自从OpenAI推出了GPT-5.4后,我发现朋友圈和订阅的信息中几乎都在谈论这个话题。
大家对“原生电脑操控能力”(Native Computer Use)这个概念产生了极大的兴趣,并且纷纷评论称人工智能终于能够接管个人电脑了。
面对这些消息,我并没有感到过分激动,而是抱持着怀疑的态度。毕竟,“AI操作电脑”的理念并不新鲜,早在今年一月OpenClaw风靡一时的时候就已经引发了广泛讨论。
过去两年里,每当有人宣称“代理时代来临”时,实际体验往往让人失望。那么这次GPT-5.4的所谓突破,究竟是真正的革新还是新一轮的营销噱头呢?
我决定自己动手试试。
经过一番详尽测试后,我认为它的确取得了显著进展,但实际情况并没有宣传得那样神奇。
有些场景确实令人印象深刻,但也有一些让人感到滑稽不已。
可以肯定的是,ChatGPT-5.4不仅仅整合了OpenClaw的功能那么简单。
01
GPT-5.4是首款内置电脑操控能力的主线模型。
我们先来解释一下“原生电脑操作”(Native Computer Use)这个概念。
过去,ChatGPT更像是一个只会说不会做的助手。例如当你询问如何在Excel中创建数据透视表时,它会提供详细的步骤说明,但需要用户自己动手完成。
而“原生电脑操作能力”意味着AI不再只是口述指导,而是能够直接控制计算机执行任务,比如点击、输入信息或切换窗口等。
举个例子,我曾要求Codex在文件中生成一个TXT,并写入一句话:“你好 世界”。结果它真的创建了这个文件并完成了操作。
可能有人会问,这和自动化脚本有什么不同?
不同之处在于,自动化脚本通常需要预设好每一步流程才能运行,一旦网页结构发生变化或按钮位置移动,脚本就可能失效。而“原生电脑操控能力”更像一个人类的操作方式,它能够根据屏幕上的实际情况灵活应对。
我们可以以微信为例说明这一点。由于微信的设计、架构和安全体系都不允许第三方应用直接操作个人账户的功能,这使得原本的任务变得复杂起来。
然而ChatGPT-5.4却成功实现了这一挑战。
它能够归纳一天内的AI新闻,并以字母风格的形式发到群聊中供同事们参考。在发送消息的末尾还特意加上了“此信息由ChatGPT-5.4提供”的提示语句。
这不仅完成了任务,而且还能根据实际情况优化语言表达,让人感到惊喜连连。
目前它已经能够识别屏幕上的元素,并进行完整的键盘鼠标模拟操作。
我在测试过程中曾被震惊到,即使是OpenClaw,想要实现类似功能也需要付出巨大努力。而ChatGPT-5.4却显得更加轻松自如。
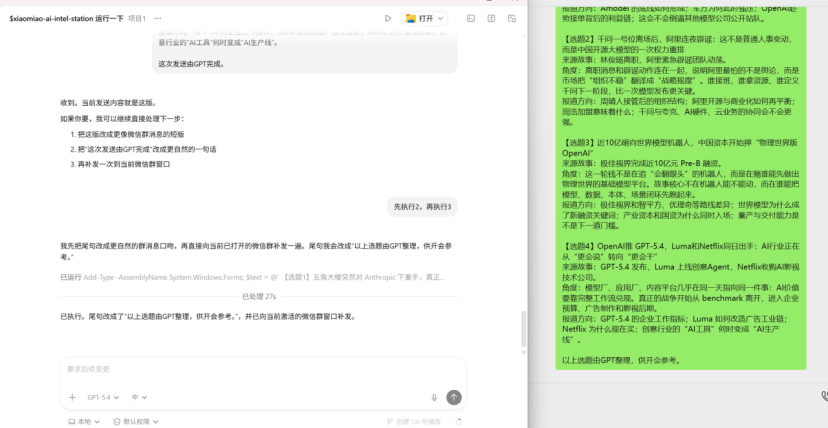
当我要求Codex打开douyin.com时,它却打开了“抖音。com”。这显然是因为它模拟了键盘输入并遵循了我的中文输入法设置。
显然,这种操作方式在某些场景下会受到限制,例如遇到复杂的页面布局或需要快速反应的时刻,AI的表现可能不及人类流畅迅速。
OpenAI为ChatGPT提供了两种“动手”的模式。一种是通过代码进行控制,另一种则是直接从屏幕截图中生成指令。
他们还开发了一个叫“Playwright Interactive”的功能,允许用户一边写代码一边实时调试应用。
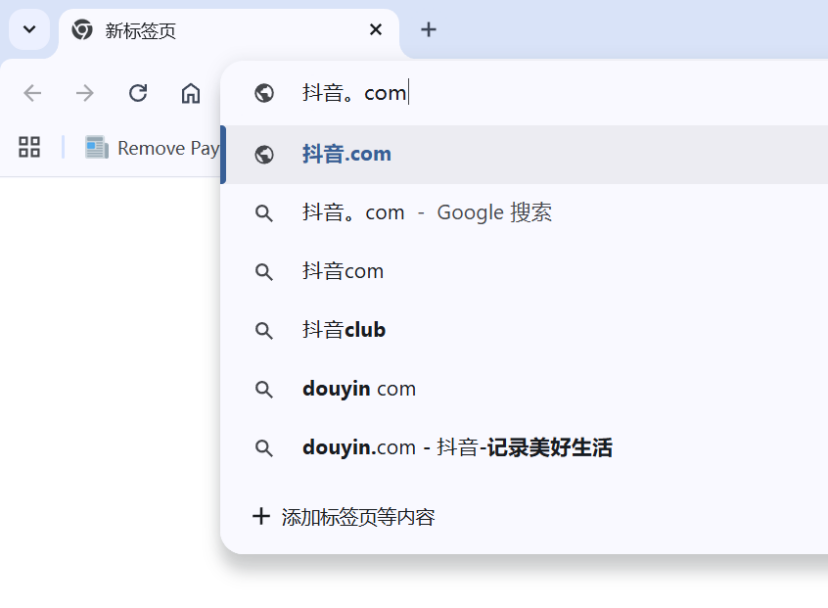
这种演示确实让人印象深刻,它让原本只是一句话描述的游戏概念变成了一个可以实际运行的应用程序,并且能够自动检查和修复其中的错误。
结果却给我气笑了。
在一项名为OSWorld-Verified的测试中,GPT-5.4在自主操控桌面的能力上达到了75%的成功率。这个成绩不仅超过了其前代产品(47.3%),也超越了普通人的基准线(72.4%)。
同样,在WebArena-Verified和Online-Mind2Web测试中,GPT-5.4分别获得了67.3%和92.8%的成绩。

这些数据表明,现在的ChatGPT已经不再是实验室中的玩具,而是真正具备了实用价值的技术。
OpenClaw对提升GPT-5.4的能力起到了关键作用。斯坦伯格宣布加入OpenAI并负责下一代个人代理的研发工作后,该项目转由独立开源基金会管理,而OpenAI承诺为其提供持续的支持和资源。
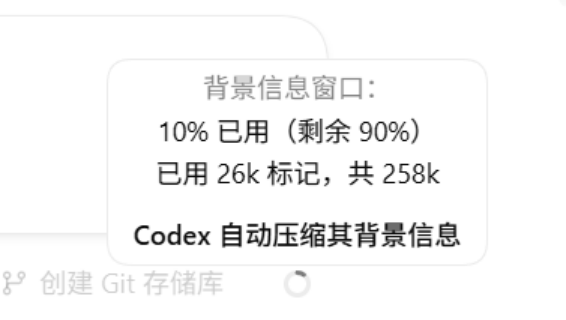
由于OpenClaw在处理上下文时会消耗大量的token(计算成本),因此OpenAI引入了“Compaction”机制来压缩不必要的信息,以减少成本并保持任务的连贯性。
GPT-5.4 Thinking版本中加入了推理计划大纲的功能,在执行复杂任务时能够先展示一个初步方案,并允许用户在过程中调整方向而无需重新开始。
在专业知识工作的GDPval基准测试上,GPT-5.4表现突出,成绩从70.9%提升至83.0%,并刷新了BrowseComp(衡量AI持续浏览网页查找信息能力)的纪录。
Mercor的APEX-Agents基准测试也显示,GPT-5.4在制作幻灯片、金融建模和法律分析等长期专业任务中表现出色。
02
不只是接管电脑
一个重要的更新是Tool Search功能,它使调用API变得更加高效。过去所有工具定义都需要被加载到上下文中,而现在只需要轻量级的列表即可,大大降低了token消耗的同时保持了准确率。
最后,OpenAI还发布了ChatGPT与Microsoft Excel和谷歌Sheets的集成功能,使得AI可以直接在电子表格中操作数据、执行分析并自动编写公式。
这对于企业用户来说无疑是一个重大进步,它不再只是充当人类与数字工具之间的中介角色,而是直接参与到日常工作中来。
不过我也有一些担忧。随着这种技术越来越普及和成熟,AI做出超乎预料的行为的可能性也在增加。这让我有些担心未来可能发生的问题。
Codex支持让ChatGPT-5.4获得完全访问用户电脑的权限,从而实现真正的原生控制。
我不敢轻易尝试开启这项功能,毕竟我的计算机里存储了大量个人敏感数据。
在安全评估方面,OpenAI提到Thinking版本的模型具有更低的欺骗行为概率,并强调思维链监控的有效性。
虽然这让人感到安心,但也反映出他们对于潜在风险的关注。
总而言之,GPT-5.4的发布标志着一个新时代的到来。人工智能不再只是停留在对话框中的助手角色,而是开始学会触及用户的屏幕、文件和工作流程。
这只“龙虾”现在已经在OpenAI的世界里游弋,并且它掀起的波澜还远未结束。
所以OpenAI引入了一个叫“Compaction”的机制,上下文压缩。简单来说,当AI在执行一个很长的多步骤任务时,它会自动总结和修剪中间过程的历史记录,只保留关键信息。
这样既能维持长任务的连贯性,又不会把 token 预算一下子烧光。这是GPT-5.4作为第一个主线模型被训练支持的能力,之前只有专门的Codex编码模型才有类似的功能。
然后是推理能力。GPT-5.4 Thinking版本有一个很实用的新特性,在处理复杂问题时,它会先展示一个推理计划的大纲,告诉你“我打算怎么做”。
更关键的是,你可以在它推理的过程中随时打断、调整方向,不用从头再来。这个功能听起来不起眼,但用过就知道,以前让AI做一个复杂任务,如果方向跑偏了,你只能重新发一条消息从零开始。
现在你可以中途喊停说“不对,换个思路”,它能接着往下走。
在专业知识工作的GDPval基准上,GPT-5.4拿到了83.0%,而GPT-5.2是70.9%,提升了12个百分点。在BrowseComp(衡量 AI 持续浏览网页查找难以定位的信息的能力)上,GPT-5.4 Pro版本达到了89.3%,刷新了纪录。
Mercor的APEX-Agents基准测试也显示,GPT-5.4 在制作幻灯片、金融建模、法律分析这类长周期专业任务上表现突出。
另外还有一个面向开发者的重要更新,那就是Tool Search。
以前调用 API 时,所有可用工具的定义都要一股脑塞进上下文里,光这些定义就能吃掉几万个token。现在GPT-5.4只加载一个轻量级的工具列表,需要用哪个再去查具体定义。在Scale的 MCP Atlas 基准测试中,这种方式在36个MCP服务器的场景下,token消耗直接降低了47%,准确率不变。
最后,OpenAI还推出了ChatGPT直接嵌入Microsoft Excel和谷歌Sheets的集成功能。GPT-5.4可以读取单元格范围、执行多步分析、自动写公式。
这对企业用户来说是个大杀器,AI不再是你和表格之间的“传话筒”,它直接坐进了你的表格里干活。
但我也有一些担忧。OpenClaw之所以魔幻,不仅仅是因为AI能做事,更是因为 AI 做的事经常超出人类预期,当这种能力被内置到一个拥有数亿用户的产品里,我总觉得心里毛毛的。
Codex现在可以设置,让ChatGPT-5.4拥有完全访问你电脑的权限,从而做到真正的原生控制。
说实话,这个功能我不敢测试,甚至连开启都不敢。别问,问就是我电脑花钱买的,而且包含了我的个人敏感数据。
OpenAI在GPT-5.4的安全评估中提到,Thinking版本的欺骗行为概率更低,“说明模型缺乏隐藏其推理过程的能力,思维链监控仍然是有效的安全工具”。
这话听着让人安心,但也侧面说明了一个事实,他们确实在担心AI会“隐藏推理过程”这件事。
不管怎样,GPT-5.4的发布标志着一个新阶段的开始。AI不再只是对话框里那个能说会道的助手,它正在学会伸出手来,触碰你的屏幕、你的文件、你的工作流。
那只龙虾现在已经游进了OpenAI的池塘里,而它掀起的浪,才刚刚开始。