采用扩散自回归连续表征(Diffusion Autoregressive Continuous Representation)。
和市面上主流的Token-based传统方案不同的是,它是基于Tokenizer-Free的TTS系统来做的设计,通过端到端扩散自回归架构直接生成连续语音表征,实现了隐式语义-声学的解耦。
简单来说,传统方案在语音转换时极易出现信息损失,而这套技术能最大程度保留原始声音的声学细节、情感基调和方言特色。
这也就是它既能完美复刻周星驰配音的声色,又能把东北话、四川话说得地道入味的核心原因。
与此同时,这款模型的底气,还来自面壁智能深耕多年的高密度小模型技术壁垒。VoxCPM 2完全基于面壁智能自研的MiniCPM基座打造,延续了系列模型“小身板、大能量”的特质。
此前VoxCPM系列就已经在Hugging Face斩获超千点赞、5.5k+下载量,这次升级更是把多语种、高保真、音色可控等核心能力拉到了行业新高度。
更难得的是,VoxCPM 2不止开源了完整的模型权重,更提供了从一键上手到大规模部署的全套工具链,支持原生Torch推理、LoRA及全参数微调,还适配了多端UI扩展,上手使用变得超简单。
最后回到国产这个点。
放眼全球范围内,目前除了基座大模型牢牢占据了开源领先地位,在小模型、端侧模型上,中国公司也在持续领先。
体验地址:
https://voxcpm.modelbest.cn/
GtiHub地址:
https://github.com/OpenBMB/VoxCPM/
HuggingFace地址:
https://huggingface.openbmb.com/model/openbmb/VoxCPM2