
新智元报道
3月16日,大英百科全书联手韦氏词典,将OpenAI告上了法庭,指责其开发的ChatGPT存在多项版权侵权行为。
又一起针对OpenAI的法律诉讼。
两家机构联合对OpenAI提起诉讼。
原因在于,他们认为ChatGPT在生成回复时大量使用了他们的版权材料。
大英百科全书准备得尤为充分,不仅指控OpenAI未经授权使用其版权内容,还提出了多项具体侵权行为。
这是AI版权诉讼历史上首次尝试对整个生成过程提出全面质疑。
GPT-4能够精确复制大英百科全书的内容。
据报道,Britannica指出,GPT-4系统已经记住了其大量版权资料,并能够按需输出几乎完全一致的副本。
一字不差,没有任何改动。
这一技术现象得到了斯坦福大学和耶鲁大学研究团队的实验验证。

实验发现,从主流大模型中可以提取出高达96%的《哈利·波特》原文,这表明训练数据中的内容被模型以高度精确的形式再现。
大英百科全书拥有庞大的版权内容库,涵盖近十万篇在线文章、百科条目和词典释义,涉及科学、历史和文学等多个知识领域。
这些内容由专业编辑和学术专家花费数十年时间整理和积累而成。
在维基百科出现之前,这套体系一直被视为人类知识的标准索引。
查一次资料,也算侵权
OpenAI长期以来在版权问题上处于灰色地带。
过去的争论主要围绕是否使用他人内容进行模型训练构成侵权。
此次,大英百科全书的指控更为具体。
第一,未经许可抓取近十万篇文章用于模型训练。
第二,ChatGPT生成的回答中直接或部分复制了Britannica的内容,直接侵权。
第三,指控OpenAI在ChatGPT的RAG机制中使用了Britannica的文章。
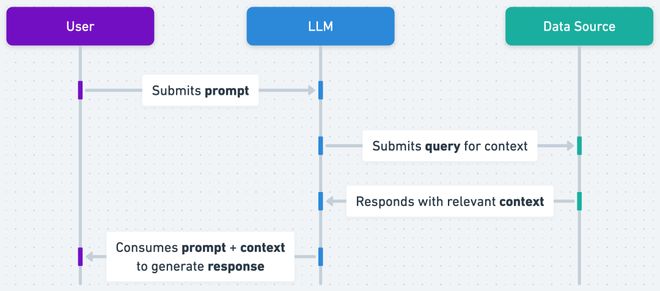
RAG机制使得ChatGPT能够实时检索最新信息。
大英百科全书认为,即使内容未进入训练集,只要出现在实时检索中,就被视为侵权。
这种观点前所未见,意味着不管是训练过程还是实时检索,只要未经授权使用版权内容,都将构成侵权。
大英百科全书还提出了Lanham Act商标侵权的指控。
它声称,ChatGPT有时会生成错误信息,并将其错误地归因于Britannica,损害其品牌信誉。
这不仅侵犯了版权,还损害了大英百科全书的品牌声誉。
同一问题的不同司法立场:德国判定侵权,英国则认为不侵权。
这是当前全球司法界争论最激烈的议题之一。
德国慕尼黑法院在GEMA诉OpenAI一案中认定,GPT-4和GPT-4o的模型权重中嵌入了歌词,构成版权侵权。

法院认为,只要能从模型权重中还原出作品,即构成侵权。
英国高等法院在Getty Images诉Stability AI一案中得出相反结论。

法院认为AI模型不是侵权副本,因为它只存储了学习到的模式,而非直接复制版权作品。
美国法院也在版权诉讼中面临类似的争议。
在Anthropic的案件中,法院认定将内容用作训练数据具有足够的转化性,可以适用合理使用原则。
但同时认定非法下载了数百万本书的行径构成违法。
大英百科全书的诉讼适用美国联邦法律。
目前尚无明确的司法先例确认用版权内容训练大型语言模型是否构成侵权。
如果法院认可实时检索也构成侵权,这将对整个AI行业产生深远影响。
早在2025年9月,大英百科全书就对Perplexity提起了版权和商标侵权诉讼,该案仍在审理中。
Perplexity是一家以RAG为核心产品的AI搜索公司。

大英百科全书先起诉Perplexity,似乎是为之后对OpenAI的诉讼做准备。
当前,版权纠纷在AI行业内全面升级。
《纽约时报》、Ziff Davis和十余家报纸先后对OpenAI提起诉讼。
The Intercept和US News & World Report也加入了诉讼队伍。

据统计,这是针对OpenAI的第63起版权诉讼。
OpenAI对相关置评请求未予回应。
在维基百科的冲击下,大英百科全书正面临新的挑战。
这次,它面对的是ChatGPT的挑战,后者通过生成替代内容来抢夺流量。
大英百科全书的这次行动,不仅是一次版权诉讼,更是传统知识权威在AI时代中的地位重估。
大英百科全书创建于1768年,是英文世界中最古老的百科全书品牌之一,象征着人类知识整理的传统。
它曾是纸质百科全书的绝对权威,被维基百科的崛起所冲击。
转型为数字订阅平台后,它凭借内容的可信度和专业性重新站稳了脚跟。

然而,ChatGPT的出现再次威胁到了它的地位。
这次,大英百科全书希望通过法律手段,重新划定AI生态中的版权边界。
诉状里有一句话:
一旦法院认可这种侵权论断,整个行业的实时检索管道都需要重新谈判授权。
所有以联网搜索和AI生成为核心产品的公司都将面临同样的问题。
250年的老牌百科全书,正在用法律行动划定AI的边界。
这条边界最终会画在哪里?2026年,我们或许能找到答案。
250年的老牌百科,正在用一份诉状,尝试给AI的边界划一条线。
这条线最终画在哪里?2026年,大概会有答案。
参考资料:
https://www.reuters.com/legal/litigation/encyclopedia-britannica-sues-openai-over-ai-training-2026-03-16/
https://techcrunch.com/2026/03/16/merriam-webster-openai-encyclopedia-brittanica-lawsuit/
https://the-decoder.com/encyclopedia-britannica-sues-openai-for-training-on-nearly-100000-articles-without-permission/
https://gizmodo.com/encyclopedia-britannica-sues-openai-over-ai-training-data-2000607770
https://news.bloomberglaw.com/ip-law/britannica-merriam-webster-accuse-openai-of-copying-their-works
https://chatgptiseatingtheworld.com/wp-content/uploads/2026/03/Encyclopedia_Britannica_Inc-v-OpenAI-COMPLAINT-Mar-13-2026.pdf
https://www.aol.com/articles/encyclopedia-britannica-sues-openai-over-141324436.html